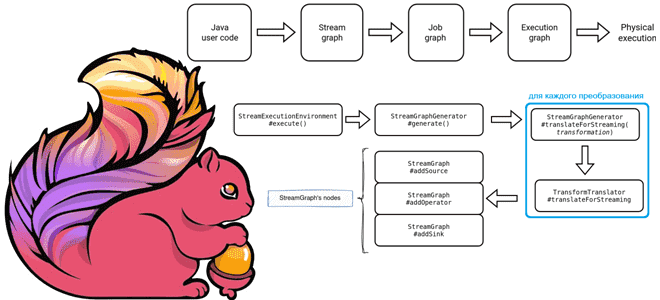
Как планируются и исполняются задания Apache Flink: от пользовательского Java-кода до физического исполнения, а также отслеживание статуса задания в JobManager. Подробности преобразований с примерами кода. 3 этапа преобразования задания Apache Flink Задание Apache Flink проходит несколько этапов перед своим физическим выполнением: сперва пользовательский код преобразуется в потоковый граф (Stream Graph);...
Почему хранить состояния Flink-приложений лучше на локальных SSD-диски, а не на твердотельных накопителях с удаленной файловой системой NFS или HDFS, зачем отключать блочный кэш RocksDB и как настроить параллелизм заданий. Проблемы сохранения состояния в RocksDB и способы их решения Как мы уже упоминали здесь, key-value хранилище RocksDB является самым популярным...

24 октября 2023 года вышел очередной релиз Apache Flink. Знакомимся с главными новинками популярного Big Data фреймворка для разработки потоковых stateful-приложений: JDBC-драйвер для SQL-шлюза, хранимые процедуры для коннекторов, расширенная поддержка SQL, динамическое масштабирование с REST API и RocksDB, улучшение пакетных операций, а также другие полезные фичи Apache Flink 1.18. Улучшения...

Продолжая недавний разговор про настройку конвейеров из Flink-приложений, сегодня рассмотрим, почему важна локальность данных, как избежать узких мест в приемниках потоковых данных и чем хорош HybridSource для объединения гетерогенных источников. Обеспечьте локальность данных Хотя распределенные системы обладают большим потенциалом по сравнению с локальными, позволяя обрабатывать больше данных, вычисления не происходят...
Для чего разработчику Flink-приложения инструменты профилирования, и почему надо избегать сериализации Kryo и динамической загрузки классов. Используйте инструменты профилирования Разработка и отладка высоконагруженных приложений требует специальных средств, позволяющих понять причины их медленной работы и повысить производительность. Такой анализ работы приложение называется профилированием и выполняется с помощью специальных средств – инструментов...
Зачем настраивать конфигурацию конвейера Flink-приложений в зависимости от рабочей нагрузки и как это сделать: примеры и рекомендации. 3 вида рабочей нагрузки в потоковых конвейерах Конвейер потоковой передачи событий может реализовывать различные сценарии: обратная засыпка (backfilling), когда конвейер потребляет все исторические данные, считывая все сообщения, доступные во входных источниках, пока не...
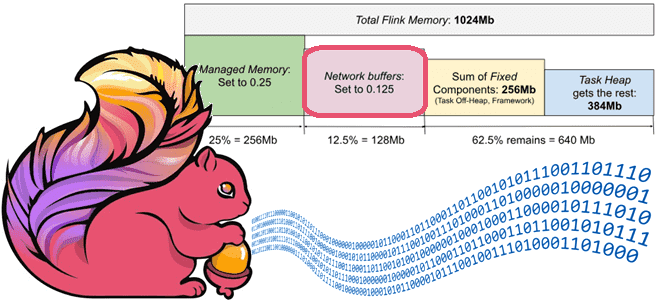
Как Apache Flink обеспечивает стабильно высокую пропускную способность потоковой обработки данных с помощью сетевых буферов и контрольных точек, каковы возможности и ограничения этих механизмов и какие конфигурации надо настроить для их эффективного использования. Зачем Apache Flink нужны сетевые буферы Каждая запись в Flink отправляется следующей подзадаче вместе с другими записями...

Зачем Apache Flink очередной API для создания распределенных приложений с отслеживанием состояния, чем он полезен и при чем здесь Kubernetes: ликбез по Stateful Functions. Apache Flink Stateful Functions Stateful Functions в Apache Flink – это API, который упрощает создание распределенных приложений с отслеживанием состояния с помощью среды выполнения, созданной для...

Из-за чего приложения Flink работают быстрее Spark: разница в моделях обработки данных, управлении памятью, методах оптимизации, дизайне API и личный опыт использования. Apache Flink vs Spark: сходства и отличия Apache Spark и Flink считаются наиболее популярными фреймворками разработки распределенных приложений в области Big Data. Они достаточно похожи, что мы ранее...
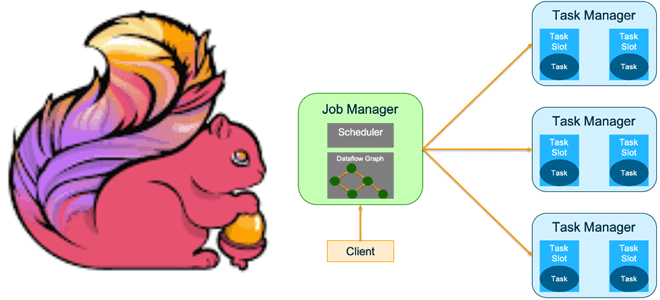
Какие режимы развертывания заданий поддерживает Apache Flink и чем они отличаются. Достоинства и недостатки режима сеанса и режима приложения, а также варианты использования. Особенности развертывания приложения Apache Flink Режим развертывания определяет, с каким уровнем изоляции ресурсов задание Flink будет выполняться в кластере. Напомним, выполнение задания Apache Flink включает 3 объекта:...
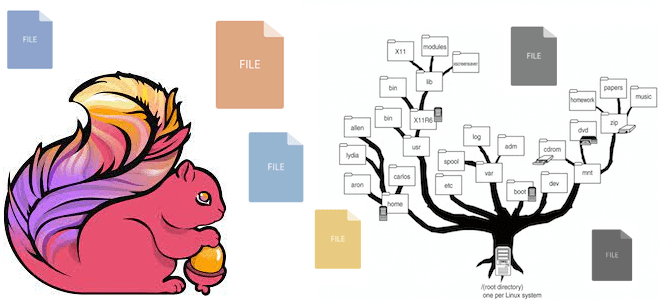
Какие файловые системы поддерживает Apache Flink: средства взаимодействия с файлами, хранящимися локально или в объектных хранилищах HDFS, S3 и GCS. Особенности работы с файловыми системами в Apache Flink Apache Flink имеет собственную абстракцию файловой системы через класс org.apache.flink.core.fs.FileSystem. Эта абстракция обеспечивает общий набор операций и минимальные гарантии для различных типов...

Что такое потоковое обогащение данных, зачем это нужно и как оно реализуется в Apache Flink. Проблемы и решения предварительной загрузки справочных данных в память, синхронного и асинхронного поиска в источнике по каждой записи и организация потоковой передачи событий. 3 способа загрузить эталонные (справочные) данных в Apache Flink для обогащения потока...
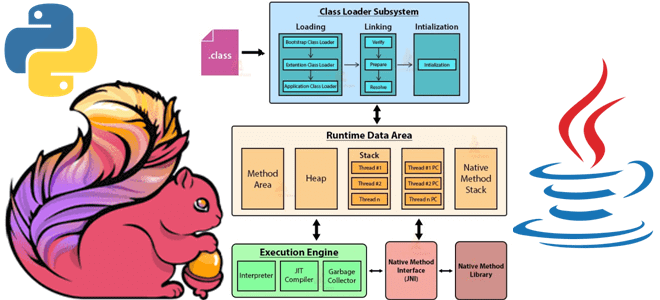
Как и большинство Big Data фреймворков, Apache Flink имеет Python API, позволяя разработчикам высоконагруженных потоковых приложений писать код на этом популярном языке программирования. Однако, Flink-задание выполняется в JVM, поэтому сам фреймворк транслирует Python-код в Java. Разбираемся, в чем особенности этого многоступенчатого процесса. Из Python в Java: как устроен API PyFlink...

Что такое спекулятивное выполнение заданий в Apache Flink, какой планировщик его поддерживает, какие конфигурации нужно настроить для его эффективного использования и зачем при этом переопределять поведение генератора разделений потокового источника данных. Что такое спекулятивное выполнение заданий Apache Flink Распределенная природа Apache Flink приводит к тому, что приложения, созданные с помощью...
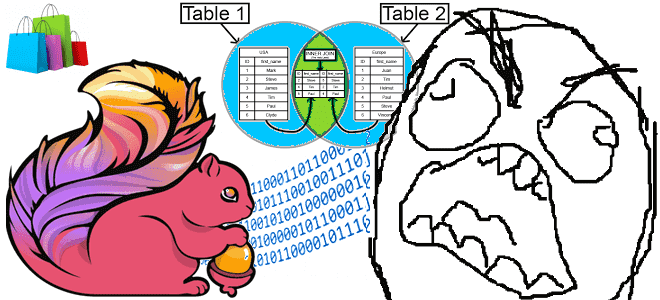
Почему запросы Flink SQL перестают работать эффективно при больших объемах несбалансированном распределенных данных и как это исправить с помощью мини-пакетной агрегации. Что такое MiniBatch, как это работает и чем может опасно. Перекос данных по ключу группировки в Apache Flink Flink SQL — это мощный инструмент, объединяющий пакетную и потоковую обработку...
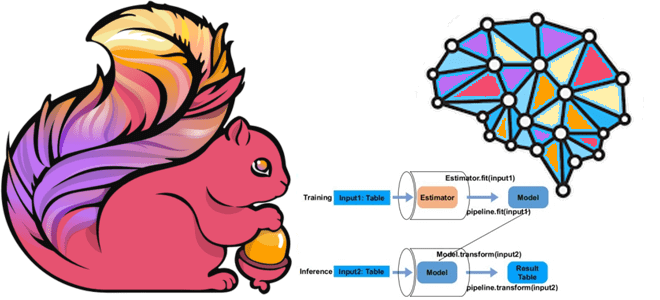
Как построить конвейер машинного обучения с помощью библиотеки Flink ML, из каких компонентов она состоит и как работает, а также что позволяет объединить алгоритмы потоковой обработки данных Apache Flink с ML-моделями. Что такое Flink ML Помимо MLeap, библиотеки сериализации для моделей машинного обучения, Apache Flink также включает Flink ML —...
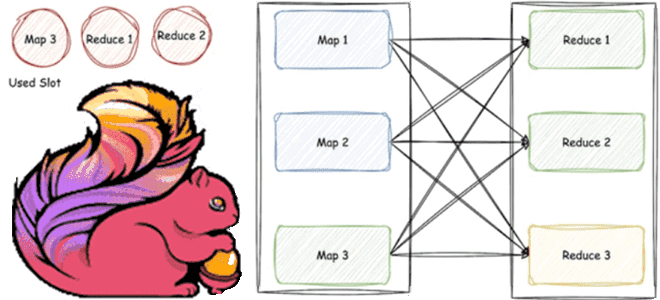
Что не так с планированием задач shuffle-операций, какие проблемы пакетной обработки данных устраняет введение гибридной перетасовки в Apache Flink 1.16 и как работает этот режим Hybrid Shuffle. Что такое режим гибридного перемешивания в Apache Flink В версии Apache Flink 1.16, о которой мы писали здесь, был впервые представлен режим гибридной...

Недавно мы писали про источники данных Apache Flink. Сегодня рассмотрим, как создать и протестировать собственный источник данных для их обработки в распределенном приложении. Создание своего источника данных в Apache Flink Напомним, источник данных в Apache Flink состоит из трех основных компонентов: Split, SplitEnumerator и SourceReader. Splits — это часть данных,...

Сегодня рассмотрим, как написать и запустить в Google Colab свое Python-приложение считывания данных из топика Kafka с помощью коннектора FlinkKafkaConsumer из библиотеки pyflink.datastream.connectors и почему заставить его работать оказалось не так просто. Использование FlinkKafkaConsumer для доступа к Kafka из Flink приложения Недавно я показывала, как написать PyFlink-скрипт считывания данных из...
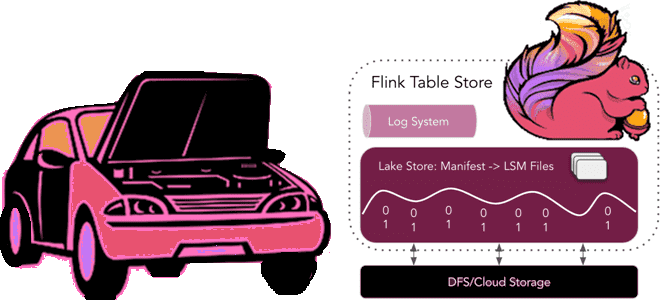
Год назад мы уже писали, как в Apache Flink появились табличные хранилища и зачем они нужны. Сегодня заглянем под капот Flink Table Store, познакомившись со структурой файлов и каталогов. Архитектура и принципы работы Flink Table Store Поскольку Apache Flink объединяет пакетную обработку данных с потоковой, для работы этого универсального stateful-механизма...