
Школа Больших Данных проводит еще один бесплатный митап для архитекторов платформ данных, инженеров данных, разработчиков, DevOps-, DataOps-инженеров и просто интересующихся о модели Dataflow, API Apache Beam, а также паттернах управления приложениями распределенной обработки данных на Kubernetes. Apache Beam – унифицированный API с открытым исходным кодом, реализующий модель Dataflow, предоставляет единый...

Школа Больших Данных проводит очередной бесплатный митап для архитекторов платформ данных, инженеров данных, разработчиков, DevOps-, DataOps-инженеров и просто интересующихся о моделях и ключевых паттернах управления распределенными приложениями Apache Spark и Apache Flink на Kubernetes. Apache Spark и Flink - это популярные Big Data фреймворки с открытым исходным кодом для распределённой...

2 августа 2024 года вышел свежий релиз Apache Flink. Знакомимся с главными новинками выпуска 1.20 для упрощения потоковой обработки данных в мощных управляемых конвейерах: новые материализованные таблицы, единый механизм слияния файлов для контрольных точек, улучшения DataStream API и пакетных операций. Улучшения Flink SQL Начнем с новинок Flink SQL, одной из...
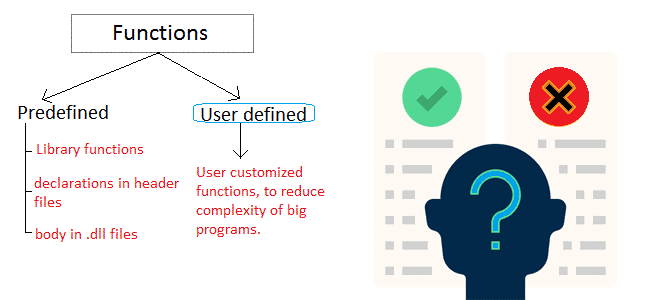
Почему пользовательские функции лучше применять как можно реже, каковы их возможности и ограничения: краткий обзор особенностей разработки и эксплуатации UDF в Apache Spark SQL, ksqlDB, Flink SQL, Greenplum и ClickHouse. Чем полезны и опасны пользовательские функции в обработке больших данных? Пользовательские функции (User-Defined Functions, UDF) позволяют разработчику расширить возможности фреймворка,...
Что такое rich-функции в Apache Flink, зачем они нужны, чем отличаются от обыкновенных UDF и как с ними работать: простой пример на PyFlink с запуском в Google Colab. Rich-функции в Apache Flink Будучи очень мощным фреймворком для разработки распределенных потоковых приложений, Apache Flink не только предоставляет широкий набор stateful-функций, но...
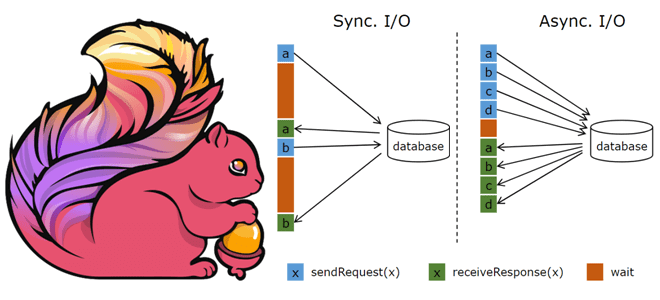
API асинхронного ввода-вывода в Apache Flink и как его использовать для асинхронной интеграции данных из внешней системы с потоком событий. Основы асинхронной обработки в Apache Flink Обогащение потоков данных информацией из внешних систем является довольно сложным кейсом из-за необходимости синхронизировать скорость поступления событий с задержкой доступа к внешнему источнику. При...

Как расширить возможности Apache Flink с помощью дополнительных плагинов: подключение внешних ресурсов и обогащение отказов пользовательскими метками. Разбираемся с продвинутыми настройками для эффективной эксплуатации фреймворка. Внешние ресурсы Apache Flink Помимо процессора и памяти, многим рабочим нагрузкам также требуются другие ресурсы, например, графические процессоры для глубокого обучения. Для поддержки внешних ресурсов...
Практическая демонстрация потокового SQL-конвейера, который преобразует данные, потребленные из Apache Kafka, и записывает результаты в Elasticsearch, используя Debezium-коннекторы и задания Apache Flink в облачной платформе Decodable. Потребление сообщений из Apache Kafka Я уже показывала пример интеграции Apache Kafka и Elasticsearch с помощью sink-коннектора, а также конвейер с ClickHouse Cloud. Сегодня...

Зачем устанавливать максимальный для каждого задания Apache Flink, для чего stateful-оператору пользовательский UUID, как выбрать подходящий бэкенд хранения состояний, от чего зависит оптимальный интервал создания контрольных точек и где настраивается высокая доступность менеджера заданий. 5 главных настроек перед запуском Flink-приложения в производственное развертывание Перед запуском приложения Apache Flink в производственное...
Как с Apache Flink настроить локальную службу OLAP, а также развернуть ее в рабочей среде производственного кластера: архитектура, принципы работы и параметры конфигурации для сложных аналитических сценариев. Служба Flink OLAP: архитектура и принципы работы Идея выделить в Apache Flink механизм OLAP для анализа данных в потоковом хранилище появилась еще год...

18 марта 2024 года вышел очередной релиз Apache Flink. Знакомимся с его главными новинками и разбираемся, чем они полезны для потоковой обработки больших данных: ключевые изменения выпуска 1.19 для разработчика stateful-приложений. Динамическая настройка параллелизма Выпуск Apache Flink 1.19 можно назвать значимой вехой, поскольку он не только включает новые функции, улучшения...

Как с помощью Flink SQL организовать потоковую агрегацию данных из таблицы PostgreSQL: знакомство с API таблиц в Ververica Cloud на практическом примере. API таблиц Ververica Cloud: создаем внешние источники и приемники данных Как я недавно рассказывала, немецкая фирма Ververica создала высокопроизводительный облачный сервис для обработки данных в реальном времени на...
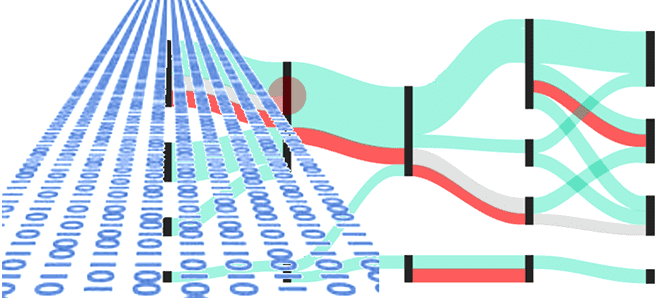
Чем пакетная парадигма обработки данных отличается от пакетной и как она реализуется на практике: принципы работы и воплощение в Big Data на примере Apache Spark, Kafka и Flink. Еще раз о разнице потоковой и пакетной парадигмы обработки данных Пакетная обработка и потоковая обработка — это две разные парадигмы обработки данных....
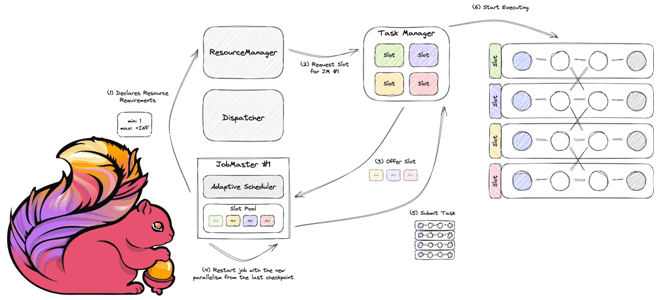
Как работает планировщик заданий в Apache Flink, чем разные реализации Scheduler отличаются друг от друга, и каковы преимущества адаптивных планировщиков. Как Apache Flink планирует выполнение заданий клиентской программы Архитектура Apache Flink, которую мы рассматривали здесь, включает несколько компонентов. Одним из них является планировщик заданий, которые отправляются клиентским приложением в диспетчер...

Что такое Ververica Runtime Assembly, чем GeminiStateBackend лучше RocksDB и еще несколько отличий коммерческого облачного решения от открытого Apache Flink. Что такое Ververica Cloud и при чем здесь Apache Flink Технологии с открытым исходным кодом развиваются намного быстрее при поддержке крупных корпораций. Например, компания Confluent продвигает Apache Kafka, Astronomer –...
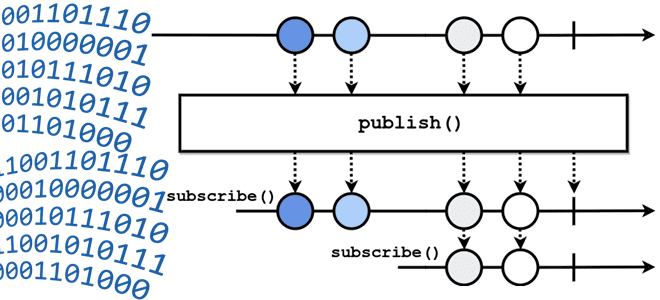
Что означает термин backpressure и зачем создавать обратное давление в streaming-системах: разбираемся с методами управления пропускной способностью потоковой передачи событий на примере Apache Kafka, Flink, Spark и NiFi. Что такое обратное давление: backpressure в конвейерах потоковой обработки данных Понять, как работает сложная концепция, проще всего на простых примерах. Это общее...

В конце декабря принято строить планы на следующие 12 месяцев. Посмотрим, что разработчики Apache Flink обещают реализовать в релизе 2.0, который должен выйти к концу 2024 года. Внедрение многоуровневой системы хранения состояний В Apache Flink 2.0 будет улучшена система управления хранилищем состояния путем перехода к полностью разделенной архитектуре хранения и...
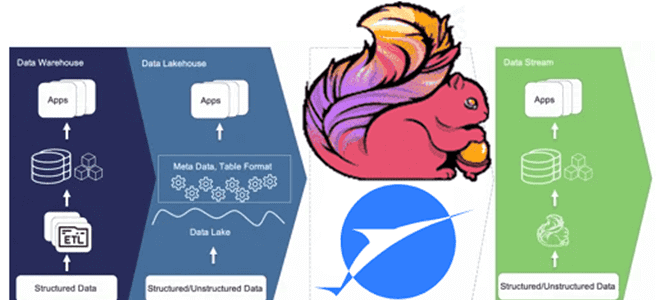
Что не так с архитектурой данных Lakehouse, зачем разработчики Apache Flink создали на основе табличного хранилища новую дата-платформу, чем хорош подход Streamhouse и как устроен Apache Paimon. Что такое архитектура данных Streamhouse Не успели дата-архитекторы освоиться с Lakehouse – архитектурой данных, которая объединяет преимущества хранилищ и озер данных, комбинируя масштабируемость...
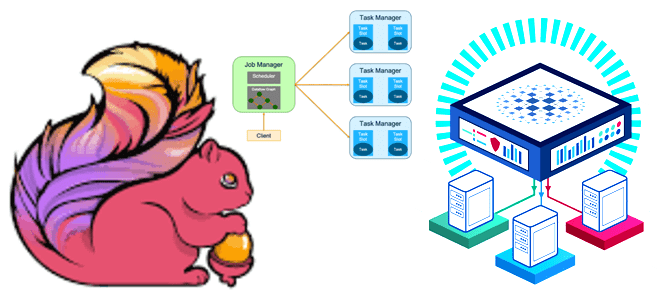
Как работает Flink-приложение, из каких компонентов состоит распределенный кластер и как сделать его отказоустойчивым. Архитектура и принципы работы высокой доступности Apache Flink. Архитектура Flink-приложения: ключевые компоненты и связь между ними Перед тем, как погружаться в средства обеспечения высокой доступности Flink-приложения, вспомним базовые принципы его работы. Сам по себе Apache Flink...
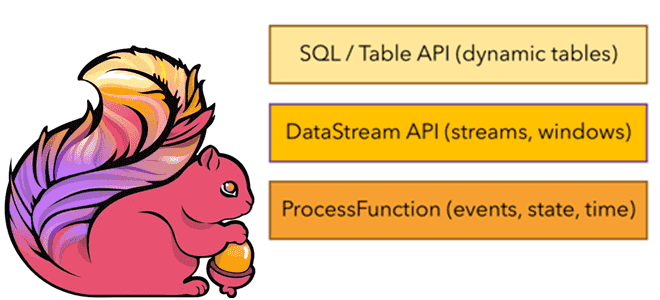
Какие возможности Apache Flink предоставляет разработчику и как их использовать: краткий обзор существующих API и потоковых примитивов. Потоковые примитивы и низкоуровневый API Будучи популярным фреймворком для stateful-вычислений над неограниченными и ограниченными потоками данных, Apache Flink предоставляет несколько API на разных уровнях абстракции и предлагает специальные библиотеки для различных сценариев. На...