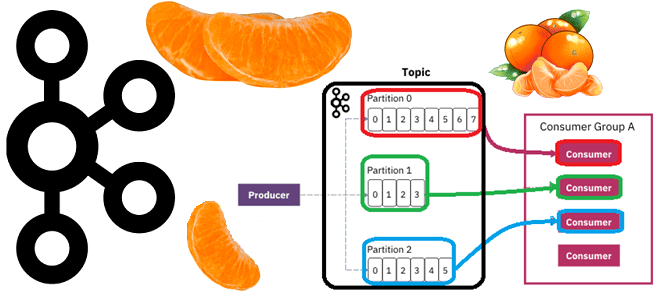
Почему раздел называется единицей параллелизма и как определить оптимальное число разделов в топике Apache Kafka в зависимости от количества потребителей и вариативности их поведения, разницы пропускной способности публикации и потребления сообщений, семантики партиционирования, толерантности к упорядоченности событий и ресурсных возможностей узла кластера. Что учитывать при разделении топика Apache Kafka Хотя...

Что такое гонка данных, почему она опасна в ETL-заданиях и как ее избежать: зачем разделять задания репликации в RAW-слой хранилища от их преобразования и сохранения в Transformed-слое DWH перед созданием витрин данных для BI-приложений. Что такое гонка данных в дата-инженерии Одна из главных особенностей распределенных систем – это задержка между...
29 января 2024 года вышла очередная веха 2-ой версии Apache NiFi, которая включает ряд новых функций и существенных обновлений зависимостей, а также несколько критических изменений. Рассмотрим самые интересные из них. Новые процессоры Apache NiFi 2.0.0-M2 С точки зрения управления версиями, веха рассматривается как некоторое значимое обновление, контрольная точка, меняющая дальнейшее...
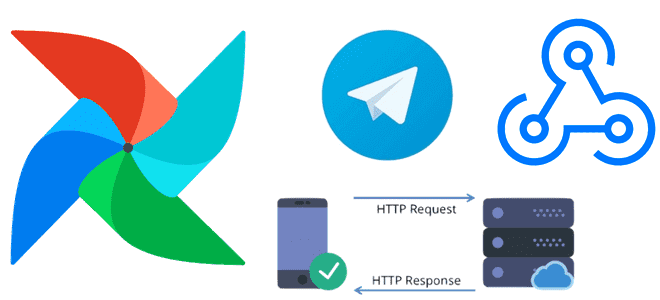
Сегодня я покажу, как проверить доступность веб-сайта с помощью http-хука в Apache AirFlow и отправить результаты проверки в Телеграм-бот. Еще раз про хуки и соединения Apache AirFlow Доступность системы является ключевым свойством информационной безопасности. Проверить, что веб-сервис доступен, можно по статусу HTTP-ответа на GET-запрос. Чтобы делать такую проверку периодически, т.е....
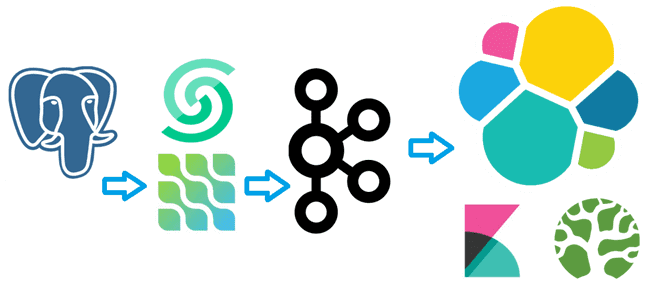
Недавно я писала, как с помощью source-коннектора Debezium организовать потоковый захват изменения данных из таблицы PostgreSQL путем публикации CDC-событий в Apache Kafka. Продолжая эту тему, сегодня покажу пример визуализации аналитики этих данных в Kibana, предварительно загрузив их в Elasticsearch с sink-коннектором Aiven. Постановка задачи и проектирование конвейера Как обычно, в...
Зачем менять базу данных метаданных в производственном развертывании Apache AirFlow и как это сделать: пошаговое руководство для дата-инженера с примерами и рекомендациями. 5 шагов перехода от SQLLite к PostgreSQL: миграция базы данных метаданных Apache AirFlow Чтобы планировать и запускать конвейеры обработки данных, Apache AirFlow хранит сведения о задачах, DAG, исполнителях,...

Зачем ограничивать доступ к папке с DAG и как это сделать: категории и роли пользователей в Apache AirFlow, способы входа в систему и конфигурации для настройки прав. Категории и роли пользователей Apache AirFlow Поскольку основным источником угрозы почти для любой информационной системы являются люди, при разработке методов обеспечения безопасности надо,...
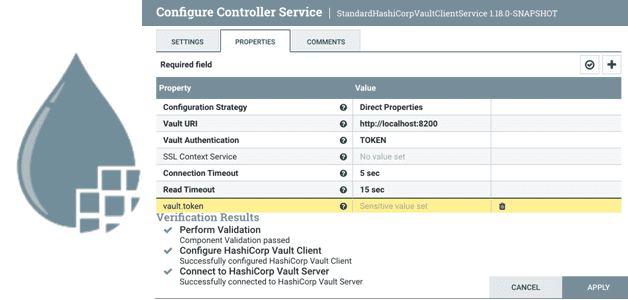
Что такое Controller Service в Apache NiFi и как дата-инженеру создать собственный набор настроек для совместного и повторного использования в потоковом конвейере обработки данных. Что такое Controller Service в Apache NiFi Apache NiFi реализует потоковую парадигму обработки информации, выполняя ETL-операции над FlowFile с помощью обработчиков, называемыми процессорами. Если какие-то процессоры...
Сегодня я покажу на практическом примере, как реализовать потоковый захват изменения данных из таблицы PostgreSQL и их репликацию в Apache Kafka с помощью Debezium. Создаем и настраиваем свой коннектор на платформе Upstash. Постановка задачи Паттерн захвата измененных данных (CDC, Change Data Capture) является одним из самых распространенных в инженерии данных....

Как спроектировать DAG и выбрать способ обмена данными между задачами, где определить подключения и запросы к БД и что поможет избежать ада Python-зависимостей при использовании Apache AirFlow. Сегодня я расскажу своем личном опыте наступания на грабли при работе с этим оркестратором batch-процессов и уроках, которые из этого вынесла. 5 советов...

Что необходимо реализовать в собственном процессоре, написанном на Python, чтобы запускать его в Apache NiFi. Классы и методы для настройки свойств, а также отношения и состояния жизненного цикла. Классы и методы для настройки свойств Предустановленные обработчики данных или процессоры (processor) Apache NiFi, написанные на Java, можно настроить прямо в GUI,...

Продолжая разговор про рассмотренные в прошлой статье принципы взаимодействия процессов Python с Java, на которой написан Apache NiFi, сегодня разберем, как использовать это на практике. Пишем свои процессоры, используя классы FlowFileTransform и RecordTransform. Python-процессор Apache NiFi на базе FlowFileTransform Хотя Apache NiFi предоставляет более 300 процессоров для вычислительных операций и...
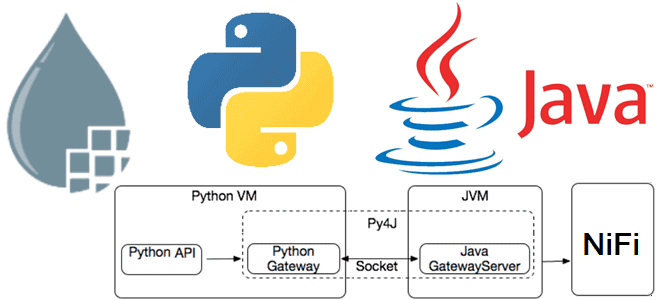
Недавно мы писали про Nifi-Python-Api —клиентский SDK, поддерживающий Python для работы с Apache NiFi. Сегодня на примере разработки процессоров более подробно разберем принципы взаимодействия процессов Python с Java, на которой написан Apache NiFi. Принципы работы Python-кода в Java-среде Apache NiFi Поскольку Apache NiFi написан на Java, именно этот язык предпочтителен...
Большинство ETL-конвейеров извлекают данные из реляционных баз в пакетном или микропакетном режиме. Читайте далее, по каким шаблонам реализовать операции извлечения. Моментальные снимки: периодическая выгрузка данных из исходных таблиц Полная периодическая выгрузка данных из одной или нескольких таблиц – это, пожалуй, самый простой метод извлечения изменяемых данных. По своей сути результат полной...
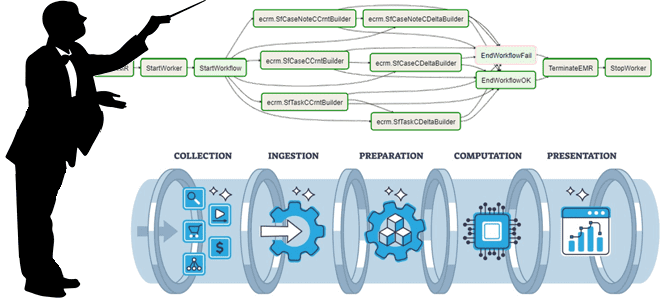
Как организовать упрощенное и продвинутое управление зависимостями между разными ETL-конвейерами, когда нужна централизованная оркестрация рабочих процессов и чем хороша стандартизация активов данных, отчетов и вычислительных процедур. Лучшие практики проектирования конвейеров для дата-инженера. Проектирование дата-конвейеров с минимальными зависимостями Для многих компаний, выстроивших процессы обработки данных в виде конвейеров, актуальна проблема управления...
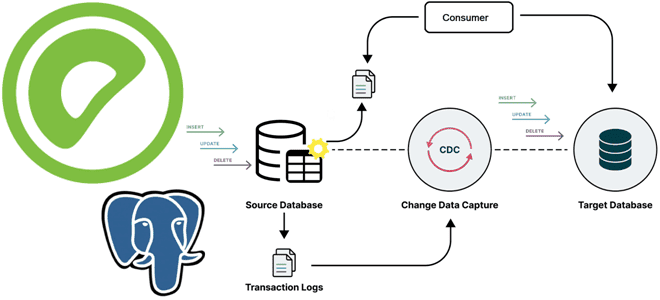
Методы отслеживания изменений в реляционных базах данных: столбцы аудиты, триггеры DDL-событий и WAL-журналы. Плюсы и минусы этих подходов, а также примеры реализации в Greenplum и PostgreSQL. 3 подхода к извлечению данных из реляционных баз Извлечение данных из реляционных баз является наиболее распространенной операцией в ETL-процессах. Поэтому при проектировании конвейеров обработки...

14 декабря 2023 года вышел очередной релиз Apache AirFlow, который содержит более 20 новых фичей, 60 улучшений и 50 исправлений. Знакомимся с самыми главными для дата-инженера новинками выпуска 2.8. ТОП-10 новинок Apache AirFlow 2.8 Многие обновления в версии 2.8 направлены на расширение возможностей создания DAG, улучшение ведения журналов и исправление...
Сегодня разберем, как повысить эффективность использования объектов XCom в Apache AirFlow и сделать свои конвейеры обработки данных еще более гибкими с помощью настройки триггерных правил. Возможности TaskFlow API для XCom Объекты XCom позволяют задачам DAG в Apache AirFlow обмениваться данными. Это очень удобно для реализации конвейера с атомарными задачами, которые...
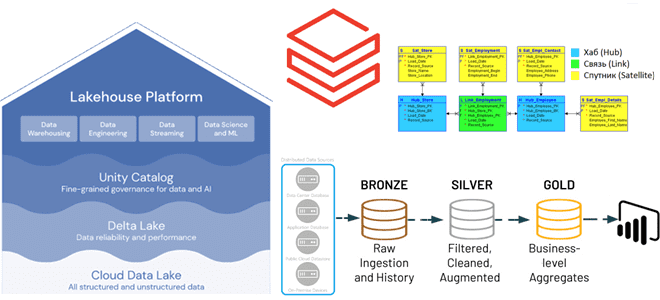
Преимущества методологии Data Vault для проектирования архитектуры данных Lakehouse, а также лучшие практики ее использования с максимальной эффективностью для корпоративного хранилища. Принципы методологии Data Vault и их применение к проектированию DWH Существует множество различных методологий проектирования данных, которые можно использовать при разработке аналитической системы, например, модели звезды и снежинки, подходы...

Ранее мы уже писали об уязвимостях Apache NiFi, выявленных и устраненных в 1-ой половине 2023 года. Сегодня рассмотрим еще 3 ошибки, которые были обнаружены и исправлены в последние 6 месяцев уже уходящего года. Последние 3 уязвимости Apache NiFi во второй половине 2023 года Помимо ранее рассмотренных уязвимостей, в 2023 году...