
Мы уже писали о том, как Trino работает с удаленными объектными хранилищами и файловыми системами. Сегодня поговорим о том, какие изменения выпущены в февральском релизе 2025 года, почему в Trino удалена поддержка доступа к Azure Storage, Google Cloud Storage, S3 и S3-совместимым файловым системам через Hive и что использовать вместо...
Почему Trino не заменит Flink, Spark и Airflow: границы применимости MPP-движка распределенного выполнения SQL-запросов к реляционным и нереляционным источникам данных. Почему Trino не заменит Flink, Spark и Airflow Хотя Trino отлично подходит для быстрой ad-hoc аналитики, позволяя SQL-запросами в реальном времени обращаться к различным базам данных, включая нереляционные хранилища и...

Как устроен механизм отказоустойчивого выполнения в Trino, чем политика повтора QUERY отличается от TASK, зачем настраивать диспетчер обмена на внешнее S3-совместимое хранилище и задавать коэффициент задержки перед повторными попытками выполнить SQL-запрос. 2 политики отказоустойчивого выполнения в Trino Будучи движком online-обработки больших объемов данных с помощью распределенных SQL-запросов, Trino должен иметь...
Почему в хранилище и витрину данных могут попасть дубли, чем это чревато и какие встроенные механизмы дедупликации есть в ClickHouse. Примеры OPTIMIZE-запросов и работы с движком ReplacingMergeTree. Причины дублирования данных и их последствия Дублирование данных в хранилищах и в витринах – довольно частая проблема в дата-инженерии. Это приводит к росту...
Что происходит, когда Trino не хватает памяти для выполнения SQL-запроса, как выполняется сброс промежуточных результатов на диск и почему механизм spill-to-disk не избавляет от OOM-ошибок. Spill-to-disk: сброс промежуточных результатов на диск в Trino Продолжая вчерашний разговор про нехватку памяти (OOM, Out Of Memory) в Trino, сегодня рассмотрим, как работает spill-механизм...

Почему в кластере Trino может возникнуть OOM-ошибка и как справиться с нехваткой памяти, оптимизировав SQL-запросы и настроив конфигурации: примеры и рекомендации. Причины OOM-ошибок в кластере Trino и как их устранить Для Trino, как и для многих JVM-приложений, характерны проблемы с управлением памятью, включая возникновение OOM-ошибок (Out Of Memory). Это связано...
Зачем нужны переменные в Apache AirFlow, какие они бывают, как создать переменную и использовать ее: примеры и рекомендации для эффективной дата-инженерии. Зачем нужны переменные в Apache AirFlow, и какие они бывают Чтобы хранить информацию, которая редко меняется, например, ключи API, пути к конфигурационным файлам, в Apache Airflow используются переменные. Переменные...
Как описать ETL-конвейер захвата, преобразования и передачи изменения данных в YAML-файле: пример конфигурации Flink CDC из PostgreSQL в Elasticsearch. ETL-конвейер Flink CDC в YAML-файле Apache Flink позволяет строить надежные конвейеры обработки данных, используя не только с внутренние API, но и с помощью дополнительных компонентов. Одним из таких компонентов является Flink...

Как работает исполнитель Celery в Apache AirFlow, зачем ему очередь сообщений и каким образом это помогает масштабировать параллельное выполнение задач. Как работает исполнитель Celery в Apache AirFlow Именно исполнитель (Executor) в Apache Airflow отвечает за выполнение задач в рабочих процессах, определяя их локацию и последовательность, а также использование ресурсов. Хотя...
Зачем Trino использует внешние таблицы при запросах к данным в объектных хранилищам и удаленных файловых системах, чем они отличаются от внутренних и как повысить производительность таких SQL-запросов с помощью кэширования. Доступ из Trino к данным в объектных хранилищах Помимо реляционных и нереляционных баз данных, Trino позволяет делать распределенные запросы и...

Что общего между Trino и dbt, чем они отличаются и в каких случаях выбирать тот или иной инструмент для инженерии и анализа данных. Краткий ликбез для начинающего дата-инженера и аналитика. Сходства и отличия Trino и dbt Trino и dbt (Data Build Tool) — это два популярных инструмента с открытым исходным...

Чем BranchPythonOperator отличается от ShortCircuitOperator, что и когда выбирать для ветвления DAG в Apache Airflow: принципы работы и примеры использования. Ветвления DAG в Apache AirFlow с помощью операторов Чтобы поддерживать реализацию сложных конвейеров обработки данных, в Apache Airflow есть соответствующие механизмы ветвления графа задач, т.е. DAG (Directed Acyclic Graph). По...

Что такое Python-декораторы в Airflow, зачем они нужны, какие они бывают и чем полезны: ликбез по TaskFlow API на практическом примере DAG. Что такое Python-декораторы в Airflow и какие они бывают Будучи написанным на Python, Apache Airflow использует именно этот язык в качестве средства разработки дата-конвейеров. После определения функции в...

Чем обмен данными через XCom отличается от использования Dataset и какой из механизмов выбирать для обмена данными между задачами Apache Airflow: разбираем на практическом примере. Обмен данными через XCom В Apache Airflow есть несколько механизмов для обмена данными между задачами: XCom и набор данных (Dataset). При общей цели они предназначены...
Чем процессор RouteOnContent отличается от RouteOnAttribute и RouteText: преимущества и недостатки каждого из них для маршрутизации FlowFile в Apache NiFi, варианты использования каждого из них с примерами. Маршрутизация на основе контента Как мы уже отмечали в прошлой статье, маршрутизация FlowFile в в Apache NiFi может быть на основе контента, т.е....

Как разработать свой плагин Apache AirFlow: пошаговое руководство с наглядной демонстрацией. Добавляем свои пункты меню в веб-интерфейс фреймворка и встраиваем пользовательскую HTML-страницу с новым эскизом Flask. Разработка своего плагина для AirFlow Вчера я рассказывала, как расширить функциональные возможности Apache AirFlow с помощью плагинов. Сегодня рассмотрим, как это сделать на практике....
Зачем нужны плагины в Apache AirFlow, как их создать и встроить в пакетный оркестратор для внедрения пользовательских операторов, хуков, датчиков или интерфейсов взаимодействия с внешними системами. Плагины AirFlow Продолжая недавний разговор про добавление пользовательского кода в Apache AirFlow, сегодня разберемся, как расширить функциональные возможности этого ETL-оркестратора с помощью встраиваемых модулей...
Как добавить пользовательский код в Apache AirFlow и где его хранить: лучшие практики и рекомендации для дата-инженера с примером создания и импорта своего пакета. Как хранить общий код в AirFlow Недавно мы писали про сложности управления DAG в многопользовательской среде Apache AirFlow. Однако, даже когда речь идет про однопользовательскую работу...
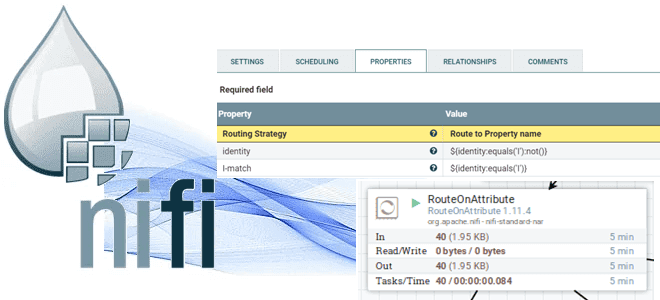
Что такое атрибуты FlowFile, какие процессоры есть в Apache NiFi для работы с ними и как маршрутизировать поток данных на основе пользовательских свойств. Атрибуты FlowFile и процессоры для работы с ними Основной единицей данных, которая перемещается через систему в Apache NiFi является FlowFile. Он представляет собой контейнер для данных и...

Что не так с работой Apache AirFlow в многопользовательской среде, зачем предоставлять каждой команде свое развертывание ETL-фреймворка, каковы недостатки этого решения и как организовать мультитенантный кластер. Почему Apache Airflow не предназначен для многопользовательского использования В современной дата-инженерии Apache AirFlow стал наиболее популярным инструментом для пакетных ETL-процессов. Чтобы использовать его наиболее...