
Мы уже рассказывали о проектах-победителях российского ИТ-конкурса «Проект Года» профессионального сообщества GlobalCIO, представивших корпоративные решения на базе продуктов Arenadata. В 2020 году клиенты Arenadata также вошли в тройку лидеров. Читайте далее, как «Газпром нефть» и ВТБ улучшили свои процессы управления данными с помощью отечественных технологий хранения и аналитики Big Data....

Постоянно добавляя в наши курсы Apache Kafka для разработчиков интересные и практические примеры, сегодня мы разберем кейс тревел-площадки Trainline, которая агрегирует данные от 270 железнодорожных и автобусных компаний в 45 странах, предлагая выгодные билеты на европейские поезда и автобусы. Читайте далее, почему пакетный режим работы озера данных перестал отвечать требованиям...

Дополняя наши курсы дата-инженеров полезными примерами, сегодня рассмотрим, как упростить разработку и мониторинг ETL-конвейеров с помощью дополнительных технологий Big Data, совместимых с Apache Spark. Читайте далее, когда и зачем инженеру данных пригодятся SaaS-продукт Prophecy.io, движок StreamSets Transformer и REST-интерфейс Apache Livy, а также как все они связаны со Spark. 3...

Чтобы дополнить наши курсы по Spark для разработчиков распределенных приложений и инженеров данных практическими примерами, сегодня рассмотрим кейс американской ИТ-компании ThousandEyes, которая разрабатывает программное обеспечение для анализа производительности локальных и глобальных сетей. Читайте далее, как создать надежный конвейер и устойчивое озеро данных (Data Lake) для быстрой аналитики Big Data в...
Поскольку курсы инженеров Big Data предполагают практическое обучение на реальных кейсах, сегодня поговорим про тестирование конвейеров обработки и аналитики больших данных и разберем несколько прикладных примеров для компонентов экосистемы Apache Hadoop. Читайте далее про проверку работоспособности, а также поиск ошибок в Spark-заданиях и DAG-цепочках Airflow. Конвейер для конвейера: сложности тестирования...

Сегодня продолжим разбираться с реализацией CDC-подхода в современных Big Data решениях и погрузимся в Databricks Delta Lake – облачный уровень хранения и аналитики больших данных с поддержкой ACID-транзакций. Читайте далее про переход от ночных ETL-пакетов с Informatica к быстрому обновлению данных в Amazon S3 на конвейере Spark и Kafka. Возможности...

В рамках обучения инженеров больших данных, вчера мы рассказывали о новой версии Apache AirFlow 2.0, вышедшей в декабре 2020 года. Сегодня рассмотрим особенности перехода на этот релиз: в чем сложности миграции и как их решить. Читайте далее про сохранение кастомизированных настроек, тонкости работы с базой метаданных и конфигурацию для развертывания...

В конце 2020 года вышел мажорный релиз Apache AirFlow, основные фишки которого мы рассмотрим в этой статье. Читайте далее про 10 главных обновлений Apache AirFlow 2.0, благодаря которым этот DataOps-инструмент для пакетных заданий обработки Big Data стал еще лучше. 10 главных обновлений Apache AirFlow 2.0 Напомним, разработанный в 2014 году...

В этой статье разберем ключевые характеристики идеального конвейера обработки больших данных. Читайте далее, чем отличается Big Data Pipeline, а также какие приемы и технологии помогут инженеру данных спроектировать и реализовать его наиболее эффективным образом. В качестве практического примера рассмотрим кейс британской компании кибербезопасности Panaseer, которой удалось в 10 раз сократить...

Сегодня поговорим про ETL-процессы в мире Big Data на примере построения непрерывного конвейера поставки больших данных о транзакциях для сервисов машинного обучения. Читайте далее, из чего состоит типичная архитектура такой системы на базе Apache Kafka, Spark, HBase и Hive, а также почему большинство ETL-инструментов не подходят для потоковой передачи событий...

Продолжая разговор про обучение Apache Spark для инженеров данных на практических примерах, сегодня разберем, как организовать интеграцию этого Big Data фреймворка с MPP-СУБД Greenplum. В этой статье мы расскажем о коннекторе Greenplum-Spark, который позволяет эффективно связывать эти средства работы с большими данными, выстраивая аналитический конвейер их обработки (data pipeline). Типовые...
Продвигая наши курсы по Apache AirFlow для инженеров Big Data, сегодня расскажем, чем этот фреймворк отличается от Luigi – другого достаточно известного инструмента оркестровки ETL-процессов и конвейеров обработки больших данных. В этой статье мы собрали для вас сходства и отличия Apache AirFlow и Luigi, а также их достоинства и недостатки,...
Чтобы максимально приблизить обучение Airflow к практической работе дата-инженера, сегодня мы рассмотрим, какие еще есть альтернативы для оркестрации ETL-процессов и конвейеров обработки больших данных. Читайте далее, что такое Luigi, Argo, MLFlow и KubeFlow, где и как они используются, а также почему Apache Airflow все равно остается лучшим инструментом для оркестрации...
Продолжая разговор про конвейеры обработки больших данных, сегодня рассмотрим пример использования Apache AirFlow в агрегаторе аренды частного жилья Airbnb. Читайте далее, в чем коварство накладных расходов при росте ETL-операций и других data pipeline’ов по запуску и выполнению заданий Spark, Hadoop и прочих технологий Big Data. Еще в этой статье разберем,...

Сегодня рассмотрим, как можно фильтровать потоки больших данных в Apache NiFi через типовой механизм SQL-запросов. Читайте далее, чем эта ETL-платформа стриминговой маршрутизации Big Data отличается от других систем, которые используют язык структурированных запросов вне СУБД, какие процессоры позволяют работать с потоковыми файлами (FlowFile) как с таблицами базы данных и при...
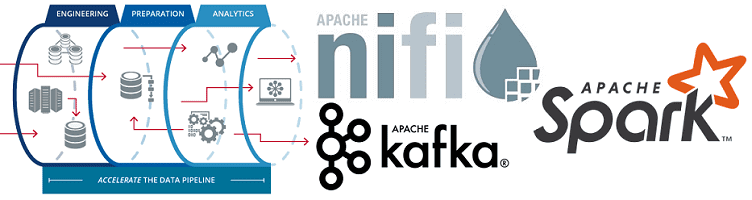
Продолжая разговор про инженерию больших данных, сегодня рассмотрим, как построить ETL-pipeline на открытых технологиях Big Data. Читайте далее про получение, агрегацию, фильтрацию, маршрутизацию и обработку потоковых данных с помощью Apache NiFi, Kafka и Spark, преобразование JSON, а также обогащение и сохранение данных в Hive, HDFS и Amazon S3. Пример потокового...
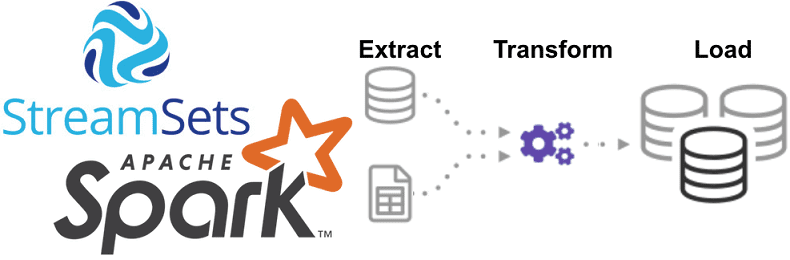
Однажды мы уже рассказывали про StreamSets Data Collector, сравнивая его с Apache NiFi. Сегодня рассмотрим, как устроен этот исполнительный движок для запуска конвейеров обработки больших данных, каким образом он связан с Apache Spark и чем полезен инженеру Big Data при организации ETL-процессов на локальных и облачных озерах данных (Data Lake,...
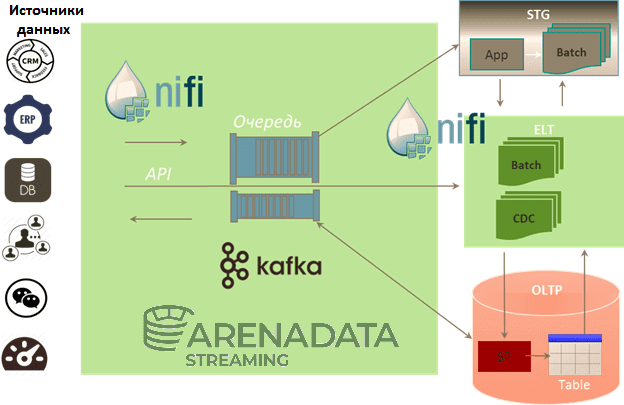
Мы уже рассказывали про преимущества совместного использования Apache Kafka и NiFi. Сегодня рассмотрим, как эти две популярные технологии потоковой обработки больших данных (Big Data) сочетаются в рамках единого решения от отечественного разработчика - Arenadata Streaming. Читайте далее про основные сценарии использования и ключевые достоинства этого современного продукта класса Event Stream...
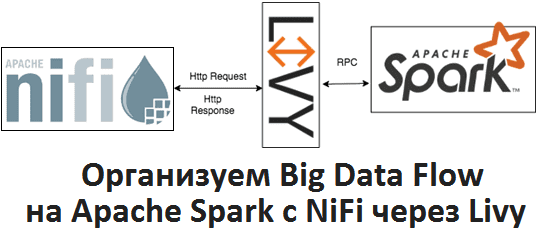
Apache Livy полезен не только при организации конвейеров обработки больших данных (Big Data pipelines) на Spark и Airflow, о чем мы рассказывали здесь. Сегодня рассмотрим, как организовать запланированный запуск пакетных Spark-заданий из Apache NiFi через REST-API Livy, с какими проблемами можно при этом столкнуться и что поможет их решить. Что...
Сегодня рассмотрим примеры совместного использования двух популярных технологий потоковой обработки больших данных (Big Data): Apache Kafka и NiFi. Читайте в нашей статье, как они дополняют друг друга, каковы преимущества их объединения и каким образом инженеру Data Flow это реализовать на практике. Еще раз о том, что такое Apache Kafka и...