
В этой статье мы поговорим про возможность нехарактерного использования Apache Kafka: не как распределенной стримминговой платформы или брокера сообщений, а в виде базы данных. Читайте далее, как Apache Kafka дополняет другие СУБД, не заменяя их полностью, почему такой вариант использования возможен в Big Data и когда он не совсем корректен....

При всех своих достоинствах Delta Lake, включая коммерческую реализацию этой Big Data технологии от Databricks, оно обладает рядом особенностей, которые могут расцениваться как недостатки. Сегодня мы рассмотрим, чего не стоит ожидать от этого быстрого облачного хранилище для больших данных на Apache Spark и как можно обойти эти ограничения. Читайте далее,...

Продолжая разговор про Delta Lake, сегодня мы рассмотрим, чем это быстрое облачное хранилище для больших данных в реализации компании Databricks отличается от классического озера данных (Data Lake) на Apache Hadoop HDFS. Читайте далее, как коммерческое Cloud-решение на Apache Spark облегчает профессиональную деятельность аналитиков, разработчиков и администраторов Big Data. Больше, чем...

Озеро данных (Data Lake) на Apache Hadoop HDFS в мире Big Data стало фактически стандартом де-факто для хранения полуструктурированной и неструктурированной информации с целью последующего использования в задачах Data Science. Однако, недостатком этой архитектуры является низкая скорость вычислительных операций в HDFS: классический Hadoop MapReduce работает медленнее, чем аналоги на Apache...
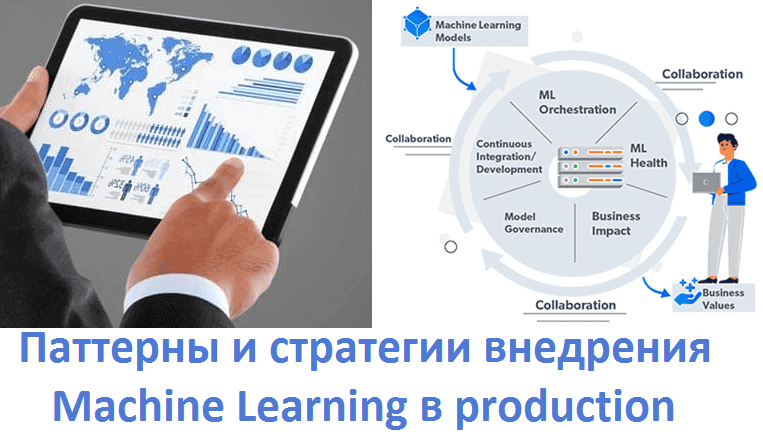
Завершая цикл статей про MLOps, сегодня мы расскажем про 5 шаблонов практического внедрения моделей Machine Learning в промышленную эксплуатацию (production). Читайте далее, что такое Model-as-Service, чем это отличается от гибридного обслуживания и еще 3-х вариантов интеграции машинного обучения в production-системы аналитики больших данных (Big Data), а также при чем тут...

Сегодня мы расскажем о важности прикладного бизнес-анализа в проектах Big Data, включая цифровизацию частного бизнеса и государственных предприятий. Читайте в нашей статье, как области знаний профессионального руководства по бизнес-анализу BABOK®Guide соответствуют типовым этапам внедрения технологий больших данных в корпоративную деятельность, и почему цифровая трансформация любой компании – это, прежде всего,...

В этой статье рассмотрим, как технологии Industry 4.0 помогают российскому нефтехимическому холдингу СИБУР повысить операционную эффективность производства и обеспечить безопасность труда. Сегодня мы собрали для вас 5 примеров практического использования различных методов и инструментов Big Data, Machine Learning, Industrial Internet of Things (IIoT), а также XR (AR+VR). Зачем нефтехимикам технологии...

Чтобы наглядно показать, как аналитика больших данных и машинное обучение помогают быстро решить актуальные бизнес-проблемы, сегодня мы рассмотрим кейс компании Леруа Мерлен. Читайте в нашей статье про нахождение аномалий в сведениях об остатках товара на складах и в магазинах с помощью моделей Machine Learning, а также про прикладное использование Apache...

В продолжение темы про совместное использование Apache Kudu с другими технологиями Big Data, сегодня рассмотрим, как эта NoSQL-СУБД работает вместе с Kafka, Spark и Cloudera Impala для построения озера данных (Data Lake) для быстрой аналитики больших данных в режиме реального времени. Также читайте в нашей статье про особенности интеграции Apache...

В этой статье продолжим разговор про Apache Kudu и рассмотрим, как эта NoSQL-СУБД используется с Hadoop и Cloudera Impala, чем она полезна в организации озера данных (Data Lake) и почему Куду не заменяет, а успешно дополняет HDFS и HBase для эффективной работы с большими данными (Big Data). Apache Kudu в...

Аналитика больших данных для руководителей и других конечных бизнес-пользователей – это не только графические дэшборды BI-систем. Сегодня рассмотрим, что такое самообслуживаемая аналитика Big Data, какова ее польза для бизнеса и чего не стоит ждать от self-service BI. Что такое self-service BI: определение, назначение и примеры Еще в 2018 году исследовательское...

В продолжение темы про озера данных (Data Lake) и Apache Hadoop, сегодня мы рассмотрим еще 3 примера использования этих технологий Big Data для аналитики больших данных в промышленности. Читайте в нашей статье, как косметический гигант L’Oréal создает новые продукты с помощью платформы Talend Data Fabric, «УРАЛХИМ» прогнозирует объемы продукции и...

В этой статье разберем кейс построения экосистемы управления Big Data с озером данных на примере федеральной фармацевтической сети - российской Ассоциации независимых аптек (АСНА). Читайте в этом материале, зачем фармацевтическому ритейлеру большие данные, с какими трудностями столкнулся этот проект цифровизации и как открытые технологии (Arenadata Hadoop, Apache Spark, NiFi и...

Мы уже затрагивали тему корпоративных хранилищ данных (КХД), управления мастер-данными и нормативно-справочной информаций (НСИ) в контексте технологий Big Data. В продолжение этого, сегодня рассмотрим, что такое профилирование данных, зачем это нужно, при чем тут озера данных (Data Lake) и ETL-процессы, а также прочие аспекты инженерии и аналитики больших данных. Что...

В этой статье поговорим про интеграцию информационных систем: обсудим SOA и ESB-подходы, рассмотрим стриминговую архитектуру и возможности Apache Kafka для организации быстрого и эффективного обмена данными между различными бизнес-приложениями. Также обсудим, что влияет на архитектуру интеграции корпоративных систем и распределенных Big Data приложений, что такое спагетти-структура и почему много сервисов...

В этой статье рассмотрим несколько примеров по аналитике больших данных в Elasticsearch (ES), а также разберем возможности алгоритмов машинного обучения в ELK Stack. Читайте, как использовать NoSQL-СУБД ES в качестве озера данных для проверки различных бизнес-гипотез с помощью Machine Learning, показывая результаты моделирования в интерфейсе Kibana: практическая аналитика Big Data....

В этой статье мы продолжим рассказывать про практическое использование отечественных Big Data решений на примере российского дистрибутива Arenadata Hadoop (ADH) и массивно-параллельной СУБД для хранения и анализа больших данных Arenadata DB (ADB). Сегодня мы приготовили для вас еще 3 интересных кейса применения этих решений в проектах цифровизации бизнеса и государственном...

Сегодня мы поговорим про продукты компании Arenadata – отечественного разработчика дистрибутива Apache Hadoop (ADH), массивно-параллельной СУБД для хранения и анализа больших данных Arenadata DB (ADB) и других Big Data платформ. Читайте в нашей статье, где внедрены эти решения и какую пользу они уже успели принести бизнесу. Облака и банк: 3...
Сегодня мы поговорим о проектировании архитектуры корпоративных хранилищ данных (КХД) и рассмотрим, какие методы и инструменты используются для моделирования структуры DWH и динамики ETL-процессов. В этой статье про основы Data Modelling разберем, что такое OLAP и OLTP, почему 3-я нормальная форма стала стандартом в SQL-СУБД, чем схемы звезды отличается от...
В этой статье рассмотрим 5 уровней управленческой зрелости бизнес-процессов компании и особенности построения озера данных (Data Lake) на каждом из них. Читайте дальше, что такое CMMI и при чем здесь большие данные (Big Data). CMMI: зрелость процессов для технологий Big Data Примерно с 2013 года тема технологий Big Data преподносится...