
Формат данных в озере или гибридном хранилище типа Data LakeHouse сильно влияет на скорость выполнения аналитических запросов. Сегодня рассмотрим, как Apache CarbonData делает аналитику больших данных в реальном времени еще быстрее. Что такое Apache CarbonData Традиционные форматы данных, часто используемые в проектах Big Data, такие как CSV и AVRO, имеют...
Сегодня поговорим о том, как обработка исключений позволяет спроектировать и реализовать надежную архитектуру конвейера обработки данных, включая ETL/ELT-процессы и их компоненты. Архитектура конвейеров обработки данных: ETL/ELT-процессы Наличие хорошо спроектированной инфраструктуры данных необходимо для получения максимальной отдачи от данных для data-driven управления. Поскольку данные постоянно увеличиваются в объеме, следует организовать управление...
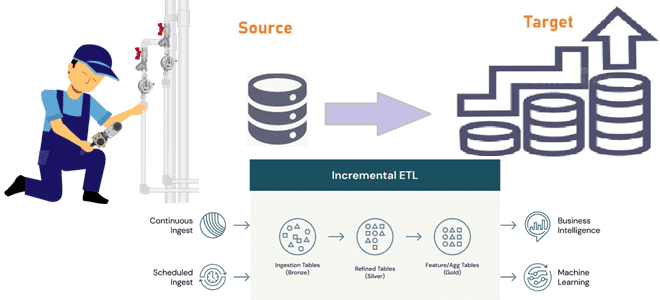
Инкрементные конвейеры загрузки больших объемов данных в корпоративное хранилище или озеро как самый экономичный способ масштабирования архитектуры данных. Разбираемся, как дата-инженеру эффективно организовать такие ETL-конвейеры. 2 способа организации конвейеров инкрементной загрузки данных Инкрементный ETL (Extract, Transform and Load) для классического DWH стал обычным явлением с источниками CDC (сбор данных об...
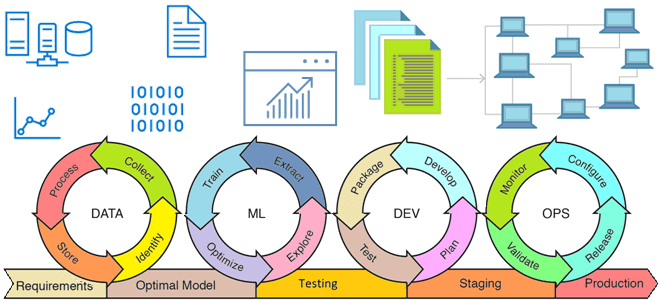
Из каких компонентов состоит архитектура MLOps, что такое инфраструктура как код, как управлять ею с помощью скриптов и почему это нужно на каждом этапе жизненного цикла моделей Machine Learning. Жизненный цикл ML-модели и MLOps MLOps – это набор методов и техник машинного обучения вместе с лучшими практиками разработки, развертывания и...
Сегодня разберем проблемы микросервисной архитектуры для платформ данных и способы их решения, а также вспомним 5 популярных шаблонов развертывания, которые могут смягчить риски от внедрения новых версий многокомпонентной системы. Проблемы микросервисной архитектуры для платформы данных и способы их решения При всех плюсах микросервисной архитектуры (автономность, гибкость, масштабируемость, простота развертывания, технологическая...
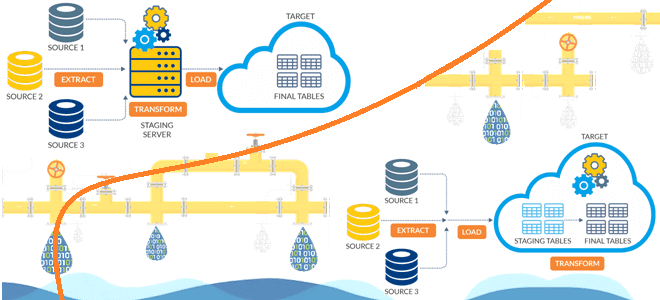
Чем динамичный ELT-подход лучше традиционного ETL, в чем разница между этими архитектурами конвейеров данных и зачем нужно профилирование данных при построении высокоэффективных дата-пайплайнов. Чем ETL отличается от ELT: ликбез для дата-инженера Аналитика больших данных невозможна без ETL/ELT-процессов, т.е. извлечения данных из разных источников (базы данных, файлы, API, прикладные системы), их...
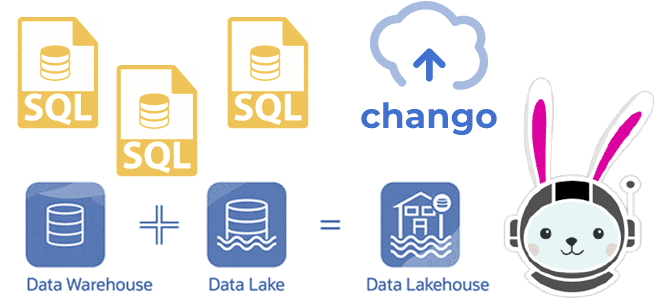
Как реализовать гибридную архитектуру данных Lakehouse на новой платформе Chango с движком обработки распределенных запросов Trino без дополнительного развертывания кластера Kafka и разработки Spark-приложений потоковой передачи событий. Что такое Trino: принципы работы распределенного SQL-движка О том, что представляет собой новая гибридная архитектура данных под названием Lakehouse, мы подробно писали здесь,...

Что такое потоковая аналитика больших данных, какие бывают СУБД потоковой передачи, когда и зачем их использовать, а также что влияет на выбор этих инструментов хранения и аналитической обработки Big Data. Что такое потоковые базы данных и как они работают Мы уже упоминали, что аналитика данных в реальном времени может быть...
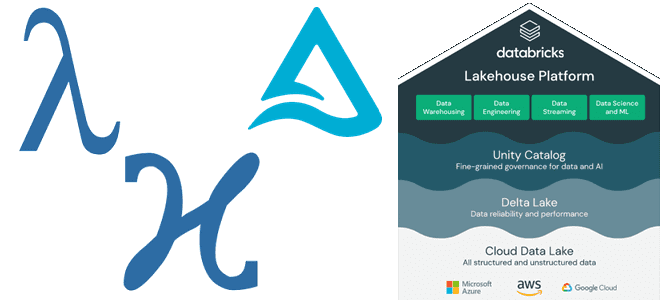
Как Lakehouse объединяет пакетную и потоковую обработку, какие проблемы возникают при реализации этой гибридной архитектуры данных и каким образом они решаются с помощью Delta-подхода и Apache Spark Structured Streaming. Краткая история появления дельта-архитектуры от лямбда- и каппа-моделей Мир больших данных постоянно развивается: появляются новые технологии и архитектурные шаблоны. В частности,...
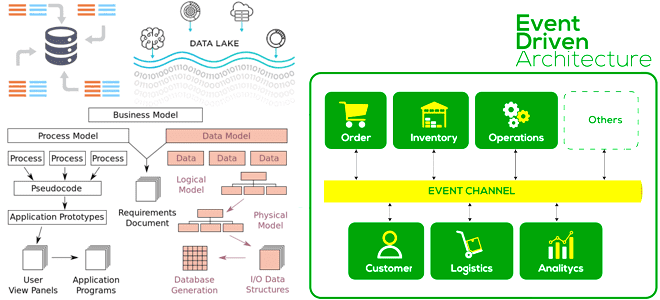
Чем схема, применяемая к данным, при чтении отличается от схемы при записи, почему она вызывает GIGO-проблему в Data Lake, и как применить принципы функциональной дата-инженерии к архитектуре данных, управляемой событиями. Схема при чтении или при записи: главное отличие NoSQL-решений от реляционных СУБД NoSQL-решения и Apache Hadoop реализуют стратегию «схема при...

Что такое Delta Sharing, зачем нужен и как устроен этот открытый стандарт, а также как его использовать для централизованного управления доступом к данным в архитектуре Data Mesh. Что такое Delta Sharing и при чем здесь Data Lake Чтобы упростить обмен большими данными между разными компаниями в режиме реального времени и...
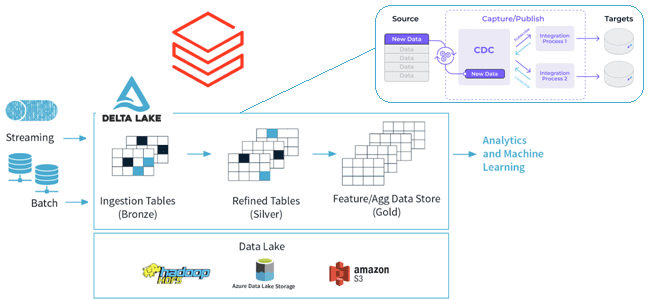
Как реализовать CDC для Delta Lake: разбираемся с функцией Change Data Feed от Databricks, которая позволяет быстро узнать обо всех изменениях строк в дельта-таблицах озера данных. Польза и принципы работы CDF для дата-инженера и архитектора данных. CDC для Delta Lake Идея сбора и обработки не всего объема данных, а только...
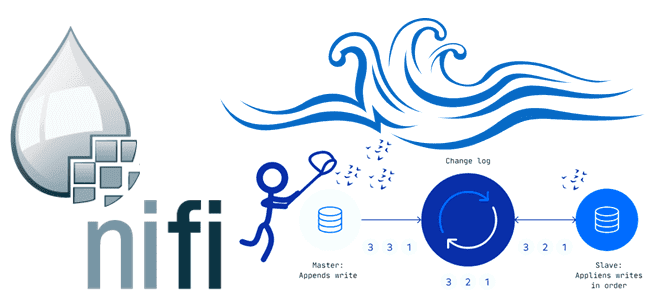
В этой статье для обучения дата-инженеров рассмотрим, как организовать сбор измененных данных из реляционных СУБД, построив CDC-конвейер с помощью Apache NiFi. А также разберем, зачем процессоры этого потокового ETL-маршрутизатора используют технологию веб-хуков. ETL-конвейер для DWH и Data Lake В общем случае сбор данных из реляционных и нереляционных источников и построение...
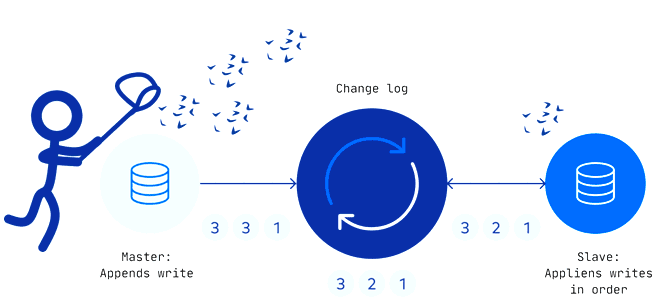
Захват измененных данных считается довольно известным паттерном организации ETL-процессов для корпоративных хранилищ и озер данных. Как реализуется CDC-технология, по каким шаблонам, что их ограничивает и чем опасен дрейф изменений в Change Data Capture. Паттерны и принципы реализации захвата измененных данных Эффективность эксплуатации озера данных зависит от ETL-процессов, поскольку объемы данных...
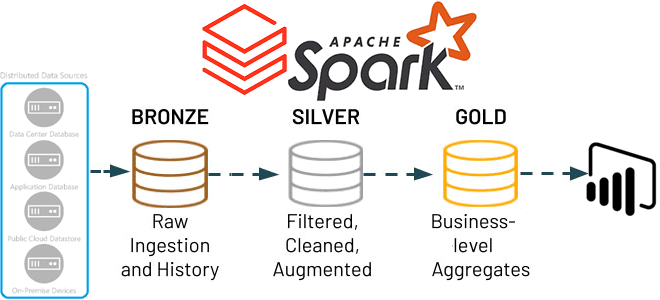
В этой статье для обучения дата-инженеров и ИТ-архитекторов рассмотрим, как Apache Spark Structured Streaming помогает реализовать самообслуживаемый сервис потоковой передачи данных в Delta Lake. А также вспомним каноническую 3-хслойную модель этого уровня хранения от Databricks. Много потоковых сценариев в одном приложении Apache Spark Structured Streaming Мы недавно писали, что архитектуры,...

Управление версиями датасетов для ML-моделей, а также версионирование самих алгоритмов машинного обучения является одной из важных задач MLOps-концепции непрерывной разработки и развертывания систем Machine Learning. Читайте, как реализовать это с помощью платформы LakeFS и фреймворка MLflow. Что такое LakeFS и при чем здесь MLOps Системы контроля версий, такие как Git,...

В этой статье для обучения дата-инженеров и разработчиков распределенных приложений, сегодня разберем опыт ИТ-компании Similarweb, где Apache Spark на платформе Databricks вместо AWS Athena ускорил пакетную обработку данных в 50 раз. Также рассмотрим приемы повышения производительности ODBC-драйвера Databricks для улучшенного взаимодействия с озерами данных. Постановка задачи и ограничения POC для...

Недавно мы писали про чтение данных из AWS S3 с помощью PySpark-задний. Продолжая разбираться, как перейти от HDFS к облачным объектным хранилищам, сегодня рассмотрим пример чтения и записи файлов из Google Cloud Storage с помощью Apache Spark. От HDFS к GCS Распределенная файловая система Apache Hadoop (HDFS) уже много лет...

Чтобы сделать наши курсы по Apache Spark для дата-инженеров еще более полезными, сегодня рассмотрим, как PySpark-задания могут считывать данные из корзин объектного хранилища AWS S3, используя Python-пакет boto3. Читайте далее, что представляет собой этот SDK, как использовать его вместе с IAM-ролями, а также как обеспечить безопасность конфиденциальных данных с помощью...

Сегодня рассмотрим, зачем нужно внешнее хранилище метаданных для Apache Hive, и как запустить его высокодоступный и масштабируемый сервис в Amazon EKS путем контейнеризации приложения. Зачем нужно внешнее хранилище метаданных Apache Hive? Apache Hive используется для доступа к данным, хранящимся в распределенной файловой системе Hadoop (HDFS) через стандартные SQL-запросы. Это NoSQL-хранилище...