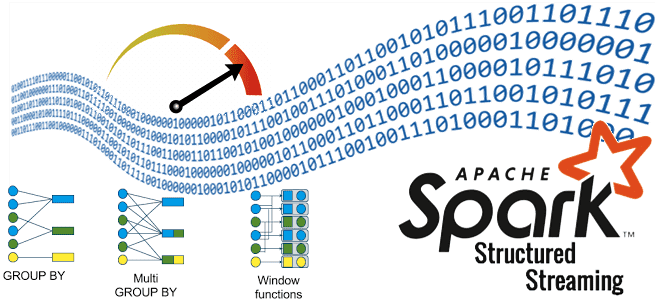
Как выполнение нескольких stateful-операторов в одном потоке снижает стоимость обработки данных: возможности и ограничения Spark Structured Streaming. Про водяные знаки и состояния в потоковой передаче событий. Stateful-операторы и водяные знаки в потоковой обработке данных Благодаря распределенной обработке микропакетов в памяти Spark Structured Streaming позволяет обрабатывать огромные объемы данных очень быстро....
Одной из причин быстрой работы ClickHouse являются движки таблиц, оптимизированные на конкретные операции с данными. Сегодня рассмотрим, чем они отличаются и какой из них выбирать для разных сценариев. Движки БД ClickHouse Прежде чем разбираться с движками таблиц ClickHouse, вспомним само назначение этого термина. Движок БД или механизм хранения отвечает за...

Какие инфраструктурные компоненты самые дорогие в эксплуатации популярной платформы потоковой передачи сообщений и как снизить затраты на сетевые ресурсы и хранилища данных при использовании Apache Kafka. TCO для Apache Kafka: что учитывать в расчете затрат Поскольку Apache Kafka используется для интеграции информационных систем в режиме реального времени, она становится критически...
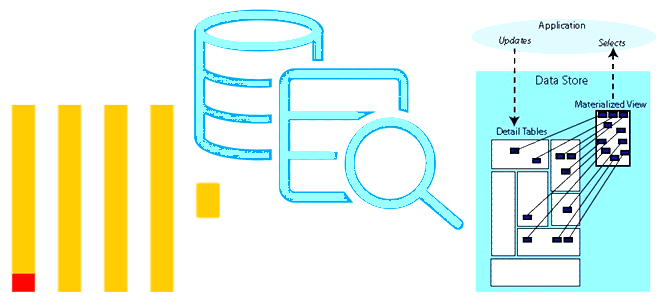
Чем материализованное представление в ClickHouse отличается от обычного, зачем нужны LIVE-представления и как их использовать. Примеры SQL-запросов с VIEW для самой популярной колоночной аналитической СУБД. Представления vs словари в ClickHouse Поскольку ClickHouse, как типовая колоночная СУБД, используется для аналитической обработки огромных объемов данных в реальном времени, вопрос ускорения вычислений для...
Большинство ETL-конвейеров извлекают данные из реляционных баз в пакетном или микропакетном режиме. Читайте далее, по каким шаблонам реализовать операции извлечения. Моментальные снимки: периодическая выгрузка данных из исходных таблиц Полная периодическая выгрузка данных из одной или нескольких таблиц – это, пожалуй, самый простой метод извлечения изменяемых данных. По своей сути результат полной...
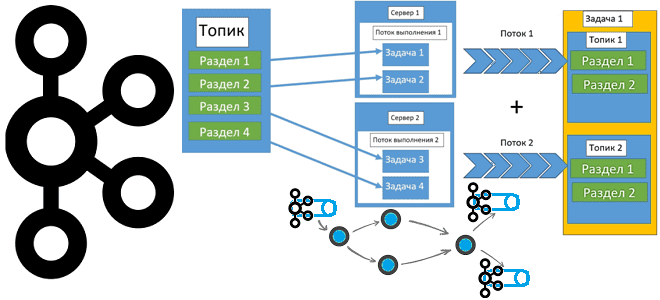
Почему нельзя просто взять и соединить потоки Kafka Streams с разным числом разделов, и как это все-таки сделать без изменения конфигурации топика. Почему нельзя просто взять и соединить потоки Kafka Streams с разным числом разделов Kafka Streams – это клиентская Java-библиотека для разработки потоковых приложений, которые работают с данными, хранящимися...

В конце декабря принято строить планы на следующие 12 месяцев. Посмотрим, что разработчики Apache Flink обещают реализовать в релизе 2.0, который должен выйти к концу 2024 года. Внедрение многоуровневой системы хранения состояний В Apache Flink 2.0 будет улучшена система управления хранилищем состояния путем перехода к полностью разделенной архитектуре хранения и...
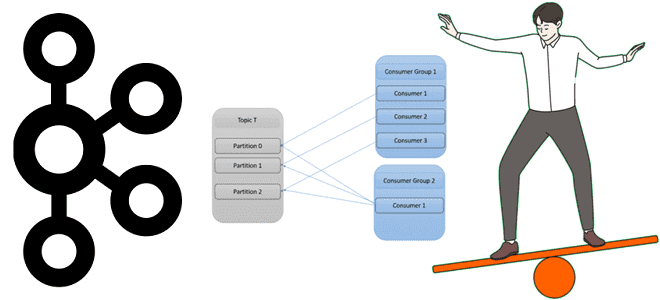
Чем group.instance.id отличается от group.id, зачем нужен member.id, каковы преимущества статического членства в группе потребителей перед динамическим и какие механизмы Kafka обеспечивают ребалансировку клиентских приложений. Еще раз про группы потребителей Apache Kafka Напомним, группы потребителей в Apache Kafka нужны для логического объединения нескольких потребителей с целью повышения надежности потоковой системы....
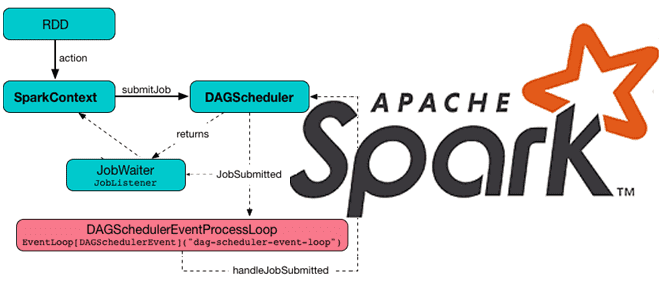
Какие механизмы и компоненты позволяют Apache Spark планировать задания и эффективно утилизировать ресурсы кластера. Чем статическое разделение ресурсов отличается от динамического, и как настроить планировщик для ускорения вычислений. Планирование заданий в Apache Spark Распределенный характер Apache Spark предполагает наличие инструментов для разделения ресурсов между вычислениями. В режиме кластера каждое приложение...

Сегодня познакомимся с возможностями и ограничениями open-source проект Diskquota, направленного на оптимизацию управления дисковым пространством базы данных Greenplum. Зачем ограничивать использование диска в Greenplum и как это сделать Эффективная утилизация аппаратных ресурсов, в т.ч. жесткого диска – один из факторов, позволяющих ускорить работу любой СУБД, в т.ч. Greenplum. Будучи популярным...
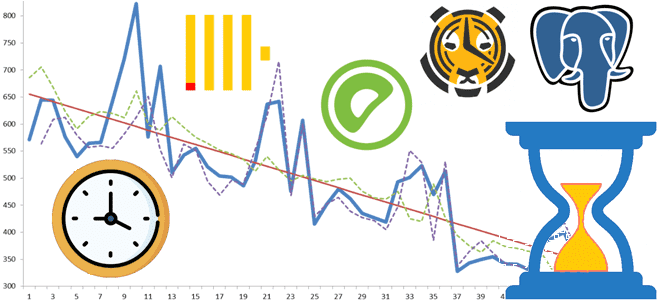
Анализ временных рядов нужен не только в Data Science, но и в мониторинге системных событий. Чем столбец с отметками времени в ClickHouse отличается от гипертаблиц в PostgreSQL и Greenplum c расширением TimescaleDB, и что выбирать для аналитики больших данных. ClickHouse для анализа временных рядов ClickHouse является колоночной СУБД для аналитической...

Что лучше: один или несколько кластеров Apache Kafka, когда и зачем разворачивать новый кластер вместо масштабирования существующего, какие задачи администрирования поручить локальным DevOps-инженерам, а что решать централизовано. Один или несколько кластеров Apache Kafka? Продолжая разговор про эффективное управление корпоративным кластером Apache Kafka, сегодня рассмотрим, когда и зачем нужно разворачивать новый...

Зачем размещать задания Apache Spark на узлах HDFS, какую пропускную способность сети передачи данных выбрать, почему не рекомендуется использовать RAID для жестких дисков, сколько выделить памяти и ядер ЦП. Рекомендации по настройке оборудования для Spark-приложений На практике большинство заданий Spark считывает входные данные из внешней системы хранения, например, файловой системы...
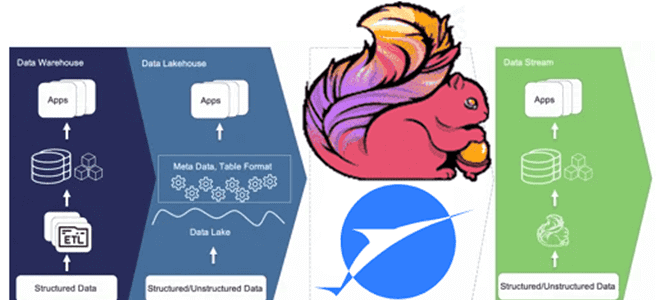
Что не так с архитектурой данных Lakehouse, зачем разработчики Apache Flink создали на основе табличного хранилища новую дата-платформу, чем хорош подход Streamhouse и как устроен Apache Paimon. Что такое архитектура данных Streamhouse Не успели дата-архитекторы освоиться с Lakehouse – архитектурой данных, которая объединяет преимущества хранилищ и озер данных, комбинируя масштабируемость...
Что такое профилирование кода, зачем это нужно и как работают Python-профилировщики в приложениях Apache Spark. Пример профилирования PySpark-программы. Что такое профилирование и почему это важно для PySpark-приложений Будучи написанном на java и Scala, Apache Spark также поддерживает декларативные API-интерфейсы Python, которые позволяют разработчику писать и запускать код на этом более...

Что такое словарь в ClickHouse, какие бывают словари, как их создать и каким командами к ним обращаться. Пара примеров со словарями в самой популярной колоночной аналитической СУБД. Что такое словарь в ClickHouse Как колоночная база данных, ClickHouse предназначена для аналитической обработки огромных объемов данных в реальном времени. Аналитические сценарии предполагают...
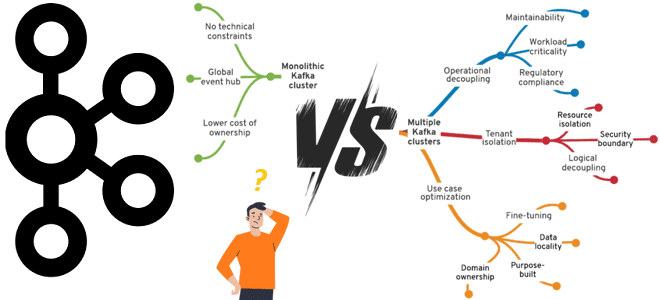
Что выбрать для эффективного управления корпоративным кластером Apache Kafka, от чего зависит уровень централизации и какие факторы влияют на принятие решений. Стратегии управления корпоративным кластером Apache Kafka Типовой вариант использования Apache Kafka – это потоковая интеграция корпоративных приложений. Чтобы эффективно использовать эту платформу потоковой передачи событий в масштабах предприятия, необходимо...
Как выполнить миграцию данных: лучшие практики и рекомендации на примере Greenplum. Особенности и принципы работы утилит gpbackup, gprestore и gpcopy. Миграция данных из Greenplum на 7 с утилитами gpbackup и gprestore Независимо от причины миграции данных из прикладной системы или корпоративного хранилища данных на новую технологию, эта процедура всегда остается...
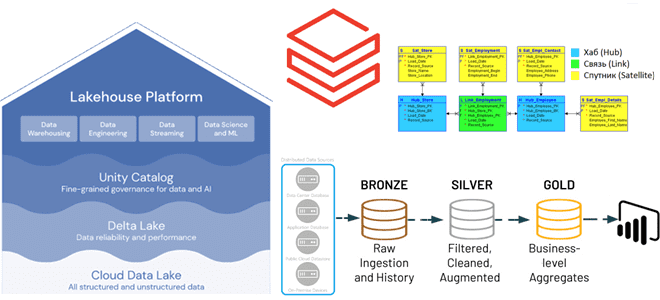
Преимущества методологии Data Vault для проектирования архитектуры данных Lakehouse, а также лучшие практики ее использования с максимальной эффективностью для корпоративного хранилища. Принципы методологии Data Vault и их применение к проектированию DWH Существует множество различных методологий проектирования данных, которые можно использовать при разработке аналитической системы, например, модели звезды и снежинки, подходы...
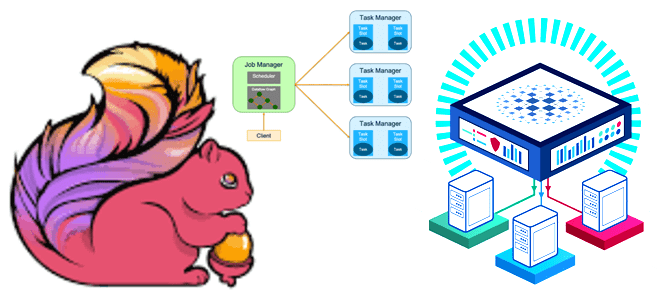
Как работает Flink-приложение, из каких компонентов состоит распределенный кластер и как сделать его отказоустойчивым. Архитектура и принципы работы высокой доступности Apache Flink. Архитектура Flink-приложения: ключевые компоненты и связь между ними Перед тем, как погружаться в средства обеспечения высокой доступности Flink-приложения, вспомним базовые принципы его работы. Сам по себе Apache Flink...