
Сегодня рассмотрим, как построить конвейер потоковой обработки событий на Apache Kafka, Flink и SQL Stream Builder с визуализацией результатов в Grafana. Далее вас ждет практический кейс применения технологий Big Data в реальном производстве на примере телеметрии процессов ферментации продуктов в небольшой частной пивоварне. Постановка задачи: бизнес-контекст и используемые технологии В...
Завершая серию статей по IoT-платформе компании Tesla на базе Apache Kafka, сегодня рассмотрим проблемы пиковой загрузки системы и особенности обработки высокоприоритетных событий. Читайте далее, как оптимально определить ключ раздела, чтобы снизить затраты на передачу данных, избежать перегрузки в пиковые моменты и отделить пользователей данных от разработчиков и дата-инженеров. Тонкости обработки...

В этой статье для дата-инженеров мы собрали лучшие практики построения масштабируемых конвейеров обработки данных, а также популярные рекомендации по проектированию ETL/ELT-процессов с Apache Spark, AirFlow и другими технологиями Big Data. Читайте далее, когда ELT лучше ETL и наоборот, чем хорош Apache Spark в конвейерах обработки Big Data, зачем нужен AirFlow,...

В рамках курсов по Apache Hadoop для дата-аналитиков и инженеров данных сегодня рассмотрим пару практических примеров работы с популярным SQL-on-Hadoop инструментом этой экосистемы. Читайте далее, как настроить соединение удаленного сервера Apache Hive к Spark-приложению через JDBC и решить проблему запроса таблицы HBase в Hive вместо повторной репликации данных. Подключение удаленного...

Мы уже упоминали, что Apache Kafka не слишком хорошо обрабатывает сообщения чрезмерно большого размера. Сегодня рассмотрим, как эта проблема решается в конвейерах потоковой обработки IoT-инфраструктуры Tesla. Читайте далее про модификацию синтаксического анализатора данных от множества устройств интернета вещей с поиском компромисса между скоростью и надежностью с помощью коннектора Alpakka к...

При том, что Apache Spark является одной из главных технологий стека Big Data, этот фреймворк не очень хорошо работает с множеством файлов небольшого размера. Поэтому в рамках обучения дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим, почему это происходит, зачем динамически сжимать файлы в Apache Spark и как это делает платформа...

В рамках обучения разработчиков распределенных приложений, сегодня рассмотрим, как упростить тестирование и отладку заданий Apache Flink с помощью Byteman. Читайте далее, как внедрить Java-код в JVM, чтобы извлечь нужные сведения о выполнении Flink-приложения на платформе Veverica и ускорить разработку. Разработка и отладка приложений Apache Flink: ежедневные сложности В рассматриваемом примере...

Продолжая разбирать кейс компании Tesla по организации централизованного управления устройствами интернета вещей (Internet of Things, IoT), сегодня разберем, как выполняется обработка сообщений в топиках Apache Kafka с помощью Confluent Schema Registry и Kafka Streams. Читайте далее, как определить потоковый процессор для парсинга данных в CSV и JSON-форматах с использованием схемы...

Сегодня разберем кейс компании Renault по масштабированию своей цифровой платформы и снижению затрат с помощью BigQuery и Apache Spark на Google Dataproc. Цифровизация в автомобильной промышленности: конвейер сбора и аналитики больших данных с производства средствами Google сервисов и снижение затрат на облако в 2 раза через изменение конфигурации Spark SQL....

В рамках курсов для дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим пример построения системы потоковой передачи для аналитики больших данных на базе Apache Kafka, Spark и Google BigQuery. Читайте далее про Proof of Concept для конвейера продуктовой аналитики, который обрабатывает 50 миллиардов событий каждый день, и какие важные уроки ИТ-архитектор...

Являясь лидером отрасли, IoT-устройства Tesla обрабатывают триллионы событий в день, чтобы повысить эффективность своих электроавтомобилей. Однако, такая производительность была получена не сразу: чтобы достичь ее, инженерам компании пришлось решить множество проблем из области интернета вещей (Internet of Things, IoT). Сегодня рассмотрим, как часть из них была решена с помощью Apache...
В рамках программы курсов по Greenplum и Arenadata DB, сегодня рассмотрим важную для разработчиков и администраторов тему об особенностях оптимизатора SQL-запросов GPORCA, который ускоряет аналитику больших данных лучше встроенного PostgreSQL-планировщика. Читайте далее, как выбирать ключ дистрибуции, почему для GPORCA важна унифицированная структура многоуровневой партиционированной таблицы и каким образом оптимизаторы обрабатывают...

YARN считается самым распространенным диспетчером ресурсов в кластерах Apache Hadoop и Spark, отвечая за выделение ресурсам распределенным приложениям. Сегодня в рамках обучения дата-инженеров и администраторов Hadoop рассмотрим достоинства и недостатки 3-х вариантов планирования ресурсов в YARN. Читайте далее, что такое иерархия очереди и как вычисляется ее мгновенная справедливая доля. Планирование...

Сегодня в рамках обучения дата-аналитиков и разработчиков Spark-приложений, рассмотрим еще несколько особенностей этого фреймворка. Почему count() работает по-разному для RDD и DataFrame, как отличается уровень хранения при применении метода cache() для этих структур, когда использовать SortWithinPartitions() вместо sort(), а также парочка тонкостей обработки Parquet-таблиц в Spark SQL и кэширование метаданных...

В этой статье для дата-инженеров и администраторов Apache Kafka рассмотрим, зачем Confluent выпустил премиум коннектор Splunk S2S Source и как на базе этих платформ построить эффективную систему потоковой аналитики больших данных. Также читайте далее, что такое универсальный сервер рассылки Splunk и какие конфигурации коннектора позволяют автоматически создавать топик Kafka для сбора...
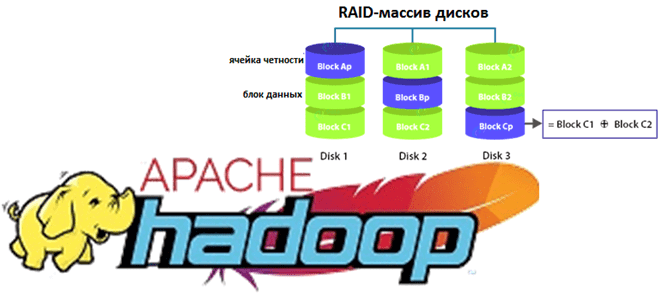
Недавно мы рассказывали про новые функции свежего релиза Apache Hadoop 3.3.1. Сегодня разберем подробнее, что такое Erasure Coding и как эта технология кодирования со стиранием экономит место в распределенной файловой системе HDFS. Также заглянем внутрь EC и рассмотрим, чем алгоритм Рида-Соломона лучше ассоциативной операции XOR для обеспечения отказоустойчивости хранилища больших...

Сегодня рассмотрим, что такое Beekeeper и как этот сервис помогает администраторам Hadoop и пользователям Apache Hive очищать метаданные этого NoSQL-хранилища. Читайте далее, зачем удалять устаревшие пути из Metastore и как настроить конфигурацию Hive-таблиц для автоматического прослушивания событий их изменения. Для чего очищать потерянные метаданные в Apache Hive Напомним, Apache Hive...

Поскольку Greenplum и Arenadata DB основаны на популярной open-source СУБД PostgreSQL, сегодня разберем, чем они отличаются от этой объектно-реляционной базы данных. Далее вас ждет краткий и понятный ответ на вопрос Greenplum vs PostgreSQL: сходства и отличия этих систем с учетом аналитики больших данных и практических кейсов дата-инженерии. Что общего между...

Специально для разработчиков распределенных приложений, Data Scientist’ов и аналитиков больших данных, работающих с Apache Spark, в этой статье мы собрали несколько полезных советов по ежедневным операциям в этом фреймворке. Читайте далее, как добавить библиотеку TypeSafe в файл sbt-конфигурации Spark-приложения, получить датафреймы из JSON-массивов и структур, а также обработать CSV-формат с...
В рамках курсов по Apache Kafka для разработчиков и администраторов кластера, сегодня заглянем под капот AdminClient и на практических примерах разберем, как динамически создавать новый топик и описывать его программным способом через API. Еще рассмотрим, почему метод deleteTopics() нужно применять очень осторожно, а также вспомним основы ООП, говоря про классы...