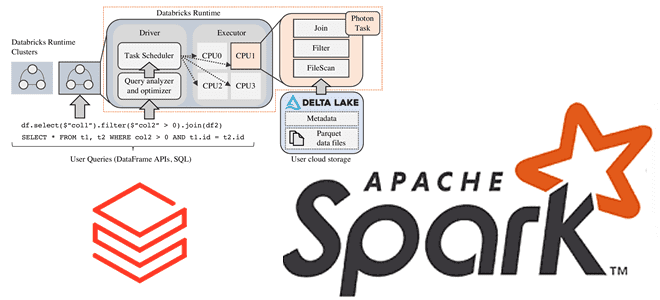
Зачем Databricks выпустила новый движок выполнения запросов Spark SQL для ML-приложений, как он работает и где его настроить: возможности и ограничения Photon Engine. Преимущества Photon Engine для ML-нагрузок Spark-приложений Чтобы сделать Apache Apark еще быстрее, разработчики Databricks выпустили новый движок выполнения запросов - Photon Engine. Это высокопроизводительный механизм запросов, который...

Зачем хранить данные в Apache Kafka постоянно и как это сделать: варианты использования и пример архитектурного решения Infinite Storage от Confluent Cloud, который лег в основу Tiered Storage. Infinite Storage от Confluent Cloud для бесконечного хранения данных в Apache Kafka Изначально Apache Kafka, как и любой другой брокер сообщений, не...

Разработчики ClickHouse с завидной регулярностью радуют новыми релизами. Не прошло и месяца, как опубликован очередной выпуск этой колоночной СУБД, версия 24.8 LTS от 20 августа 2024. О ее главных новинках читайте далее. Несовместимые изменения Начнем с самых важных и несовместимых изменений. В релизе ClickHouse 24.8 LTS для clickhouse-client и clickhouse-local...
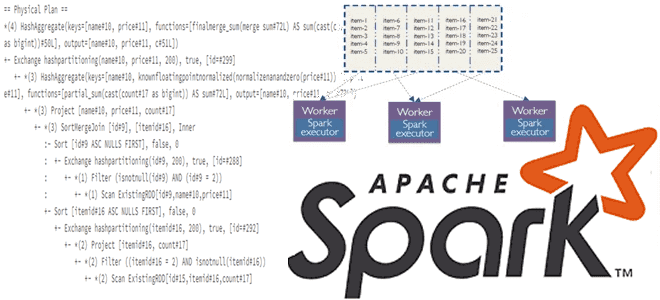
Что такое Dynamic Partition Pruning в Spark SQL, как работает этот метод оптимизации пакетных запросов, зачем его использовать в задачах аналитики больших данных, и каким образом повысить эффективность его практического применения. Что такое Dynamic Partition Pruning и зачем это нужно в Spark SQL Параллельная обработка данных в Apache Spark обеспечивается...
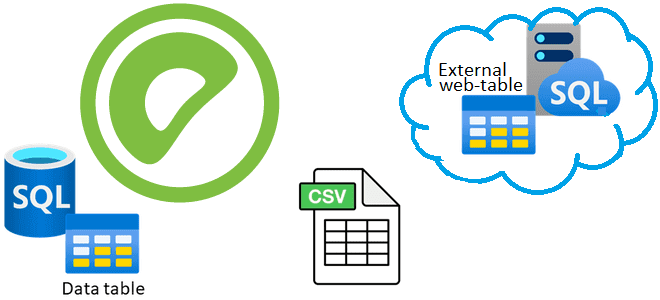
Что такое внешние веб-таблицы, зачем они нужны, чем отличаются от обычных external tables и как создать такую таблицу в Greenplum на основе команд и на основе URL. Зачем нужны внешние веб-таблицы в Greenplum О том, что в Greenplum есть внешние (external) и сторонние (foreign) таблицы, которые обеспечивают доступ к данным,...

2 августа 2024 года вышел свежий релиз Apache Flink. Знакомимся с главными новинками выпуска 1.20 для упрощения потоковой обработки данных в мощных управляемых конвейерах: новые материализованные таблицы, единый механизм слияния файлов для контрольных точек, улучшения DataStream API и пакетных операций. Улучшения Flink SQL Начнем с новинок Flink SQL, одной из...

Новая логика дедупликации данных, ограничения работы с матпредставлениями, дополнительные SQL-функции и улучшения производительности ClickHouse 24.7: краткий обзор ключевых особенностей июльского выпуска. Несовместимые изменения и новые фичи 30 июля 2024 года вышел очередной релиз ClickHouse, в котором довольно много изменений, несовместимых с прошлыми версиями. В частности, в реплицированных базах данных теперь...
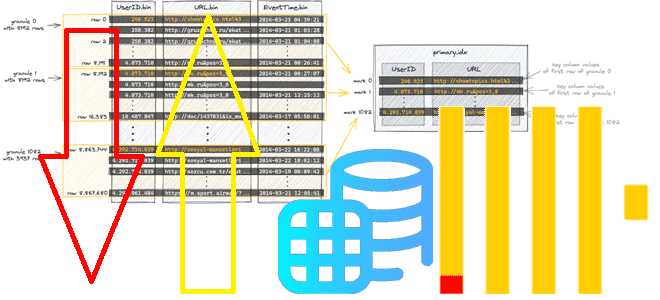
Зачем в ClickHouse 24.6 добавлена настройка optimize_row_order для оптимизации порядка строк MergeTree-таблиц, как она работает и где ее применять. Как связаны индексация и сортировка таблиц в ClickHouse Даже не будучи классической реляционной СУБД, ClickHouse поддерживает индексацию, насколько это возможно в его колоночной природе, индексируя первичным ключом целую группу строк (гранулу)...
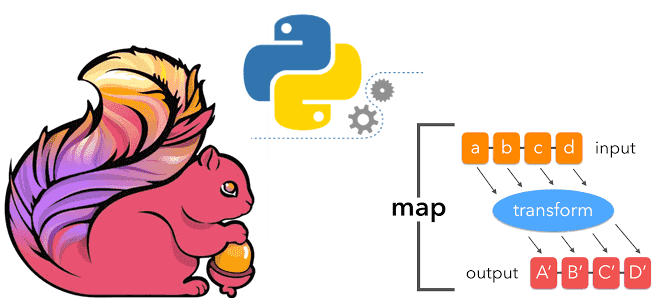
Что такое rich-функции в Apache Flink, зачем они нужны, чем отличаются от обыкновенных UDF и как с ними работать: простой пример на PyFlink с запуском в Google Colab. Rich-функции в Apache Flink Будучи очень мощным фреймворком для разработки распределенных потоковых приложений, Apache Flink не только предоставляет широкий набор stateful-функций, но...

20 июня 2024 года вышел очередной релиз Greenplum. Разбираемся с ключевыми новинками выпуска 7.2: сканирование индекса в AO-таблицах, изменения в оптимизаторе GPORCA, улучшенная обработка геопространственных данных и новая служба централизованного управления сегментами Postmaster. Новинки Greenplum 7.2 для дата-инженера Начнем с изменений, повышающих производительность Greenplum. Одним из них стало сканирование индекса...
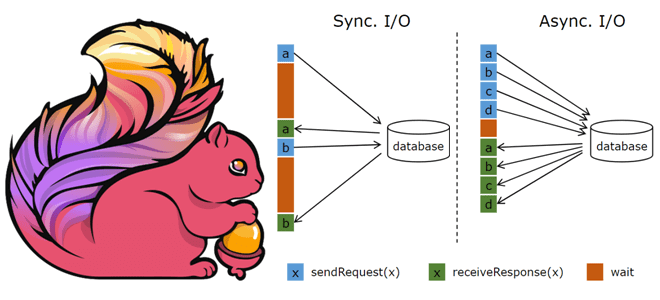
API асинхронного ввода-вывода в Apache Flink и как его использовать для асинхронной интеграции данных из внешней системы с потоком событий. Основы асинхронной обработки в Apache Flink Обогащение потоков данных информацией из внешних систем является довольно сложным кейсом из-за необходимости синхронизировать скорость поступления событий с задержкой доступа к внешнему источнику. При...

Как устроен потоковый запрос Spark Structured Streaming на уровне кода: интерфейсы, их методы и как их настроить, создание и запуск StreamingQuery. Создание потокового запроса в Spark Structured Streaming Хотя структурированная потоковая передача Spark основана на SQL-движке этого фреймворка, в ней гораздо больше сложных абстракций. Например, с точки зрения программирования потоковый...
Почему параллельное выполнение заданий в Apache Spark зависит от языка программирования и как можно обойти однопоточную природу Python в PySpark. Что не так с параллельным выполнением заданий PySpark и как это исправить? Apache Spark позволяет писать распределенные приложения благодаря инструментам для распределения ресурсов между вычислительными процессами. В режиме кластера каждое...
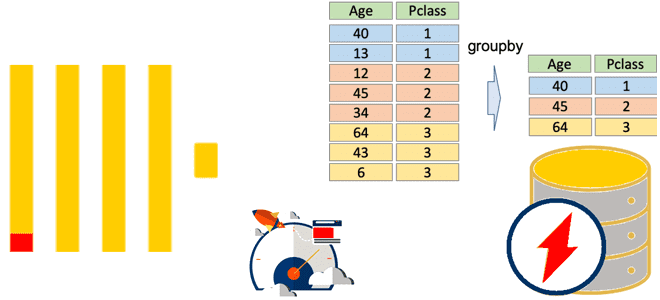
Как работают агрегатные функции в ClickHouse, почему SQL-запросы с GROUP BY потребляют много памяти и что поможет сделать их быстрее и эффективнее: лайфхаки многопоточной агрегации в колоночной базе данных. Особенности выполнения оператора GROUP BY в ClickHouse Агрегатные функции позволяют вычислить экстремум (минимум/максимум), среднее значение, количество, сумму или другое результирующее значение...

Как размер пакета, режим вывода и интервал срабатывания триггера потоковой обработки влияют на скорость вычислений в приложении Apache Spark Structured Streaming и как настроить эти параметры. Размер пакета при потоковой обработке данных в Spark Streaming Хотя скорость обработки данных средствами Apache Spark Streaming зависит от многих факторов, включая саму структуру...
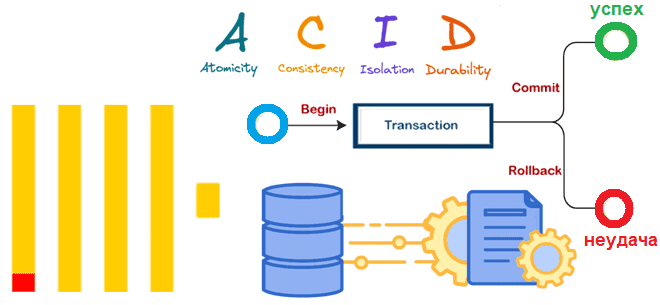
Почему в ClickHouse нет полноценных транзакций, но введена экспериментальная поддержка ACID для операций вставки в таблицы движка MergeTree, как это реализуется и чем синхронная вставка отличается от асинхронной. Особенности операций вставки в ClickHouse В ClickHouse нет полноценных транзакций, поскольку это колоночное хранилище в первую очередь ориентировано на чтение большого объема...
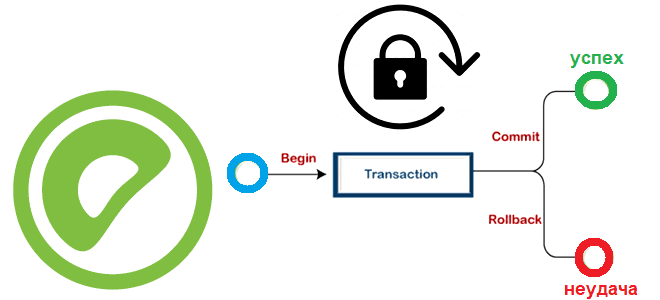
Какие SQL-команды есть в Greenplum для транзакционной обработки данных, как MVCC исключает явные блокировки, можно ли установить их вручную и как это сделать: режимы блокировки и глобальный детектор взаимоблокировок в MPP-СУБД. Транзакции, MVCC и режимы блокировки Greenplum Про изоляцию транзакций в Greenplum и Arenadata DB мы уже писали здесь. Транзакции...
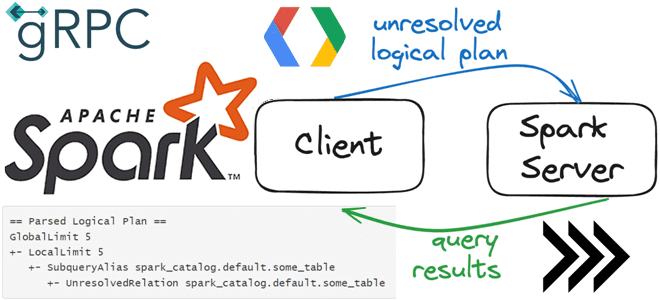
Что общего у клиент-серверной архитектуры Spark Connect с JDBC-драйвером подключения к БД, как взаимодействуют клиент и сервер по gRPC, как подключиться к серверу и указать обязательность поля в схеме proto-сообщения. Как работает Spark Connect О том, что представляет собой Spark Connect и зачем нужен этот клиентский API, позволяющий удаленно подключаться...

3 июня 2024 года вышел предварительный релиз Apache Spark 4.0. Эта версия еще не считается стабильной и предназначена только для ознакомления. Поэтому даже полноценные release notes по ней пока отсутствуют. Тем не менее, сегодня познакомимся с наиболее интересными фичами этого выпуска: новый тип данных VARIANT, API источника данных Python и...

Почему потоковый сервер Greenplum выгружает данные во внешние системы пакетно: тонкости утилиты gpfdist и YAML-файла конфигурации выгрузки. Возможности и ограничения GPSS-сервера при выгрузке данных во внешние системы из MPP-СУБД. Потоковый сервер Greenplum Ключевым отличием Greenplum от PostgreSQL является поддержка механизма массово-параллельной обработки, благодаря чему эта MPP-СУБД относится к стеку Big...