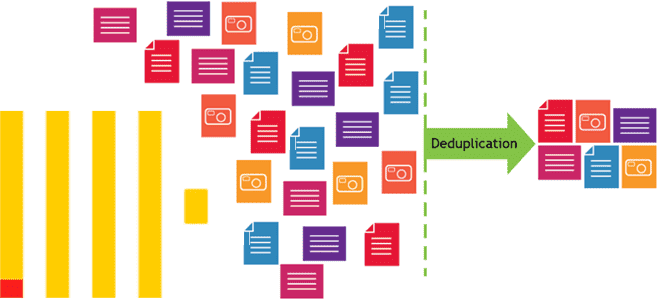
Почему в хранилище и витрину данных могут попасть дубли, чем это чревато и какие встроенные механизмы дедупликации есть в ClickHouse. Примеры OPTIMIZE-запросов и работы с движком ReplacingMergeTree. Причины дублирования данных и их последствия Дублирование данных в хранилищах и в витринах – довольно частая проблема в дата-инженерии. Это приводит к росту...
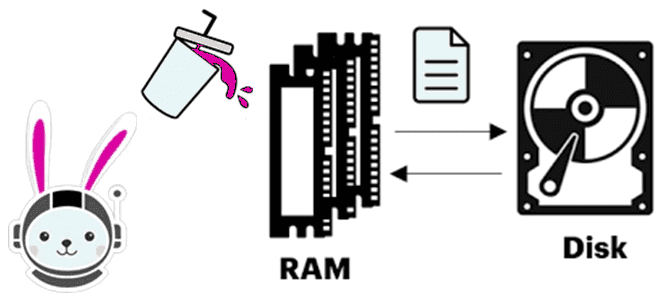
Что происходит, когда Trino не хватает памяти для выполнения SQL-запроса, как выполняется сброс промежуточных результатов на диск и почему механизм spill-to-disk не избавляет от OOM-ошибок. Spill-to-disk: сброс промежуточных результатов на диск в Trino Продолжая вчерашний разговор про нехватку памяти (OOM, Out Of Memory) в Trino, сегодня рассмотрим, как работает spill-механизм...
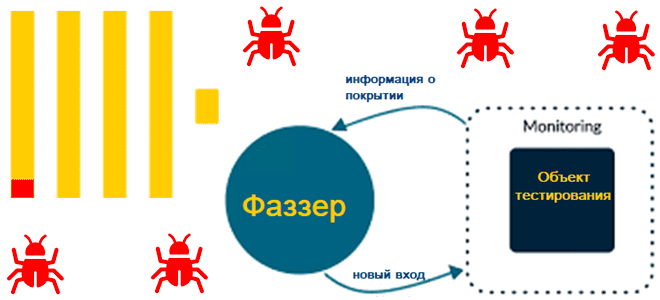
Что такое фаззинг-тестирование, зачем нужен новый фаззер для ClickHouse, и как BuzzHouse выявляет сложные проблемы и потенциальные уязвимости самой популярной колоночной СУБД, Что такое фаззинг-тестирование баз данных Поскольку база данных тоже программный продукт, перед выпуском в релиз она тестируется. Используемых при этом методов тестирования довольно много, и одним из них...

Что такое Apache Doris, как его использовать для построения хранилища данных и чем это отличается от ClickHouse. Сценарии применения и критерии выбора основы DWH. Что такое Apache Doris Недавно мы рассматривали, почему ClickHouse подходит для реализации хранилища данных на основе эталонной архитектуры Medallion благодаря поддержке более 70 форматов файлов, материализованным...
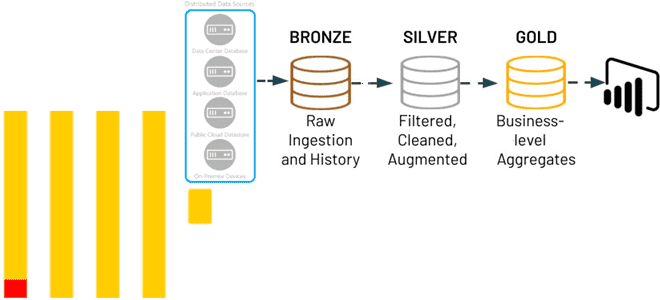
Почему ClickHouse подходит для архитектуры данных Medallion и как реализовать это слоистое хранилище средствами колоночной СУБД без сторонних инструментов: лучшие практики и примеры использования. 3 слоя архитектуры данных Medallion Слоистая архитектура, предложенная компанией Databricks, сегодня считается классикой для построения озер и хранилищ данных. Она предполагает реализацию 3-х уровней (слоев): Бронза,...
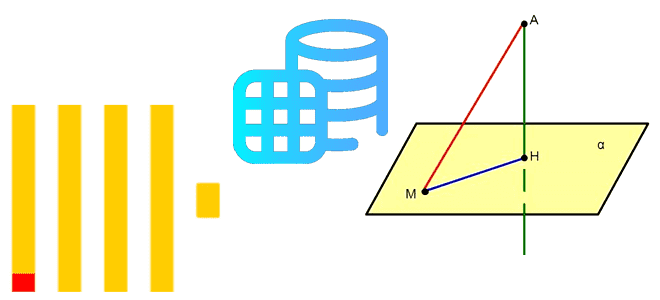
Зачем создавать разные проекции таблиц в базе данных и как это работает в Clickhouse: практический пример с агрегатным запросом. Возможности и ограничения механизма проекций в колоночной аналитической СУБД. Что такое проекции и как они реализованы в ClickHouse Поскольку основное назначение ClickHouse – аналитика больших объемов данных в реальном времени, это...
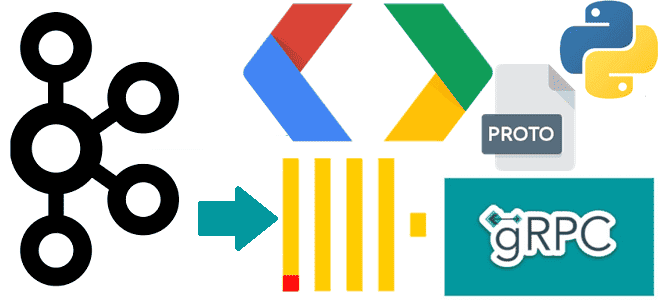
Чем полезна поддержка gRPC в Clickhouse и как ее реализовать: разбираем интерфейс удаленного вызова процедур на примере потоковой вставки событий пользовательского поведения из Kafka в таблицу колоночной базы данных со стриминговым выводом. Поддержка gRPC в ClickHouse ClickHouse поддерживает gRPC – фреймворк от Google и система удаленного вызова процедур с открытым...
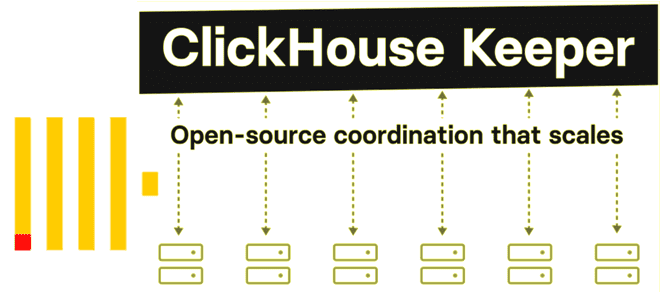
Что не так с Apache Zookeeper и почему разработчики ClickHouse решили заменить его на встроенный сервис синхронизации метаданных на базе RAFT-протокола с линеаризацией записи и чтения. Как работает ClickHouse Keeper и где его настроить. Что не так с Apache Zookeeper Многие распределенные системы, которые состоят из нескольких узлов, для обеспечения...
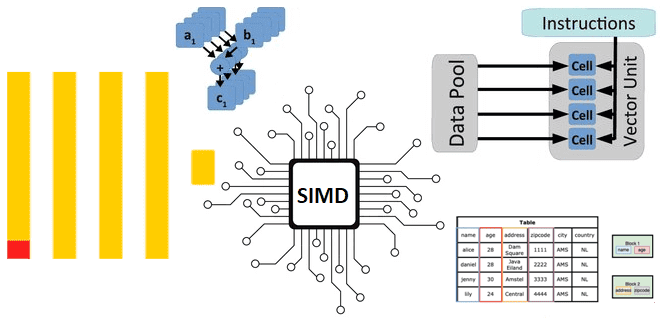
Как ClickHouse реализует параллельные векторные вычисления над большим объемом данных на любых аппаратных платформах: диспетчеризация ЦП для выполнения SIMD-инструкций в сложных функциях. Реализация векторных вычислений в ЦП Как мы уже отмечали здесь, ClickHouse имеет встроенную поддержку векторных вычислений, когда при выполнении одной инструкции процессора производится не одна операция, а одновременно...

Что такое Observability и чем ClickHouse хорош для обеспечения наблюдаемости, как хранить журналы и трассировки в этой колоночной базе данных и для чего реализована интеграция с OpenTelemetry. Что такое Observability и чем ClickHouse хорош для обеспечения наблюдаемости Будучи колоночной базой данных, ClickHouse отлично подходит для мониторинга и анализа системных метрик,...
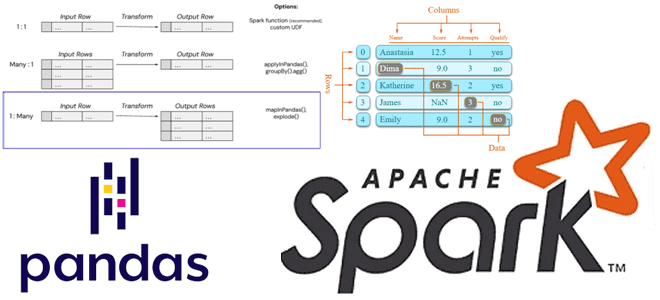
Как применить пользовательскую функцию Python к объектам pandas в распределенной среде Apache Spark. Варианты использования Pandas UDF, applyInPandas() и mapInPandas() на практических примерах. Разница между Pandas UDF, applyInPandas и mapInPandas в Apache Spark Недавно я показывала пример сравнения быстродействия метода applyInPandas() с функцией apply() библиотеки pandas. Однако, помимо applyInPandas() в...
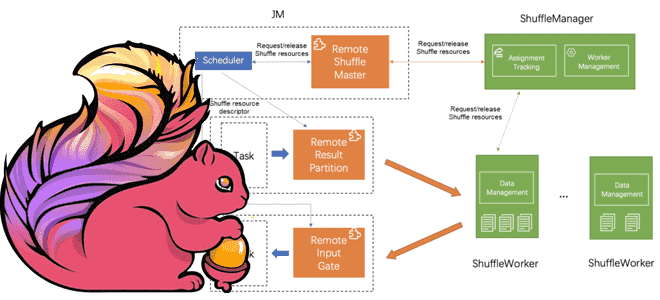
Что такое Remote Shuffle Service в Apache Flink, зачем это нужно и как служба удаленного перемешивания позволяет создавать масштабируемые и надежные приложения для унифицированной потоковой и пакетной обработки больших объемов данных. Что такое Remote Shuffle Service в Apache Flink Apache Flink рассматривает пакетную обработку как частный случай потоковых вычислений. Однако,...

4 октября 2024 года вышел очередной релиз ClickHouse. Знакомимся с его самыми интересными особенностями: добавление строк в обновляемые материализованные представления, агрегатные функции для типов данных JSON и Dynamic, поддержка заголовков HTTP-ответов, автозамена строк с overlay-командами и другие новинки выпуска 24.9. Обновляемые материализованные представления Начнем с наиболее значимой новой функции ClickHouse...

Чем метод applyInPandas() в Spark отличается от apply() в pandas и насколько он быстрее обрабатывает данные: сравнительный тест на датафрейме из 5 миллионов строк. Методы применения пользовательских функций к датафреймам в Spark и pandas Мы уже отмечали здесь и здесь, что Apache Spark позволяет работать с популярной Python-библиотекой pandas, поддерживая...
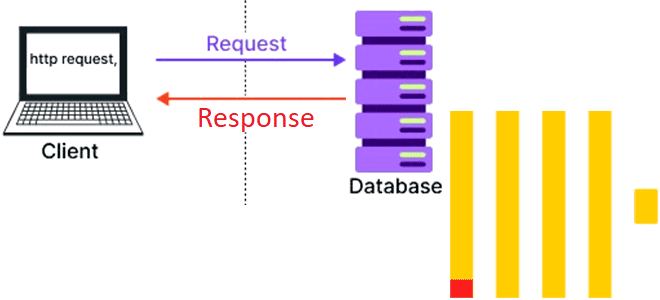
Как реализовать систему с двухзвенной архитектурой на ClickHouse и браузере. Возможности колоночной СУБД для создания одностраничных веб-приложений. Возможности ClickHouse для одностраничных веб-приложений Хотя трехзвенная архитектура (клиент -> бэк-> база данных) уже давно стала стандартом де-факто в разработке веб-приложений, двухзвенная архитектура, когда бизнес-логика переносится в базу данных, до сих пор встречается....
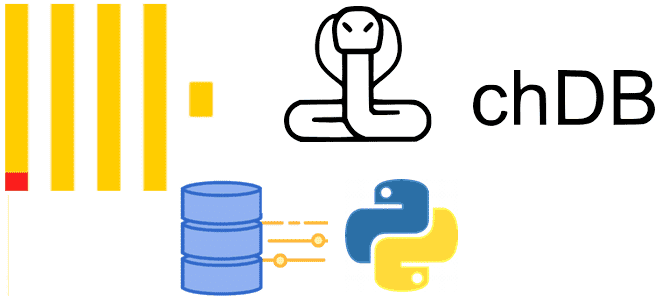
Что такое Chdb, зачем нужна эта библиотека и как ее использовать в коде Python-приложения для анализа больших данных в ClickHouse без разворачивания полноценного сервера этой колоночной СУБД. Как и зачем работать с ClickHouse без сервера СУБД ClickHouse является мощным инструментом аналитики больших данных, который требует соответствующей инфраструктуры. Однако, иногда нужно...

Зачем включать ротацию лог-файлов потоковых приложений Apache Spark, какие конфигурации помогут ее настроить и для чего сжимать файлы журналов в длительных заданиях. Чем полезна ротация лог-файлов Spark-приложений и как ее настроить Об общих принципах логирования системных событий в приложениях Apache Spark мы уже рассказывали здесь. В этой статье подробнее разберем...

Чем объектное хранилище данных отличается от классической файловой системы POSIX, как это влияет на разработку Spark-приложений, почему операция переименования снижает производительность облачных вычислений и что поможет ее избежать. Еще раз об отличиях объектных и файловых хранилищ и как это влияет на приложения Spark Будучи компонентом экосистемы Apache Hadoop, фреймворк Spark...
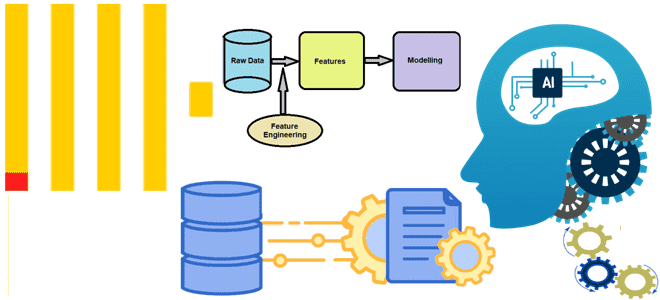
Что такое хранилище признаков, зачем это нужно в машинном обучении, каковы его главные компоненты и как использовать ClickHouse в качестве Feature Store для ML-задач. Хранилище признаков для машинного обучения: архитектура и принципы работы Feature Store Будучи колоночной базой данных, ClickHouse отлично подходит на роль хранилища фичей (Feature Store) для задач...

24 сентября вышел очередной релиз Apache Spark. Он не содержит новых фичей, но зато в нем есть несколько полезных оптимизаций и исправлений безопасности. Читайте далее о самом главном из них, связанном с утечкой токена делегирования Hadoop. Зачем нужны токены делегирования Hadoop в Spark и как они работают В выпуске Apache...