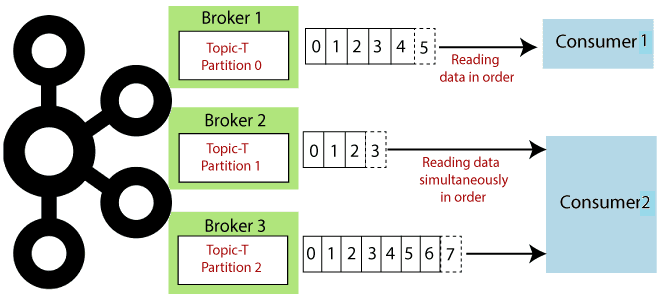
Что общего у Kafka Streams и Consumer API, чем они отличаются и что выбирать для практического использования: краткое руководство для разработчика приложений потоковой обработки событий. Возможности и ограничения Kafka Streams и Consumer API Поскольку Apache Kafka как огромная экосистема со множеством компонентов для потоковой передачи событий, обилие и разнообразие этих...
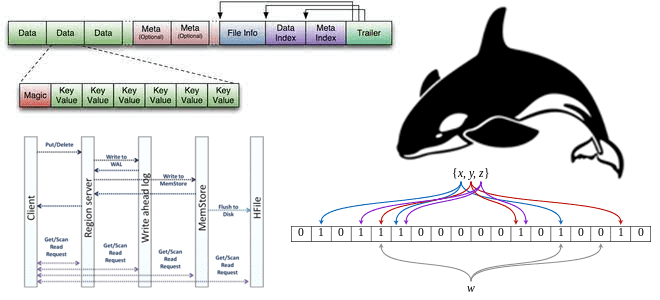
Что такое HFile, как появился этот низкоуровневый файловый формат, каковы его главные принципы работы, как Apache HBase использует его для хранения и быстрой аналитики больших данных, и при чем здесь фильтр Блума. Роль HFile в Apache HBase Apache HBase реализует возможности Google BigTable для Hadoop. Эта NoSQL-СУБД типа «семейство колонок»...

Как не запутаться в многообразии коннекторов к Kafka, доступных во Flink Table API, и выбрать наиболее подходящий для своего сценария применения. Разница между Append Mode и Upsert-режимом коннектора Flink SQL к Kafka. 2 режима работы коннектора Kafka в Apache Flink Apache Flink поставляется с универсальным соединителем Kafka, который поддерживает последнюю...

Что такое потоковая аналитика больших данных, какие бывают СУБД потоковой передачи, когда и зачем их использовать, а также что влияет на выбор этих инструментов хранения и аналитической обработки Big Data. Что такое потоковые базы данных и как они работают Мы уже упоминали, что аналитика данных в реальном времени может быть...
Чего не хватает в PL/Python и зачем нужна еще одна библиотека для создания Python-скриптов обработки данных в Greenplum. Возможности API GreenplumPython и сравнение с pandas. Что такое PL/Python и как это работает в Greenplum Мы уже писали, что Greenplum изначально поддерживает Python, предоставляя PL/Python – загружаемый процедурный язык, который позволяет...
В Apache Spark есть 3 структуры данных, каждая из которых имеет собственный API со своими достоинствами и недостатками. Сегодня разберем плюсы и минусы Dataset API, а также рассмотрим особенности JOIN-операций в нем. Почему Dataset API в Apache Spark работает только со Scala и Java Напомним, структура данных Dataset впервые появилась...
Какие проблемы характерны для распределенных очередей сообщений, почему они случаются и как с ними справиться. Разбираемся со сбоями, ошибками и перегрузками на примере Apache Kafka и RabbitMQ. Проблемы с распределенными очередями и главные причины их появления Хотя Apache Kafka — это целая экосистема со множеством компонентов для потоковой передачи событий,...
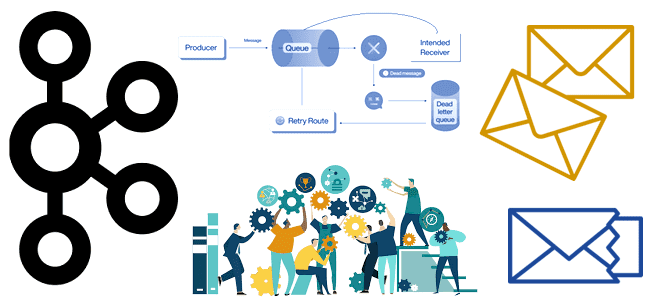
Недавно мы писали про очереди недоставленных сообщений в Apache Kafka и RabbitMQ. Сегодня поговорим про стратегии обработки ошибок, связанные с DLQ-очередями в Kafka, а также рассмотрим, какие сообщения НЕ надо помещать в Dead Letter Queue. 4 стратегии работы с DLQ-топиками в Apache Kafka Напомним, в Apache Kafka в очереди недоставленных...
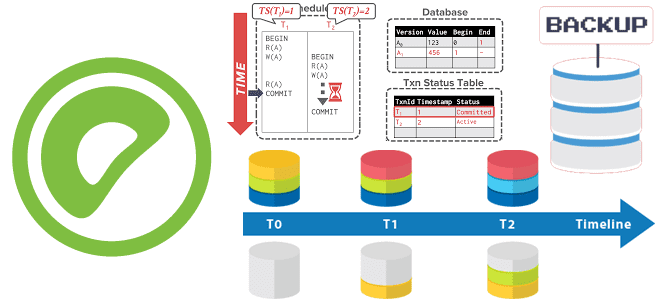
Как Greenplum расширяет MVCC-модель PostgreSQL для управления доступом к данным в многопользовательской среде, обеспечивая согласованность и изоляцию транзакций для нескольких сегментов в большом кластере. Преимущества моментальных снимков перед блокировками и их польза для резервного копирования. MVCC и транзакции в Greenplum с PostgreSQL Будучи основанной на PostgreSQL, о чем мы писали здесь,...

23 марта 2023 года вышел очередной релиз Apache Flink. Разбираемся с главными новинками выпуска 1.17.0: полезные фичи, исправленные ошибки и улучшения для дата-инженера и разработчика распределенных приложений. Новинки пакетной обработки В Apache Flink 1.17 внесено множество изменений в области пакетной и потоковой обработки. В частности, добавлен новый пакетный Streaming Warehouse...
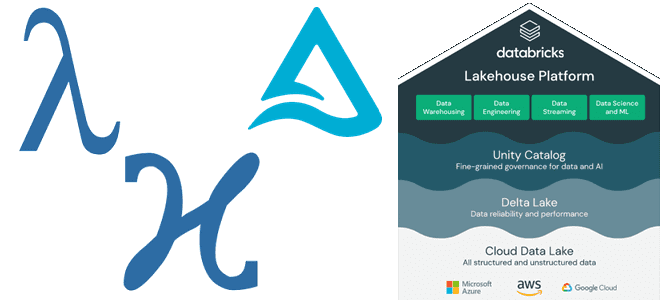
Как Lakehouse объединяет пакетную и потоковую обработку, какие проблемы возникают при реализации этой гибридной архитектуры данных и каким образом они решаются с помощью Delta-подхода и Apache Spark Structured Streaming. Краткая история появления дельта-архитектуры от лямбда- и каппа-моделей Мир больших данных постоянно развивается: появляются новые технологии и архитектурные шаблоны. В частности,...

Что общего у Apache HBase с Google Bigtable, чем они отличаются и какую NoSQL-СУБД выбирать для практического использования. Чем похожи NoSQL-хранилища для больших данных Apache HBase часто называют Google BigTable для Hadoop, поскольку она обеспечивает аналогичные возможности и использует многие концепции этой облачной NoSQL-СУБД. В частности, именно Bigtable был выпущен...
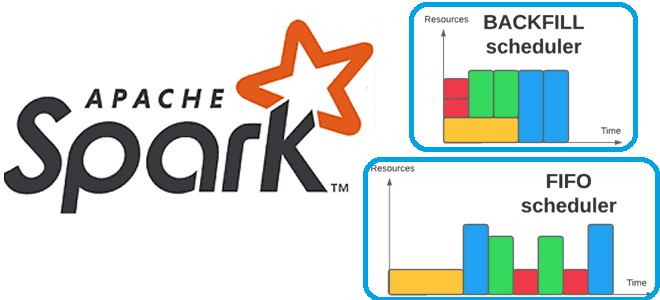
Что такое backfill-операции в конвейерах заданий Apache Spark, чем они отличаются от исторического заполнения датасетов, зачем их автоматизировать и как это сделать. Что такое backfilling для заданий Apache Spark Мы уже писали про понятие backfill на примере модификации DAG при добавлении новых заданий в конвейер Apache AirFlow. Эта функция полезна,...
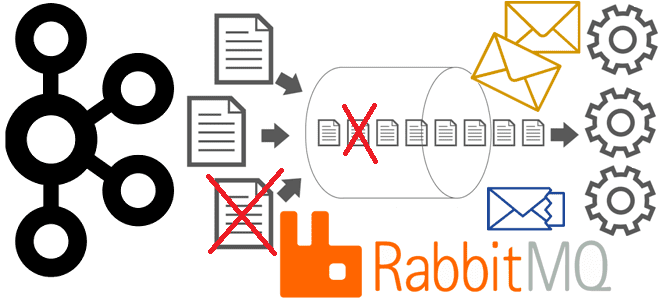
Сегодня рассмотрим, зачем в системах асинхронного обмена данными нужны очереди недоставленных сообщений, как их организовать и обработать. Разбираемся с Dead Letter Queue на примере Apache Kafka и RabbitMQ. Обработка недоставленных сообщений в Apache Kafka Хотя Apache Kafka и RabbitMQ не являются взаимозаменяемыми альтернативами, именно эти системы чаще всего используются для...
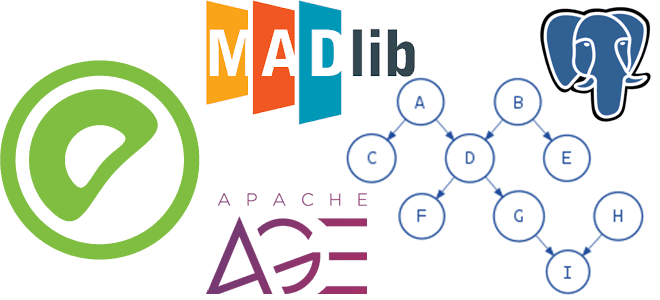
Инструменты графовых алгоритмов для аналитики больших данных в PostgreSQL и Greenplum: обзор расширений и возможностей. Знакомимся с Apache AGE и MADlib. Графовая аналитика в PostgreSQL Реляционные СУБД отлично подходят для хранения данных с четкой структурой практически в любой предметной области и предлагают широкие возможности аналитической обработки таких данных. Но иногда реляционная...

Мы уже писали, как можно развернуть контейнерные приложения Apache Flink для обработки больших объемов данных в реальном времени. В продолжение этой темы сегодня сравним развертывание Flink-заданий в Kubernetes и в кластере AWS EMR. Flink-приложение в Kubernetes: преимущества и недостатки Apache Flink — это мощный фреймворк с открытым исходным кодом для...
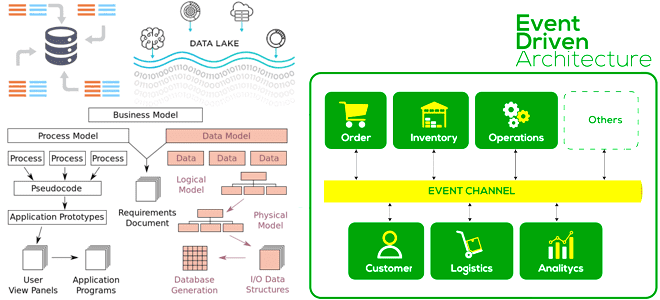
Чем схема, применяемая к данным, при чтении отличается от схемы при записи, почему она вызывает GIGO-проблему в Data Lake, и как применить принципы функциональной дата-инженерии к архитектуре данных, управляемой событиями. Схема при чтении или при записи: главное отличие NoSQL-решений от реляционных СУБД NoSQL-решения и Apache Hadoop реализуют стратегию «схема при...

Сегодня на примере Apache HBase и Redis разберемся со сходствами и отличиями NoSQL-СУБД типа «семейство колонок» и «ключ-значение». Что между ними общего и что выбирать для практического использования в зависимости от сценариев применения. 3 типа NoSQL-хранилищ данных Apache HBase и Redis являются довольно популярными базами данных среди NoSQL-решений. Однако, они...

Как организовать эффективное планирование заданий Apache Spark в микросервисной архитектуре, управляемой событиями, с помощью паттернов Idempotent Consumer и Transactional Outbox. Проблемы оркестрации Spark-заданий shell-скриптами и переход к EDA-архитектуре При большом количестве приложений Apache Spark, которые взаимодействуют друг с другом как самостоятельные микросервисы, растет сложность управления ими. В частности, shell-скрипты позволяют...
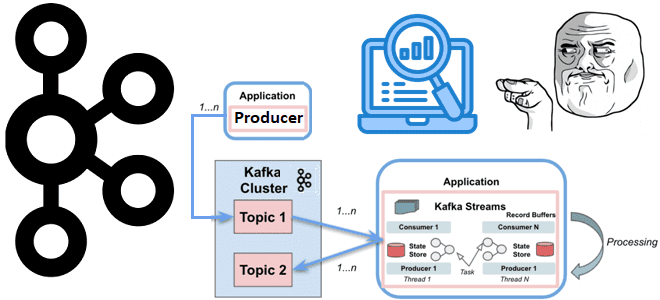
Как использовать один и тот же топик Kafka для источника и назначения данных, обеспечивая высокую пропускную способность и низкую задержку приложений Kafka Streams. А также рассмотрим, какие встроенные метрики приложений есть у Kafka Streams, как добавить свои собственные и с помощью каких инструментов их отслеживать в реальном времени. Топики и...