
Мы уже рассказывали про общие достоинства и недостатки облачных Hadoop-кластеров для проектов Big Data и сравнивали локальные дистрибутивы. В продолжение этой темы, в сегодняшней статье мы подготовили для вас сравнительный обзор наиболее популярных PaaS/IaaS-решений от самых крупных иностранных (Amazon, Microsoft, Google, IBM) и отечественных (Яндекс и Mail.ru) провайдеров [1]. Сравнение...

Продолжая опровергать мифы о Hadoop, сегодня мы расскажем о том, как и где создать облачный кластер для Big Data и почему это выгодно. Концепция облачных вычислений стала популярна с 2006 года благодаря компании Amazon и постепенно распространилась на использование внешних платформ и инфраструктуры как сервисов (Platform as a Service, PaaS,...
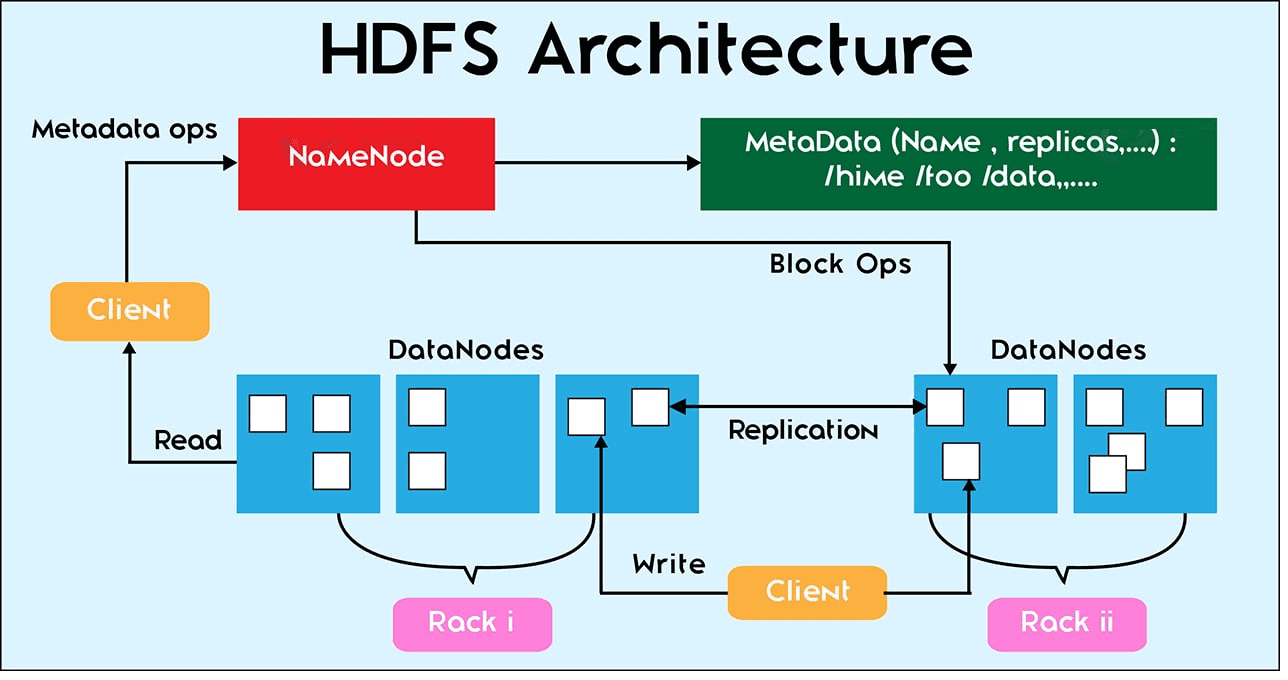
Мы уже рассказывали, как большие данные (Big Data) сохраняются на диск. Сегодня поговорим о других файловых операциях в HDFS: репликации, чтении и удалении данных. За все файловые операции в Hadoop Distributed File System отвечает центральная точка кластера – сервер имен NameNode. Сами операции с конкретными файлами выполняются на локальном узле...
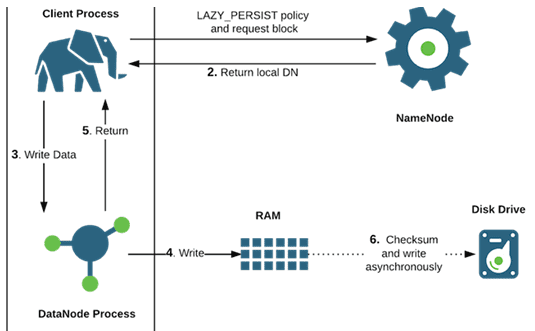
HDFS предназначена для больших данных (Big Data), поэтому размер файлов, которые хранится в ней, существенно выше чем в локальных файловых системах – более 10 GB [1]. Продолжая тему файловых операций и взаимодействия компонентов Hadoop Distributed File System, в этой статье мы расскажем, как осуществляется запись таких больших файлов с учетом блочного...

Благодаря архитектурным особенностям распределенной файловой системы Hadoop, допустимые файловые операции в ней отличаются от возможных действий с файлами на локальных системах. В этой статье мы рассмотрим файловые операции в HDFS и взаимодействие ее компонентов: узлов данных и сервера имен с клиентами - пользователями или приложениями. Файловые операции HDFS В отличие...

Сегодня мы поговорим о заблуждениях насчет базового инфраструктурного понятия хранения и обработки больших данных – экосистеме Hadoop и развеем 3 самых популярных мифа об этой технологии. А также рассмотрим применение Cloudera, Hortonworks, Arenadata, MapR и HDInsight для проектов Big Data и машинного обучения (Machine Learning). Миф №1: Hadoop – это...

Интернет вещей (Internet Of Things) считает покупателей торговых центров, а средства больших данных (Big Data) и машинного обучения (Machine Learning) превращают эти цифры в реальную выгоду для бизнеса. Мы нашли еще 5 примеров успешного использования этих технологий в ритейле и делимся с вами опытом отечественных и зарубежных компаний. Интернет вещей...

Мы уже описывали, как американская торговая сеть Macy’s успешно использует интернет вещей (Internet Of Things) для персонализированного маркетинга. Bluetooth-маячок определяет местоположение посетителя в магазине с точностью до нескольких сантиметров и подает сигнал в корпоративную CRM-систему. CRM отправляет клиенту на смартфон предложение со скидкой на товар, ближайший к потребителю в данный момент [1]. Сегодня мы...

Мы уже рассказывали, зачем HR-специалисту большие данные, как Big Data и Machine Learning помогают PR-менеджеру в управлении корпоративной репутацией, а маркетологу в формировании персональных рекламных предложений. Сегодня поговорим об одном из средств реализации этих и других бизнес-задач – языке программирования R и рассмотрим 7 причин, почему вам необходимо освоить этот...

Недавно мы рассказывали, зачем HR-специалисту большие данные, как быстро и эффективно внедрить Big Data в управление персоналом, а также описывали случаи интеллектуального рекрутинга с помощью машинного обучения. В продолжение этой темы сегодня мы приготовили для вас 5 интересных кейсов от отечественных и зарубежных компаний по 3 HR-направлениям: управление талантами, повышение...

Мы уже описывали, зачем HR-специалисту большие данные, а также как быстро и эффективно внедрить Big Data в управление персоналом на практике. Сегодня расскажем о конкретных случаях применения этих технологий в HR: успешные кейсы отечественных и зарубежных компаний. Роботы-рекрутеры Сервис автоматизированного рекрутинга, разработанный российской компанией Stafory, позволяет в 10 раз сократить...

Как быстро и эффективно внедрить Big Data и Machine Learning в прикладную область бизнеса для решения практических задач, избежав популярных ошибок Data Scientist - разбираемся на примере HR-направления. Подготовка к внедрению Big Data в HR и не только Зачем HR-специалисту большие данные и какую пользу они принесут управленческим процессам и...

Как измерить управленческий опыт, предсказать и предотвратить профессиональное выгорание, быстро найти подходящего кандидата и сформировать высокоэффективную команду с помощью Big Data – разбираемся в HR-аналитике и других важных вопросах «умного» управления персоналом. Откуда в HR большие данные ? Согласно исследованию аудиторской компании KPMG, Big Data используются примерно в 60% HR-департаментов различных организаций...

Сегодня большие данные и технологии распределенного реестра до сих пор являются самыми популярными ИТ-темами. Возможности их внедрения в каждую прикладную сферу, от банковской отрасли до медицины, обсуждаются на конференциях всех уровней, корпоративных совещаниях и государственных советах [1]. Принесет ли объединение Big Data и блокчейн дополнительные бонусы, в каких случаях не...

Иван Гуз, директор по аналитике и клиентскому сервису Avito, 24.04.2018 на митапе AI Community и AI Today для специалистов по Data Science в офисе компании [1] рассказал о самых главных проблемах, которые подстерегают исследователя данных на практических проектах и от чего не убережет даже подробно проработанный стандарт CRISP-DM. Из его...

Посмотрев выступление Станислава Гафарова [1], руководителя направления по развитию ИТ-систем АО «СберТех», от 24.04.2018 на митапе AI Community и AI Today для специалистов по Data Science в офисе Авито [2], мы составили ТОП-7 ошибок при работе с данными по методологии CRISP-DM. На основании жизненного цикла работы с информацией по стандарту...

Как большие данные и машинное обучение меняют современные аэропорты, обеспечивая безопасность, повышая продажи, управляя движением пассажиропотоков и самолетов: какие технологии успешно используется и что нас ждет в будущем – смотрим кейсы внедрения Big Data и Machine Learning в отечественных и зарубежных аэровокзалах. 1. Большие данные и машинное обучение обеспечивают безопасность...

Как большие данные и машинное обучение используется авиакомпаниями и аэропортами для обеспечения безопасности полетов, технического обслуживания самолетов и изучения клиентских предпочтений: разбираемся на примерах внедрения технологий Big Data и Machine Learning в отечественную и зарубежную авиаиндустрию. 1. Большие данные для обеспечения безопасности полетов, взлетов и посадок Технологии Big Data позволяют...

Как начинается цифровая трансформация, что и в какой последовательности необходимо сделать, чтобы корпоративная цифровизация завершилась успехом – разбираем этапы работ: от планирования к реализации. 1. Нарисуйте идеальный портрет своего цифрового предприятия Чтобы цифровизация не превратилась в банальную автоматизацию текущей деятельности (чем отличаются эти 2 понятия, мы подробно рассказывали здесь), необходима...

Правда ли, что Большие Данные – это сложно, долго, дорого и нужно далеко не всем: анализируем и опровергаем причины отказа от использования Big Data в бизнесе любого масштаба, от крупного до малого. 1. Большие данные нам не актуальны Даже если вы производите товары вручную или оказываете индивидуальные услуги, для вас...