
В предыдущей статье мы анализировали текущее состояние промышленного интернета вещей (Industrial Internet of Things, IIoT) на отечественном рынке и рассматривали наиболее перспективные направления развития этого технологического стека. Сегодня мы поговорим про специфические для нашей страны проблемы, которые сдерживают наступление 4-ой промышленной революции (Industry 4.0, I4.0) в России. Основные причины задержки...
Продолжая разговор про мировые тренды развития промышленного интернета вещей (Industrial Internet of Things, IIoT), сегодня мы рассмотрим перспективы отечественного IIoT, а также проанализируем текущее развитие Big Data, Machine Learning и других ключевых технологий 4-ой промышленной революции (Industry 4.0, I4.0) в России. Промышленный интернет вещей в России: 3 главные перспективы Прежде...

В этой статье мы расскажем о 4-ой промышленной революции и прорывных технологиях, показанных на крупнейшей промышленной выставке Hannover Messe-2019: что такое коботы, цифровые близнецы и CMMS-системы, а также как все это связано с Big Data и Industrial Internet of Things. 4-я промышленная революция: что это такое и как она связана...
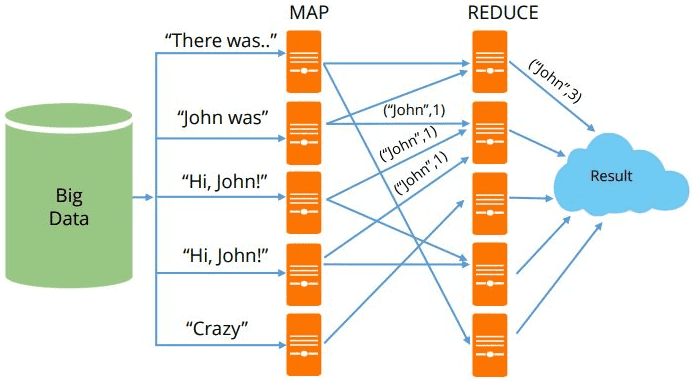
MapReduce можно назвать основой Big Data, т.к. именно данная технология позволяет обрабатывать огромные массивы информации параллельно в распределенных кластерах. Эту вычислительную модель поддерживают множество различных коммерческих и свободных продуктов: Apache Hadoop, Spark, Greenplum, Hive, MongoDB, Phoenix, DryadLINQ и прочие Big Data фреймворки и библиотеки, написанные на разных языках программирования [1]. Сегодня...

Проанализировав сходства и различия пяти самых популярных Big Data фреймворков для распределенных потоковых вычислений (Apache Kafka Streams, Spark Streaming, Flink, Storm и Samza), в этой статье мы сравним их по 10 критериям и отметим, какие именно факторы являются наиболее значимыми для объективного выбора. Сравнительный анализ самых популярных фреймворков потоковой обработки...

В этой статье мы рассмотрим, чем похожи и чем отличаются 5 самых популярных инструментов распределенной обработки потоков Big Data: Apache Kafka Streams, Spark Streaming, Flink, Storm и Samza, а также поговорим про наиболее значимые факторы выбора между этими программными средствами. 5 общих характеристик распределенных Big Data фреймворков потоковой обработки Прежде...

Apache Samza часто сравнивают с другими Big Data фреймворками распределенных потоковых вычислений в реальном времени (Real Time, RT): Kafka Streams, Spark Streaming, Flink и Storm. Apache Spark и Flink обладают практически одинаковым набором функциональных возможностей и компонентов, поэтому их можно сравнивать между собой более-менее объективно. Apache Samza является более простой...

Apache Storm (Сторм, Шторм) часто употребляется в контексте других BigData инструментов для распределенных потоковых вычислений в реальном времени (Real Time, RT): Spark Streaming, Kafka Streams, Flink и Samza. Однако, если Apache Spark и Flink по функциональным возможностям и составу компонентов еще могут конкурировать между собой, то сравнивать с ними Шторм,...

Flink часто сравнивают с Apache Spark, другим популярным инструментом потоковой обработки данных. Оба этих распределенных отказоустойчивых фреймворка с открытым исходным кодом используются в высоконагруженных Big Data приложениях для анализа данных, хранящихся в кластерах Hadoop [1] и других кластерных системах. В этой статье мы поговорим, чем похожи и чем отличаются Флинк и Спарк, а...

Проанализировав сходства и различия Apache Kafka Streams и Spark Streaming, можно сделать некоторые выводы относительно выбора того или иного решения в качестве основного инструмента потоковой обработки Big Data. В этой статье мы собрали для вас аргументы в пользу Кафка Стримс и Спарк Стриминг в конкретных ситуациях, а также нашли некоторые...

Сегодня мы рассмотрим популярные Big Data инструменты обработки потоковых данных: Apache Kafka Streams и Spark Streaming: чем они похожи и чем отличаются. Стоит сказать, что Спарк Стриминг и Кафка Стримс – возможно, наиболее популярные, но не единственные средства обработки информационных потоков Big Data. Для этой цели существует еще множество альтернатив,...

В этой статье мы продолжим говорить про основы Apache Kafka Streams для начинающих и рассмотрим одно из самых важных свойств Кафка – возможность обработки любых данных, накопленных с начала работы Big Data системы. Что такое окна Apache Kafka Streams и зачем они нужны Кафка обеспечивает объективную достоверность накопленных исторических данных...
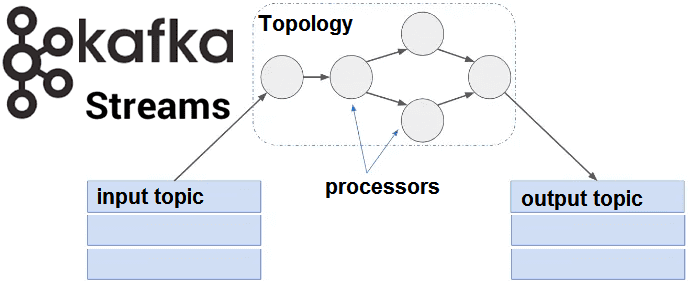
Как мы уже писали, в Apache Kafka Streams таблица и поток данных – это базовые и взаимозаменяемые понятия. Сегодня поговорим о том, как работать с этими объектами Big Data с помощью внутренних средств Кафка Стримс, используя готовые методы высокоуровневого языка DSL и низкоуровневый API-интерфейс для распределенной обработки потоковых данных в...
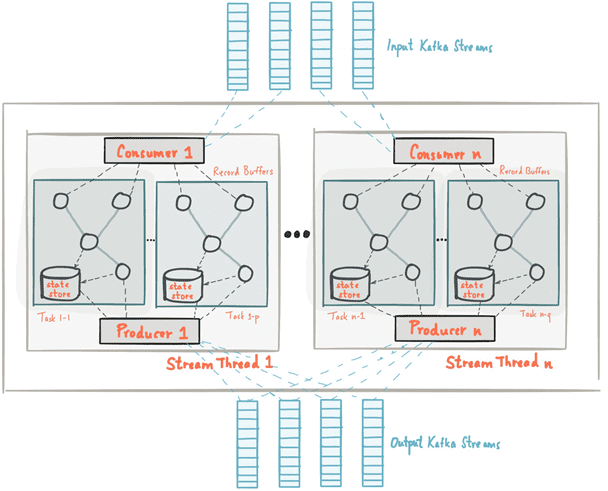
В продолжение темы про основы Apache Kafka Streams для начинающих, сегодня мы поговорим про то, как абстрактные понятия топика (topic), таблицы (table) и потока (stream) позволяют распараллелить обработку информационных потоков. Читайте в нашем новом материале, что такое обработчики потоков Кафка Стримс, как они обрабатывают разделы топиков (topic partition) Kafka и...
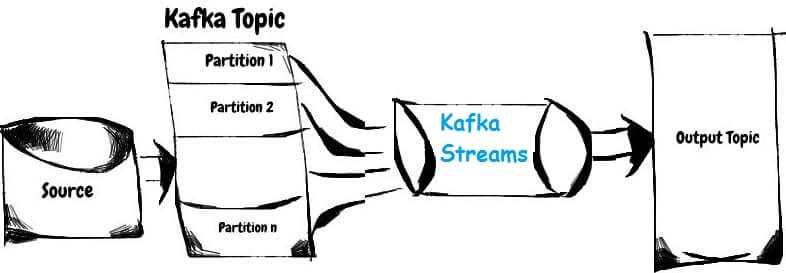
Сегодня мы поговорим про базовые понятия Apache Kafka Streams: потоки, таблицы и топики Кафка. Читайте в нашей статье, как Stream, Table и Topic связаны между собой, чем они похожи, когда таблица становится потоком и почему это обеспечивает эластичность и отказоустойчивость распределенных потоковых приложений Big Data. Что такое таблица, топик и...
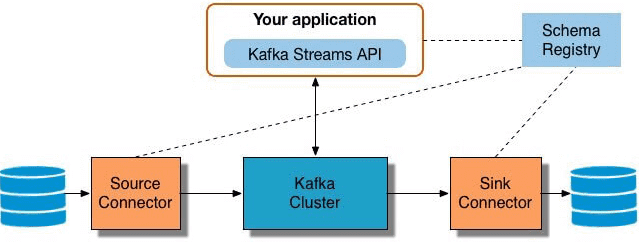
Мы уже рассказывали про Apache Kafka Streams API. В продолжение этой темы, сегодня отметим ключевые преимущества этой технологии, особенно важные для DevOps-инженера и разработчика Big Data систем, а также поговорим про некоторые недостатки и возможные альтернативы Кафка Стримс API. 5 главных достоинств Apache Kafka Streams API Для DevOps-инженера Big Data...
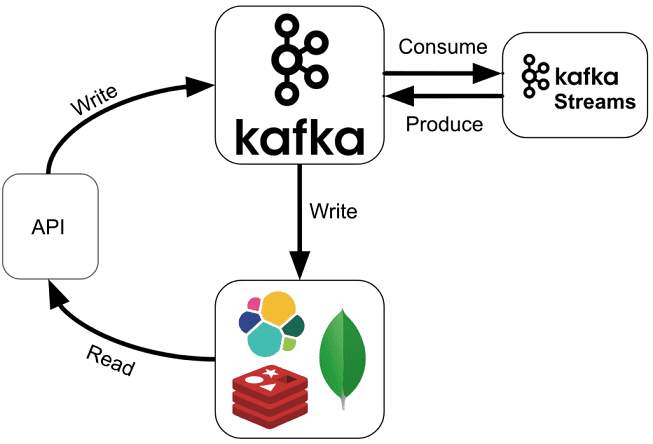
Продолжая разговор про Apache Kafka Streams, сегодня мы расскажем, как API этой мощной библиотеки упрощает жизнь DevOps-инженеру и разработчику Big Data систем. Читайте в нашей статье, как Kafka Streams API эффективно обрабатывать большие данные из топиков Кафка на лету без использования Apache Spark, а также быстро создавать и развертывать распределенные...

Читайте в нашей сегодняшней статье, как Apache Kafka Streams помогает быстро создавать приложения для обработки потоков Big Data без кластера Кафка, работать с состояниями распределенных программ без базы данных, эффективно тестировать и разворачивать потоковые микросервисы согласно DevOps-подходу, а также реальные кейсы практического применения этой технологии. Что такое Apache Kafka Streams...

Мы уже рассказывали, как машинное обучение (Machine Learning) и большие данные (Big Data) помогают бизнесу сделать свои маркетинговые кампании персональными и оптимизировать рекламный бюджет. В этой статье рассмотрим, как метеоусловия влияют на маркетинг и каким образом бизнес может заработать на использовании данных об этих внешних условиях. Как погода влияет на...

Продолжая разговор про форматы Big Data файлов, сегодня мы рассмотрим разницу между линейными и колоночными типами, а также расскажем о том, как выбирать между AVRO, Sequence, Parquet, ORC и RCFile при работе с Apache Hadoop, Kafka, Spark, Flume, Hive, Drill, Druid и других средствах работы с большими данными. Итак, форматы...