Рассказав о том, как машинное обучение работает в разных задачах cybersecurity, сегодня мы собрали для вас 5 примеров реального использования Machine Learning в информационной безопасности. Также в этой статье мы рассмотрим, способны ли эти методы искусственного интеллекта заменить существующие инструменты защиты данных и почему. Где и как машинное обучение используется...

Сегодня мы расскажем, как машинное обучение (Machine Learning, ML) используется в информационной безопасности для защиты данных от утечек, несанкционированного доступа, неправомерного использования пользовательских привилегий, вирусных атак и прочих угроз cybersecurity. Читайте в нашей статье, как нейросети и другие ML-модели выявляют мошеннические операции и другие аномалии в Big Data системах и...

Продолжая разговор о том, что такое цифровой двойник и где эта технология Industry 4.0 используется на практике, сегодня мы рассмотрим несколько реальных примеров такой цифровизации в отечественной и зарубежной промышленности. Читайте в нашей статье про практическую синергию технологий Big Data, ML, PLM и IIoT в нефтегазовой, теплоэнергетической и машиностроительной отраслях....

В этой статье мы разберем, что такое цифровой двойник – один из главных трендов развития 4-ой промышленной революции (Industry 4.0) на ближайшие 5 лет. Читайте в сегодняшнем материале, зачем нужен виртуальный макет завода, из чего состоит информационная модель изделия и где используются цифровые двойники. Также рассмотрим, как CALS- и PLM-технологии...

Сегодня мы расскажем, почему и зачем сейчас почти все сайты собирают cookies, что такое GDPR, как банки собираются оценивать кредитоспособность потенциального заемщика по истории его запросов в браузере и насколько это легально. Читайте в нашей статье про персональные данные, синергетический эффект технологий Big Data и финансовый скоринг на основе пользовательского...

На пороге 3-го десятилетия 21 века пришло время подвести итог прошедшим годам и cделать прогнозы на будущее. В этой статье мы поговорим о ключевых событиях минувших лет, помечтаем о том, что ждет Big Data и чего нам принесет эта ИТ-область. Также поделимся с вами своими планами на 2020 год: расскажем...
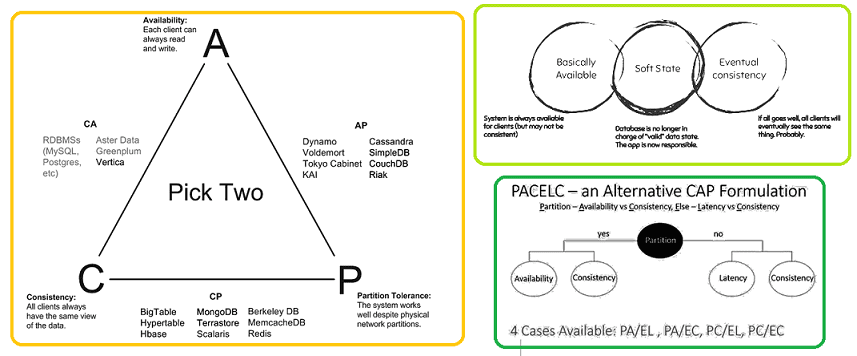
В этой статье мы расскажем про краеугольный камень распределенных Big Data систем – CAP-теорему, в которой одновременно возможно реализовать только 2 свойства из 3-х, по аналогии с треугольником ограничений в проектном менеджменте «Быстро-Качественно-Дешево». Также рассмотрим, за что критикуют модель CAP и почему современные NoSQL-СУБД стоит рассматривать с позиций BASE и...

Рассмотрев ключевые сходства и различия Cassandra и HBase, сегодня мы поговорим, в каких случаях стоит выбирать ту или иную нереляционную СУБД для обработки больших данных (Big Data) в NoSQL-хранилище. Где используются NoSQL-СУБД в Big Data Прежде всего отметим основные области применения рассматриваемых нереляционных СУБД. Проанализировав наиболее известные примеры использования (use...

Cassandra и HBase считаются наиболее популярными NoSQL-СУБД в мире Big Data. Сегодня мы поговорим, что между ними общего и чем отличаются эти нереляционные базы данных, сравнив их по 10 ключевым параметрам: от архитектуры до инструментальных средств. Что общего между Apache Cassandra и HBase: 5 главных сходств Прежде всего отметим, чем...

Продолжая разговор про примеры практического использования Apache Cassandra в реальных Big Data проектах, сегодня мы расскажем вам о рекомендательной системе стримингового сервиса Spotify на базе этой нереляционной СУБД в сочетании с другими технологиями больших данных: Kafka, Storm, Crunch и HDFS. Рекомендательная система Spotify: зачем она нужна и что должна делать...

Благодаря быстроте, надежности и другим достоинствам Apache Cassandra, эта распределенная NoSQL-СУБД широко применяется во многих Big Data проектах по всему миру. В этой статье мы собрали для вас несколько интересных примеров реального использования Кассандры в 5 ключевых направлениях современного ИТ. Где используется Apache Cassandra: 5 главных приложений c примерами Промышленные...
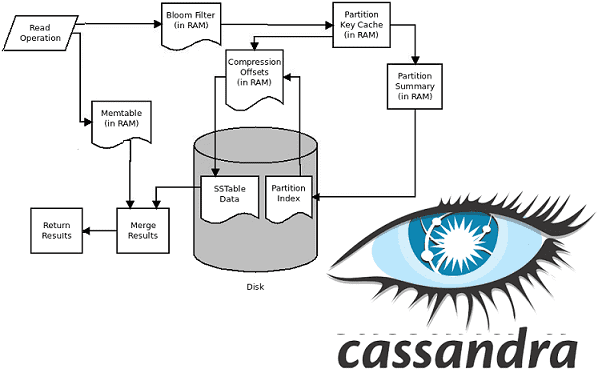
В прошлой статье мы разобрали, как настраиваемые уровни согласованности влияют на скорость работы с данными в Apache Cassandra. Сегодня поговорим, как в этой нереляционной базе данных выполняются операции записи, чтения, уплотнения и удаления. Читайте в нашей статье, что такое memTable, SSTable и Bloom-фильтр, благодаря которым рассматриваемая распределенная NoSQL-СУБД может обработать...
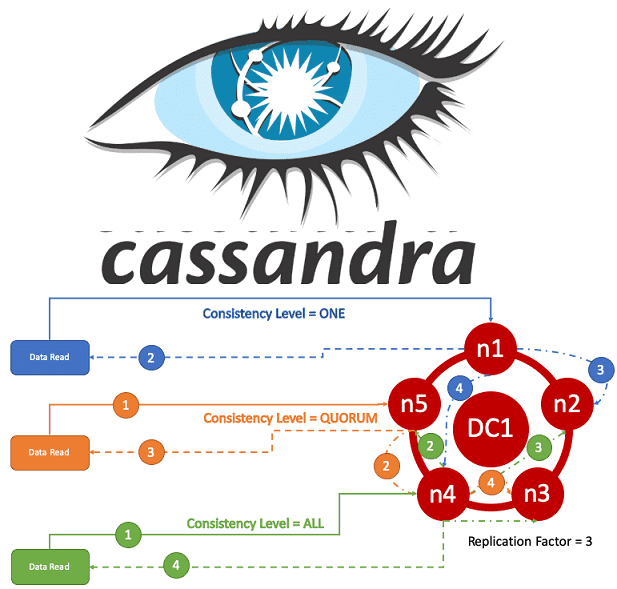
Как мы уже отмечали, одним из преимуществ Кассандры является возможность задания уровня согласованности для операций чтения и записи данных. В этой статье рассмотрим, какие бывают уровни согласованности для этих процессов в Apache Cassandra, и как они влияют на скорость работы распределенной NoSQL-СУБД при ее эксплуатации в реальных Big Data проектах....

Продолжая тему нереляционных хранилищ данных, сегодня мы поговорим о главных плюсах и минусах Apache Cassandra. Читайте в нашем материале, чем хороша эта отказоустойчивая распределенная NoSQL-СУБД и с какими проблемами можно столкнуться при ее использовании в реальном Big Data проекте. Чем хороша Кассандра: 10 ключевых преимуществ Начнем с положительных моментов. Благодаря...

В этой статье мы поговорим про ключевые достоинства и недостатки Apache HBase, а также рассмотрим наиболее интересные примеры практического использования этой нереляционной распределенной СУБД в крупных Big Data проектах. Достоинства и недостатки одной из самых популярных NoSQL СУБД для Big Data Прежде всего, отметим, что Apache HBase и Cassandra считаются...

Сегодня мы рассмотрим еще один инструмент стека SQL-on-Hadoop: Apache Phoenix, позволяющий выполнять SQL-запросы к нереляционной СУБД HBase. Читайте в нашей статье, что представляет собой этот исполнительный механизм, как он работает и чем отличается от других Big Data решений подобного класса (Cloudera Impala, Apache Hive и Drill). Также мы собрали для...

Cloudera Impala – далеко не единственное SQL-решение для быстрой обработки больших данных (Big Data), хранящихся в среде Hadoop. C Impala часто сравнивают Apache Hive, однако они существенно отличаются в плане прикладного использования, как мы уже показали здесь. Гораздо ближе к Impala с точки зрения вычислительной модели и сценариев использования (use...
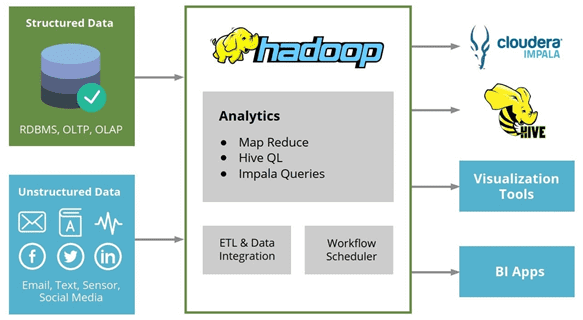
Завершая сравнение SQL-инструментов для больших данных (Big Data), хранящихся в среде Hadoop, сегодня мы рассмотрим аргументы в пользу Apache Hive и Cloudera Impala – когда стоит выбирать ту или иную систему и почему. Также в этой статье мы собрали для вас несколько практических примеров реального использования Импала и Хайв в...

Продолжая тему SQL-on-Hadoop, сегодня мы рассмотрим вопросы обеспечения информационной безопасности в Apache Hive и Cloudera Impala. Читайте в нашем материале, что такое RBAC, в чем специфика cybersecurity больших данных в экосистеме Hadoop и какие средства помогут защитить Big Data при работе с Hive и Impala. Что такое RBAC для SQL-on-Hadoop...

Мы уже разобрали, что общего между Apache Hive и Cloudera Impala. В этой статье рассмотрим работу этих систем с точки зрения программиста, а также поговорим про язык HiveQL. Читайте в сегодняшнем материале, как эти системы выполняют SQL-запросы для аналитики больших данных (Big Data), хранящихся в кластере Hadoop. Что такое HiveQL,...