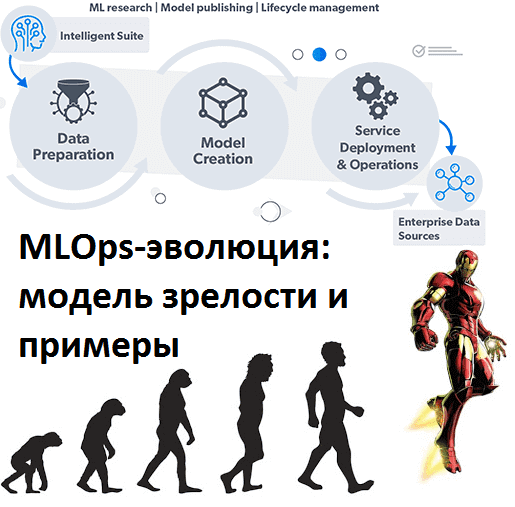
Цифровизация и запуск проектов Big Data предполагают некоторый уровень управленческой зрелости бизнеса, который обычно оценивается по модели CMMI. MLOps также требует предварительной готовности предприятия к базовым ценностям этой концепции. Читайте в нашей статье, что такое Machine Learning Operations Maturity Model – модель зрелости операций разработки и эксплуатации машинного обучения, из...
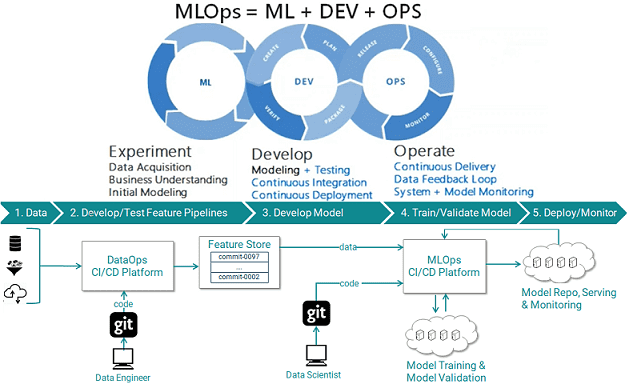
Пока цифровизация воплощает в жизнь концепцию DataOps, мир Big Data вводит новую парадигму – MLOps. Читайте в нашей статье, что такое MLOps, зачем это нужно бизнесу и какие специалисты потребуются при внедрении практик и инструментов сопровождения всех операций жизненного цикла моделей машинного обучения (Machine Learning Operations). Что такое MLOps, почему...
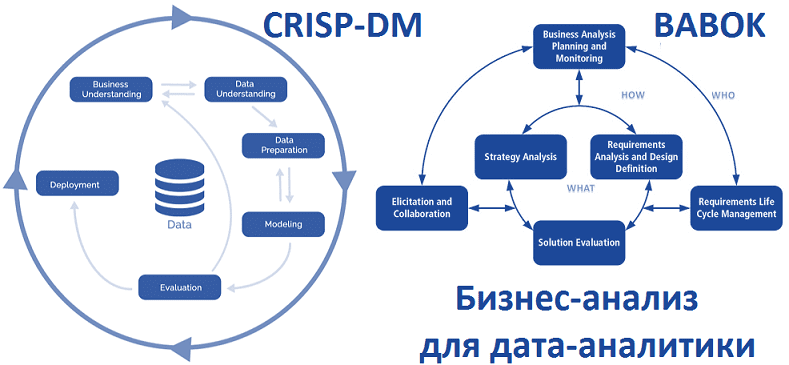
Мы уже рассказывали, что цифровизация и другие масштабные проекты внедрения технологий Big Data должны обязательно сопровождаться процедурами бизнес-анализа, начиная от выявления требований на старте до оценки эффективности уже эксплуатируемого решения. Сегодня рассмотрим, как задачи бизнес-анализа из руководства BABOK®Guide коррелируют с этапами методологии исследования данных CRISP-DM, которая считается стандартом де-факто в...

Самообслуживаемая аналитика больших данных – один из главных трендов в современном мире Big Data, который дополнительно стимулирует цифровизация. В продолжение темы про self-service Data Science и BI-системы, сегодня мы рассмотрим, что такое Cloudera Data Science Workbench и чем это зарубежный продукт отличается от отечественного Arenadata Analytic Workspace на базе Apache...

Продолжая разговор про Apache Zeppelin, сегодня рассмотрим, как на его основе ведущий разработчик отечественных Big Data решений, компания «Аренадата Софтвер», построила самообслуживаемый сервис (self-service) Data Science и BI-аналитики – Arenadata Analytic Workspace. Читайте далее, как развернуть «с нуля» рабочее место дата-аналитика, где место этого программного решения в конвейере DataOps и при...
Недавно мы рассказывали, что такое PySpark. Сегодня рассмотрим, как подключить PySpark в Google Colab, а также как скачать датасет из Kaggle прямо в Google Colab, без непосредственной загрузки программ и датасетов на локальный компьютер. Google Colab Google Colab — выполняемый документ, который позволяет писать, запускать и делиться своим Python-кодом через...

В этой статье мы рассмотрим, что такое Apache Zeppelin, как он полезен для интерактивной аналитики и визуализации больших данных (Big Data), а также чем этот инструмент отличается от популярного среди Data Scientist’ов и Python-разработчиков Jupyter Notebook. Что такое Apache Zeppelin и чем он полезен Data Scientist’у Начнем с определения: Apache...
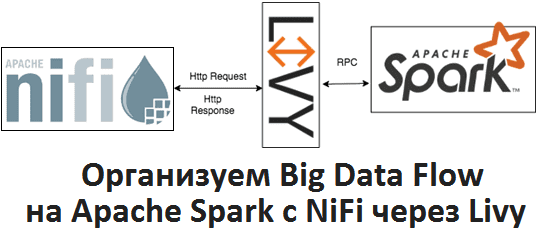
Apache Livy полезен не только при организации конвейеров обработки больших данных (Big Data pipelines) на Spark и Airflow, о чем мы рассказывали здесь. Сегодня рассмотрим, как организовать запланированный запуск пакетных Spark-заданий из Apache NiFi через REST-API Livy, с какими проблемами можно при этом столкнуться и что поможет их решить. Что...

Продолжая разговор про Apache Livy, сегодня мы сравним этот REST API для Spark c другой популярной Big Data системой планирования рабочих процессов для управления заданиями Hadoop – Oozie. Читайте в нашей статье, что такое Apache Oozie, чем он похож на Livy и в чем между ними разница, а также когда...
Вчера мы рассказывали про особенности совместного использования Apache Spark с Airflow и достоинства подключения Apache Livy к этой комбинации популярных Big Data фреймворков. Сегодня рассмотрим подробнее, как работает Apache Livy, а также за счет чего этот гибкий API обеспечивает удобство работы с Python-кодом и общие Spark Context’ы для разных операторов...

Python считается из основных языков программирования в областях Data Science и Big Data, поэтому не удивительно, что Apache Spark предлагает интерфейс и для него. Data Scientist’ы, которые знают Python, могут запросто производить параллельные вычисления с PySpark. Читайте в нашей статье об инициализации Spark-приложения в Python, различии между Pandas и PySpark,...

Постоянно обновляя наши курсы «Аналитика больших данных для руководителей» в соответствии с развитием области Big Data и вызовов современного бизнеса, сегодня мы расскажем про наиболее перспективные технологии с точки зрения исследовательского агентства Gartner, а также рассмотрим их влияние на цифровую трансформацию. Читайте в нашей статье, почему цифровой двойник нужен не...

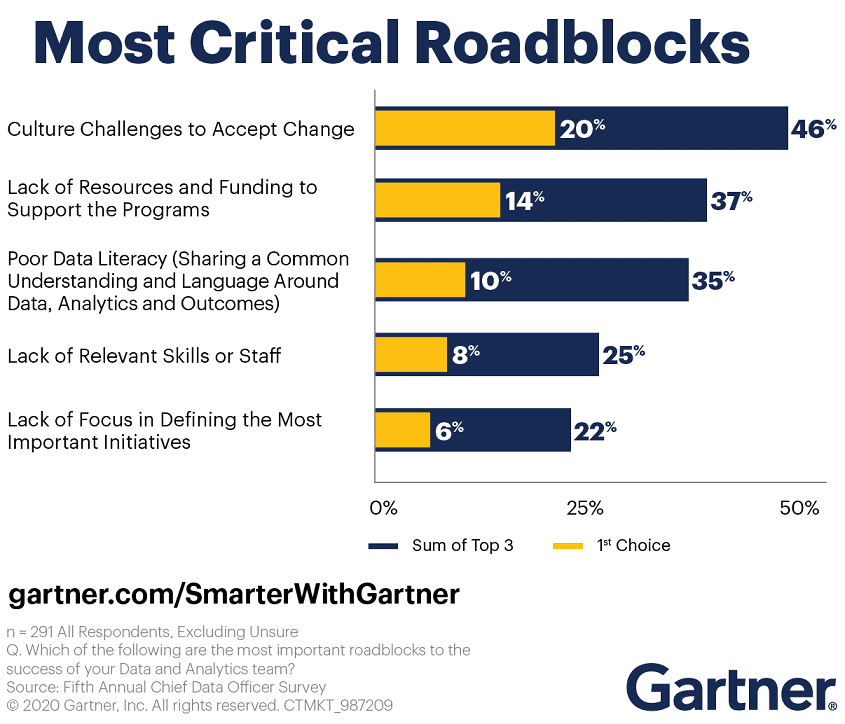
В продолжении темы про текущее состояние и ожидаемые тренды цифровой трансформации отечественных предприятий, сегодня мы рассмотрим, что мешает директору по цифровизации успешно воплощать стратегию корпоративного изменения. Читайте далее, с какими основными трудностями сталкивается Chief Digital Transformation Officer (CDTO) и как их обойти. 5 проблем CDTO: главные факторы, препятствующие цифровой трансформации...

Недавно мы писали про 5 главных факторов, которые сдерживают цифровизацию бизнеса и государства по версии аналитического агентства Gartner. Сегодня поговорим про динамику отечественной цифровой трансформации, рассмотрев соответствующий отчет российского исследовательского бюро KMDA. Читайте в нашей статье, какие отрасли в России могут считать себя data-driven, от чего зависит успех цифровизации и...

Сегодня мы расскажем о важности прикладного бизнес-анализа в проектах Big Data, включая цифровизацию частного бизнеса и государственных предприятий. Читайте в нашей статье, как области знаний профессионального руководства по бизнес-анализу BABOK®Guide соответствуют типовым этапам внедрения технологий больших данных в корпоративную деятельность, и почему цифровая трансформация любой компании – это, прежде всего,...

Продолжая тему тотальной цифровизации и аналитики больших данных в государственных интересах, сегодня мы рассмотрим, как власть хочет поддержать отечественный ИТ-сектор с помощью налоговых маневров, инвестиций в образование и систему грантов. Читайте в нашей статье, как эти мероприятия отразятся на общем бюджете страны и что думает по этому поводу бизнес. Как...

Мы уже писали о преимуществах DaaS-похода, когда облачные провайдеры предоставляют данные как услугу, включая сложную предиктивную аналитику с использованием алгоритмов машинного обучения. Это позволяет быстро и удобно воспользоваться технологиями Big Data без существенных инвестиций в ИТ-инфраструктуру и дорогих специалистов, таких как Data Scientist, инженер и аналитик больших данных. Однако все...

Недавно мы рассказывали, что аналитика больших данных с помощью технологий Big Data – это необязательно удел только крупных корпораций. В этой статье мы рассмотрим реальный бизнес-кейс, как извлечь выгоду из накопленных данных о своих пользователях, применяя для этого возможности NoSQL-СУБД Elasticsearch для полнотекстового поиска по полуструктурированным данным и веб-интерфейс визуализации...
Есть мнение, что использование Apache Kafka в качестве корпоративной сервисной шины (ESB, Enterprise Service Bus) является антипаттерном. Сегодня мы проясним это категоричное утверждение и рассмотрим, как корректно реализовать ESB с помощью Kafka на практическом примере шины данных в компании Avito.ru. Что такое ESB и чем это отличается от брокера сообщений...
Сегодня цифровизация частного бизнеса и государственных предприятий – это не просто часть национальной программы «Цифровая экономика», а фактически новая национальная идея. Однако, не все так гладко: сегодня мы рассмотрим, почему на практике большинство проектов цифровой трансформации терпят неудачи или сталкиваются с существенными трудностями в процессе реализации. Читайте в нашей статье...