
В продолжение темы про новое в экосистеме Apache Hadoop, сегодня мы расскажем о проекте Ozone: как и зачем появилось это масштабируемое распределенное хранилище объектов, чем оно отличается от HDFS, что у него общего с Amazon S3 и как этот фреймворк позволяет совместить преимущества SaaS-подхода с локальными кластерами Big Data. ...

В последнее время в мире Big Data все меньше можно услышать новостей про Apache Hadoop. Сегодня рассмотрим, почему мифы о смерти Хадуп – это всего лишь мифы и как будет развиваться эта мощная экосистема хранения и обработки больших данных в будущем. Читайте в нашей статье про слияния и поглощения ведущих...

Сегодня поговорим про сохранение состояний при потоковой обработке больших данных с помощью Apache Spark и рассмотрим особенности Structured Streaming в новой версии этого популярного Big Data фреймворка. Читайте далее про Stateless и Stateful приложений в реальном времени, управление состояниями, связь DStream с RDD и UI в Spark Structured Streaming. Состояния в...

Мы уже писали, что такое Kafka Connect и как этот инструмент обеспечивает потоковую передачу данных между Apache Kafka и другими системами на примере интеграции с Elasticsearch. Сегодня рассмотрим новый коннектор, который позволяет загружать данные из топиков Apache Kafka в платформу удаленного мониторинга работоспособности мобильных и веб-приложений New Relic через гибкий REST API....
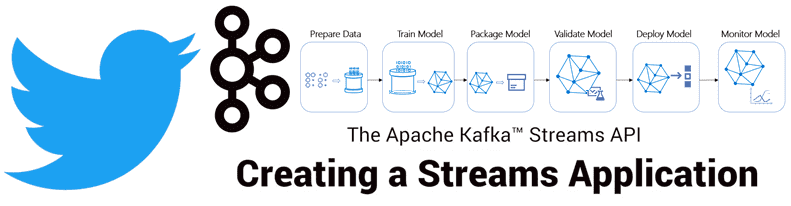
Продолжая разговор про практическое применение Apache Kafka на примере организации рекомендательной системы Twitter, сегодня мы рассмотрим, как с помощью Kafka Streams был разработан конвейер сбора и агрегации данных для машинного обучения (Machine Learning). Читайте в нашей статье про особенности объединения больших данных через LeftJoin и InnerJoin в Apache Kafka Streams. Архитектура приложения...
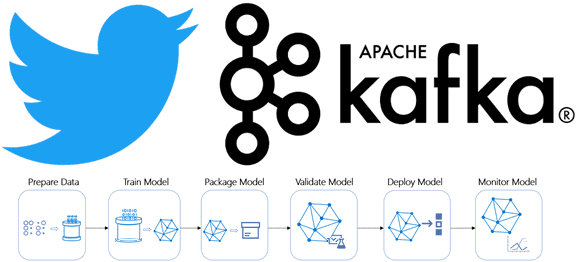
Недавно мы рассказывали про преимущества event-streaming архитектуры с помощью Apache Kafka на примере The New York Times. В продолжение этой темы Apache Kafka, сегодня поговорим про использование этой Big Data платформы в Twitter для построения конвейера потоковой регистрации событий в рекомендательной системе на базе алгоритмов машинного обучения (Machine Learning). Как...

Вчера мы рассказывали про нововведения в Apache Spark 3.0 и упомянули про улучшения в SparkR. Сегодня рассмотрим, почему в новой версии фреймворка вызов пользовательских функций стал быстрее в 40 раз и какие еще проблемы работы с R были решены в этом релизе. Что не так со SparkR: десериализация и особенности...

Чтобы сделать наши курсы по Spark еще более интересными и добавить в них самые актуальные тренды, сегодня мы расскажем о новом релизе этого Big Data фреймворка. Читайте далее, что нового в Apache Spark 3.0 и почему Spark SQL стал еще лучше. 10 лет в Big Data или немного истории В...

Apache NiFi – это простая и мощная система для обработки и распределения больших данных в потоковом режиме, которая отлично справляется с огромными объемами и скоростями, оперируя с сотнями гигабайт и даже терабайтами информации. Однако, на практике при работе с этой Big Data платформой можно столкнуться с проблемой ввода-вывода (IOPS, Input-Output...

Мы уже рассказывали про основные достоинства и недостатки Apache Airflow, с которыми чаще всего можно столкнуться при практическом использовании этого оркестратора конвейеров обработки больших данных (Big Data). Сегодня рассмотрим некоторые специфические ограничения, характерные для этой open-source платформы и способы решения этих проблем на реальных примерах. Все по плану: 5 особенностей...

Сегодня мы продолжим разговор о событийно-процессной архитектуре Big Data систем на примере использования Apache Kafka в The New York Times. Читайте далее, как одно из самых известных американских СМИ с более чем 160-летней историей хранит в Apache Kafka все свои статьи и с помощью API Kafka Streams публикует контент в...

PySpark позволяет работать не только с большими данными (Big data), но и создавать модели машинного обучения (Machine Learning). Сегодня мы расскажем вам о модуле ML и покажем, как обучить модель Machine Learning для решения задачи классификации. Читайте у нас: подготовка данных, применение логистической регрессии, а также использование метрик качеств в...

В этой статье мы поговорим про возможность нехарактерного использования Apache Kafka: не как распределенной стримминговой платформы или брокера сообщений, а в виде базы данных. Читайте далее, как Apache Kafka дополняет другие СУБД, не заменяя их полностью, почему такой вариант использования возможен в Big Data и когда он не совсем корректен....

При всех своих достоинствах Delta Lake, включая коммерческую реализацию этой Big Data технологии от Databricks, оно обладает рядом особенностей, которые могут расцениваться как недостатки. Сегодня мы рассмотрим, чего не стоит ожидать от этого быстрого облачного хранилище для больших данных на Apache Spark и как можно обойти эти ограничения. Читайте далее,...

Продолжая разговор про Delta Lake, сегодня мы рассмотрим, чем это быстрое облачное хранилище для больших данных в реализации компании Databricks отличается от классического озера данных (Data Lake) на Apache Hadoop HDFS. Читайте далее, как коммерческое Cloud-решение на Apache Spark облегчает профессиональную деятельность аналитиков, разработчиков и администраторов Big Data. Больше, чем...

Озеро данных (Data Lake) на Apache Hadoop HDFS в мире Big Data стало фактически стандартом де-факто для хранения полуструктурированной и неструктурированной информации с целью последующего использования в задачах Data Science. Однако, недостатком этой архитектуры является низкая скорость вычислительных операций в HDFS: классический Hadoop MapReduce работает медленнее, чем аналоги на Apache...
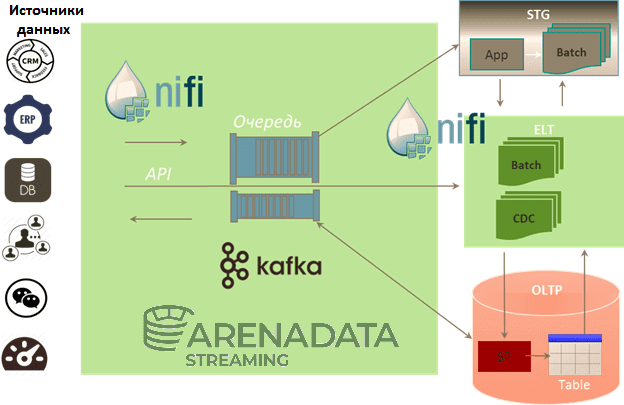
Мы уже рассказывали про преимущества совместного использования Apache Kafka и NiFi. Сегодня рассмотрим, как эти две популярные технологии потоковой обработки больших данных (Big Data) сочетаются в рамках единого решения от отечественного разработчика - Arenadata Streaming. Читайте далее про основные сценарии использования и ключевые достоинства этого современного продукта класса Event Stream...
Завершая цикл статей про MLOps, сегодня мы расскажем про 5 шаблонов практического внедрения моделей Machine Learning в промышленную эксплуатацию (production). Читайте далее, что такое Model-as-Service, чем это отличается от гибридного обслуживания и еще 3-х вариантов интеграции машинного обучения в production-системы аналитики больших данных (Big Data), а также при чем тут...
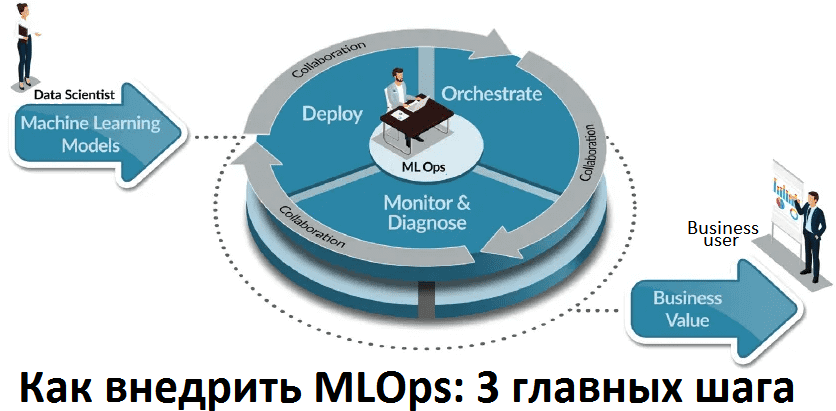
Рассказав, как оценить уровень зрелости Machine Learning Operations по модели Google или методике GigaOm, сегодня мы поговорим про этапы и особенности практического внедрения MLOps в корпоративные процессы. Читайте далее, какие организационные мероприятия и технические средства необходимы для непрерывного управления жизненным циклом машинного обучения в промышленной эксплуатации (production). 2 направления для...
Недавно мы рассказывали про модель зрелости MLOps от Google. Сегодня рассмотрим альтернативную методику оценки зрелости операций разработки и эксплуатации машинного обучения, которая больше похоже на наиболее популярную в области управленческого консалтинга модель CMMI, часто используемую в проектах цифровизации. Читайте далее, по каким критериям измеряется Machine Learning Operations Maturity Model и...