
Чтобы сделать самостоятельное обучение технологиям Big Data по статьям нашего блога еще более интересным, сегодня мы предлагаем вам простой интерактивный тест по основам больших данных, включая администрирование кластеров, инженерию конвейеров и архитектуру, а также Data Science и Machine Learning. Тест по основам больших данных для новичков В продолжение темы,...
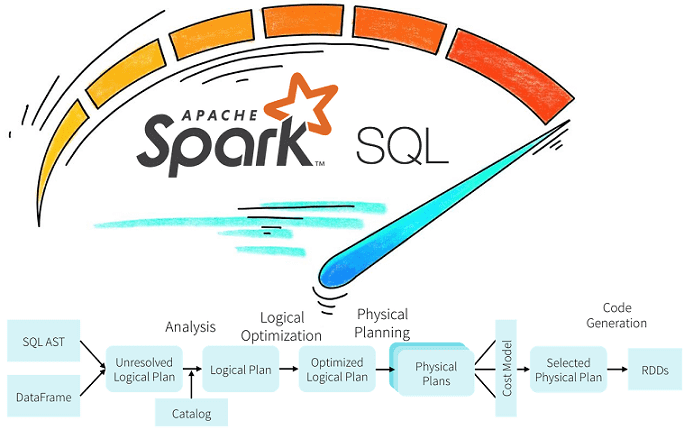
Продолжая разбирать практические особенности аналитики больших данных с Apache Spark, сегодня рассмотрим возможности оптимизации SQL-запросов в этом Big Data фреймворке с помощью механизмов предикатного и проекционного сжатия. Читайте далее про реализацию Predicate Pushdown и Projection Pushdown в Apache Spark 3, а также их связь с форматами Parquet и AVRO. Механизмы...
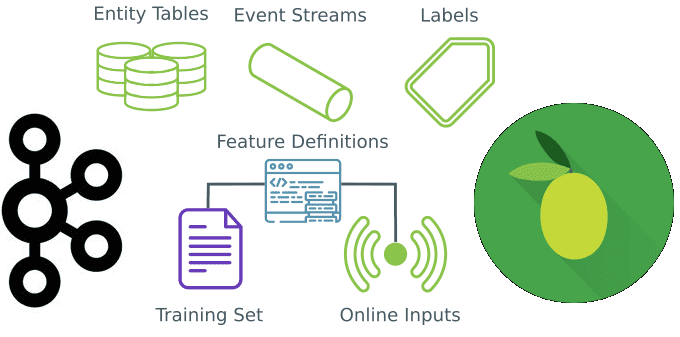
Вчера мы говорили про промышленный Machine Learning в больших данных и рассматривали проблемы микросервисной архитектуры в системах машинного обучения. Продолжая разбирать, как Feature Store повышает эффективность MLOps-процессов, сокращая цикл разработки согласно Agile-идеям, сегодня мы приготовили для вас краткий обзор хранилища признаков StreamSQL. Читайте далее, что такое StreamSQL, как оно устроено,...
Сегодня рассмотрим, когда микросервисные архитектуры не подходят для систем машинного обучения и какие технологии Big Data следует использовать в этом случае. В этой статье мы расскажем, что такое Feature Store, как это хранилище признаков для моделей Machine Learning повышает эффективность MLOps-процессов и сокращает цикл разработки ML-систем, а также при чем...

В этой статье разберем ключевые характеристики идеального конвейера обработки больших данных. Читайте далее, чем отличается Big Data Pipeline, а также какие приемы и технологии помогут инженеру данных спроектировать и реализовать его наиболее эффективным образом. В качестве практического примера рассмотрим кейс британской компании кибербезопасности Panaseer, которой удалось в 10 раз сократить...

В продолжение вчерашнего материала про потоковую аналитику больших данных с Apache Kafka и Spark, сегодня рассмотрим особенности совместного использования этих технологий Big Data. В этой статье мы собрали для вас 5 лучших практик эффективного применения Apache Kafka и Spark Streaming для разработки распределенных приложений аналитики больших данных в режиме реального...

Сегодня поговорим про ETL-процессы в мире Big Data на примере построения непрерывного конвейера поставки больших данных о транзакциях для сервисов машинного обучения. Читайте далее, из чего состоит типичная архитектура такой системы на базе Apache Kafka, Spark, HBase и Hive, а также почему большинство ETL-инструментов не подходят для потоковой передачи событий...

Чтобы добавить в наш новый курс по Apache Kafka для разработчиков еще больше практических примеров, сегодня мы приготовили для вас кейс немецкой железнодорожной компании Deutsche Bahn AG. Читайте далее, почему приложения Kafka Streams заменили Apache Storm и как крупнейшая транспортная компания Германии построила собственную информационную платформу на базе Apache Kafka,...
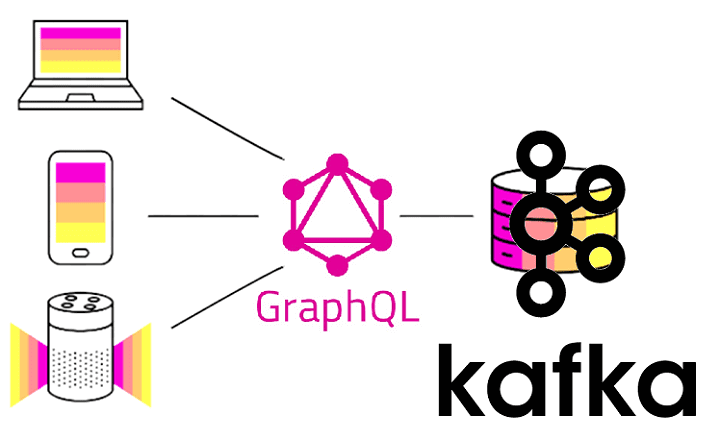
В рамках продвижения нашего нового курса Apache Kafka для разработчиков недавно мы рассматривали RESTful API к этой Big Data платформе потоковой обработки событий на примере Confluent REST Proxy. Сегодня разберем альтернативу REST-интерфейсам в виде GraphQL и применимости этой технологии к разработке распределенных Kafka-приложений. Что такое GraphQL и чем он лучше...
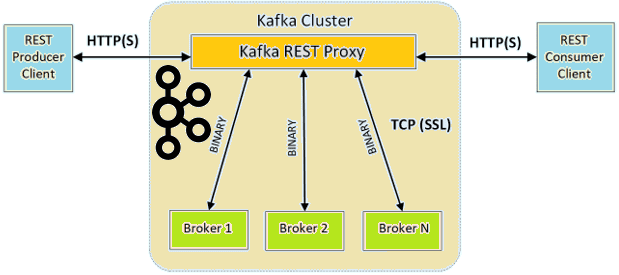
Продолжая разбираться с Confluent REST Proxy для Apache Kafka, сегодня рассмотрим основные достоинства и недостатки этого RESTful API. Читайте далее, что Confluent REST Proxy позволяет делать с Apache Kafka и что ограничивает его взаимодействие с самой популярной Big Data платформой потоковой обработки событий. 6 главных преимуществ RESTful API к...
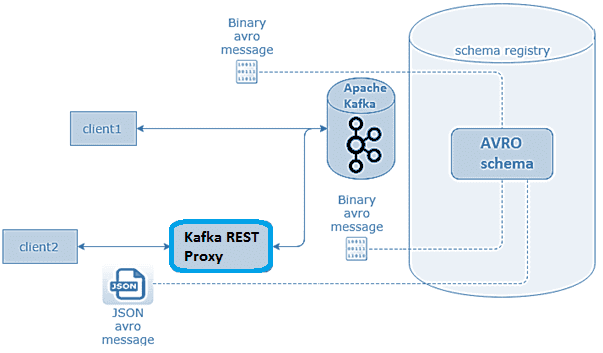
В этой статье разберем, что такое Confluent REST Proxy для Apache Kafka, как работает этот RESTful API, каким образом он связан с облачным сервисом этой популярной Big Data платформой потоковой обработки событий, а также при чем здесь Schema Registry. Основы Confluent REST Proxy для Apache Kafka Широко известная в области...
Сегодня поговорим про обучение Apache Kafka и рассмотрим сценарии применения HTTP и RESTful протоколов в этой Big Data платформе потоковой обработки событий. Читайте далее, чем парадигма request-response отличается от event streaming processing, как связаны REST и HTTP, каковые преимущества RESTful API и где это используется на практике для обработки и...

Продолжая рассказывать про курсы Apache Spark для разработчиков на практических примерах, сегодня рассмотрим, как кэширование данных позволяет оптимизировать распределенные вычисления в этом Big Data фреймворке. Читайте далее, как ускорить выполнение запросов в Spark SQL, чем отличаются функции cache() и persist(), из чего состоит план запроса и каковы альтернативы кэшированию данных...

Говоря про обучение Apache Spark для разработчиков, сегодня мы рассмотрим, как быстро конвертировать Python-скрипты в задания PySpark и какие конфигурационные параметры при этом нужно настроить, чтобы эффективно использовать все возможности распределенных вычислений над большими данными (Big Data). Читайте далее, чем отличаются датафреймы в Pandas и Apache Spark, для чего нужны...

Обработка данных является одной из самых первоочередных задач анализа Big Data. Сегодня мы расскажем о самых полезных преобразованиях PySpark, которые можно выполнить над столбцами. Читайте далее, как привести значения к 0 или 1, как преобразовать из строк в числа и обратно, а также как обработать недостающие значения(Nan) с примерами в...

Развивая наш новый курс по Apache Kafka для разработчиков, сегодня мы рассмотрим 3 способа о взаимодействии с этой популярной Big Data платформой потоковой обработки событий с помощью языка Python, который считается самым распространенным инструментом в Data Science. Читайте далее, что такое librdkafka, чем PyKafka отличается от Kafka-Python и почему решение...

Интерактивная аналитика больших данных - одно из самых востребованных и коммерциализированных приложений для технологий Big Data. В этой статье мы рассмотрим, как крупный британский ритейлер запустил цифровую трансформацию своей ИТ-архитектуры, уходя от традиционного DWH с пакетной обработкой к событийно-стриминговой облачной платформе на базе Apache Kafka и Snowflake. Зачем модному ритейлеру...

Чтобы добавить в наши курсы для дата-инженеров еще больше реальных примеров и лучших DataOps-практик, сегодня мы расскажем, как специалисты крупной норвежской компании DNB обеспечивают надежный доступ к чистым и точным массивам Big Data, применяя передовые методы проектирования данных и реализации конвейеров их обработки. В этой статье мы собрали для вас...

Аналитика больших данных напрямую связана с их качеством, которое необходимо отслеживать на каждом этапе непрерывного конвейера их обработки (Pipeline). Сегодня рассмотрим методы и средства обеспечения Data Quality на примере корпорации Airbnb. Читайте далее про лучшие практики повышения качества больших данных от компании-разработчика самого популярного DataOps-инструмента в мире Big Data, Apache...

Продолжая разговор про обучение Apache Spark для инженеров данных на практических примерах, сегодня разберем, как организовать интеграцию этого Big Data фреймворка с MPP-СУБД Greenplum. В этой статье мы расскажем о коннекторе Greenplum-Spark, который позволяет эффективно связывать эти средства работы с большими данными, выстраивая аналитический конвейер их обработки (data pipeline). Типовые...