
Недавно мы рассказывали про KafkaJS – клиент Apache Kafka для Node.js, который отличается небольшим размером и простым развертыванием с удобным API. Сегодня рассмотрим еще пару полезных инструментов визуализации данных о Kafka-кластере на базе KafkaJS и Prometheus. Читайте далее, что такое FlowKat и Monokl, а также зачем они нужны дата-инженеру, разработчику...
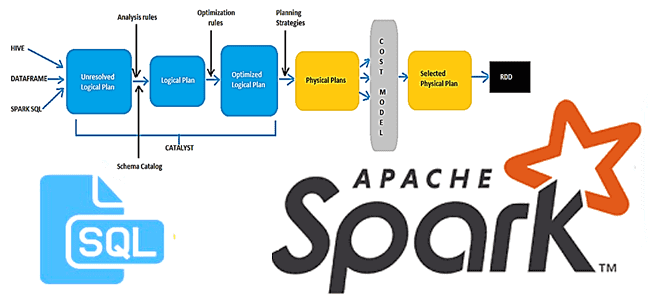
В этой статье для разработчиков Spark-приложений и дата-аналитиков рассмотрим новый оптимизатор этого фреймворка, Radiant. Он основан на SQL-оптимизаторе Catalyst и представляет собой open-source проект от энтузиастов сообщества Apache Spark. Читайте далее, чем хорош Spark-Radiant и как использовать его для оптимизации SQL-запросов при аналитике больших данных. Что такое SQL-оптимизатор Spark-Radiant и...
Сегодня рассмотрим, что такое KafkaJS, как это связано с Apache Kafka и JavaScript, в чем преимущества этой технологии и как разработчику распределенных приложений потоковой аналитики больших данных использовать ее на практике. Также вас ждет краткий ликбез по Node.js и примеры разработки KafkaJS-приложения. Краткий ликбез по Node.js Важными достоинствами архитектуры потоковой передачи...

Хотя наши практические курсы по Greenplum и Arenadata DB больше ориентированы на аналитиков и дата-инженеров, чем на администраторов, в программы обучения также включены важные сведения по настройке этих MPP-СУБД. В этой статье мы собрали лучшие практики системного конфигурирования кластера Greenplum, которые помогут повысить эффективность аналитики больших данных в этой Big...

Реклама является одним из наиболее крупных сегментов практического применения технологий Big Data. Поэтому сегодня рассмотрим, как Flink SQL реализует потоковую аналитику больших данных в AdTech-кейсах. Разбираем пример JOIN-соединения двух потоков событий - показов и кликов, чтобы вычислить конверсию рекламной кампании средствами Apache Flink или Spark. Потоки Big Data за фасадом...
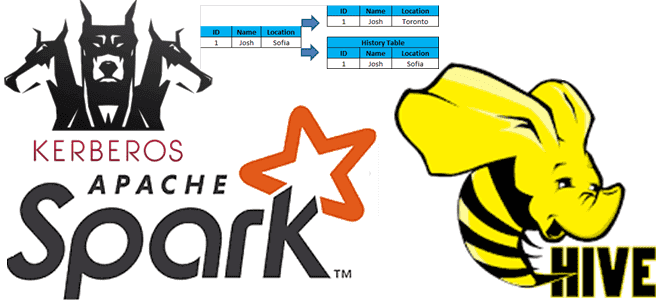
В этой статье для разработчиков распределенных приложений Apache Spark, администраторов SQL-on-Hadoop и дата-аналитиков рассмотрим особенности аутентификации удаленного пользователя, а также отслеживание измененных данных в таблицах Apache Hive. Читайте далее, зачем ограничивать доступ к keytab-файлу в кластерах с поддержкой защищенного протокола Kerberos, а также как реализовать отслеживание медленно меняющихся измерений в...
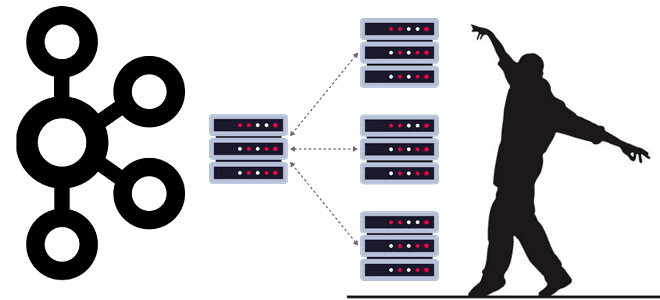
В поддержку курсов по администрированию Apache Kafka, сегодня рассмотрим особенности масштабирования кластера и связанное с этим переназначение разделов. Читайте далее, чем горизонтальное масштабирование лучше вертикального, как переназначить разделы между брокерами Kafka с целью перебалансировки нагрузки и зачем ограничивать полосу пропускания для перемещения реплик между узлами кластера. Проблемы масштабирования кластера Apache...

В рамках обучения разработчиков Spark-приложений, сегодня рассмотрим, как сохранить датафрейм в памяти вне кучи исполнителя и зачем это нужно. Вас ждет краткий ликбез по управлению памятью в Apache Spark с описанием настраиваемых конфигураций. Также на простом практическом примере разберем, как это сделать и где в пользовательском веб-интерфейсе фреймворка посмотреть результаты...

Сегодня рассмотрим, как построить конвейер потоковой обработки событий на Apache Kafka, Flink и SQL Stream Builder с визуализацией результатов в Grafana. Далее вас ждет практический кейс применения технологий Big Data в реальном производстве на примере телеметрии процессов ферментации продуктов в небольшой частной пивоварне. Постановка задачи: бизнес-контекст и используемые технологии В...
Завершая серию статей по IoT-платформе компании Tesla на базе Apache Kafka, сегодня рассмотрим проблемы пиковой загрузки системы и особенности обработки высокоприоритетных событий. Читайте далее, как оптимально определить ключ раздела, чтобы снизить затраты на передачу данных, избежать перегрузки в пиковые моменты и отделить пользователей данных от разработчиков и дата-инженеров. Тонкости обработки...

В этой статье для дата-инженеров мы собрали лучшие практики построения масштабируемых конвейеров обработки данных, а также популярные рекомендации по проектированию ETL/ELT-процессов с Apache Spark, AirFlow и другими технологиями Big Data. Читайте далее, когда ELT лучше ETL и наоборот, чем хорош Apache Spark в конвейерах обработки Big Data, зачем нужен AirFlow,...

В рамках курсов по Apache Hadoop для дата-аналитиков и инженеров данных сегодня рассмотрим пару практических примеров работы с популярным SQL-on-Hadoop инструментом этой экосистемы. Читайте далее, как настроить соединение удаленного сервера Apache Hive к Spark-приложению через JDBC и решить проблему запроса таблицы HBase в Hive вместо повторной репликации данных. Подключение удаленного...

Мы уже упоминали, что Apache Kafka не слишком хорошо обрабатывает сообщения чрезмерно большого размера. Сегодня рассмотрим, как эта проблема решается в конвейерах потоковой обработки IoT-инфраструктуры Tesla. Читайте далее про модификацию синтаксического анализатора данных от множества устройств интернета вещей с поиском компромисса между скоростью и надежностью с помощью коннектора Alpakka к...

При том, что Apache Spark является одной из главных технологий стека Big Data, этот фреймворк не очень хорошо работает с множеством файлов небольшого размера. Поэтому в рамках обучения дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим, почему это происходит, зачем динамически сжимать файлы в Apache Spark и как это делает платформа...

В рамках обучения разработчиков распределенных приложений, сегодня рассмотрим, как упростить тестирование и отладку заданий Apache Flink с помощью Byteman. Читайте далее, как внедрить Java-код в JVM, чтобы извлечь нужные сведения о выполнении Flink-приложения на платформе Veverica и ускорить разработку. Разработка и отладка приложений Apache Flink: ежедневные сложности В рассматриваемом примере...

В предыдущей статье мы говорили о том, как начать работать с Apache Airflow. Сегодня пойдет речь о новом инструменте, появившемся в Airflow 2, — TaskFlow API. Он обеспечивает кросс-коммуникацию между задачами с помощью обычных функций Python. На примере ETL-конвейера мы объясним, как соорудить DAG на основе TaskFlow API, а также...

Продолжая разбирать кейс компании Tesla по организации централизованного управления устройствами интернета вещей (Internet of Things, IoT), сегодня разберем, как выполняется обработка сообщений в топиках Apache Kafka с помощью Confluent Schema Registry и Kafka Streams. Читайте далее, как определить потоковый процессор для парсинга данных в CSV и JSON-форматах с использованием схемы...

Сегодня разберем кейс компании Renault по масштабированию своей цифровой платформы и снижению затрат с помощью BigQuery и Apache Spark на Google Dataproc. Цифровизация в автомобильной промышленности: конвейер сбора и аналитики больших данных с производства средствами Google сервисов и снижение затрат на облако в 2 раза через изменение конфигурации Spark SQL....

В рамках курсов для дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим пример построения системы потоковой передачи для аналитики больших данных на базе Apache Kafka, Spark и Google BigQuery. Читайте далее про Proof of Concept для конвейера продуктовой аналитики, который обрабатывает 50 миллиардов событий каждый день, и какие важные уроки ИТ-архитектор...

Являясь лидером отрасли, IoT-устройства Tesla обрабатывают триллионы событий в день, чтобы повысить эффективность своих электроавтомобилей. Однако, такая производительность была получена не сразу: чтобы достичь ее, инженерам компании пришлось решить множество проблем из области интернета вещей (Internet of Things, IoT). Сегодня рассмотрим, как часть из них была решена с помощью Apache...