
4 октября 2024 года вышел очередной релиз ClickHouse. Знакомимся с его самыми интересными особенностями: добавление строк в обновляемые материализованные представления, агрегатные функции для типов данных JSON и Dynamic, поддержка заголовков HTTP-ответов, автозамена строк с overlay-командами и другие новинки выпуска 24.9. Обновляемые материализованные представления Начнем с наиболее значимой новой функции ClickHouse...

Чем метод applyInPandas() в Spark отличается от apply() в pandas и насколько он быстрее обрабатывает данные: сравнительный тест на датафрейме из 5 миллионов строк. Методы применения пользовательских функций к датафреймам в Spark и pandas Мы уже отмечали здесь и здесь, что Apache Spark позволяет работать с популярной Python-библиотекой pandas, поддерживая...
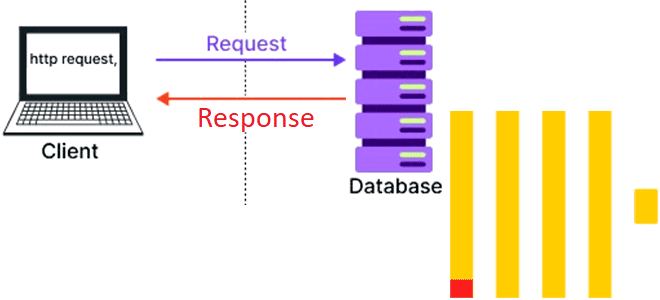
Как реализовать систему с двухзвенной архитектурой на ClickHouse и браузере. Возможности колоночной СУБД для создания одностраничных веб-приложений. Возможности ClickHouse для одностраничных веб-приложений Хотя трехзвенная архитектура (клиент -> бэк-> база данных) уже давно стала стандартом де-факто в разработке веб-приложений, двухзвенная архитектура, когда бизнес-логика переносится в базу данных, до сих пор встречается....
Что такое Chdb, зачем нужна эта библиотека и как ее использовать в коде Python-приложения для анализа больших данных в ClickHouse без разворачивания полноценного сервера этой колоночной СУБД. Как и зачем работать с ClickHouse без сервера СУБД ClickHouse является мощным инструментом аналитики больших данных, который требует соответствующей инфраструктуры. Однако, иногда нужно...

Зачем включать ротацию лог-файлов потоковых приложений Apache Spark, какие конфигурации помогут ее настроить и для чего сжимать файлы журналов в длительных заданиях. Чем полезна ротация лог-файлов Spark-приложений и как ее настроить Об общих принципах логирования системных событий в приложениях Apache Spark мы уже рассказывали здесь. В этой статье подробнее разберем...

Чем объектное хранилище данных отличается от классической файловой системы POSIX, как это влияет на разработку Spark-приложений, почему операция переименования снижает производительность облачных вычислений и что поможет ее избежать. Еще раз об отличиях объектных и файловых хранилищ и как это влияет на приложения Spark Будучи компонентом экосистемы Apache Hadoop, фреймворк Spark...
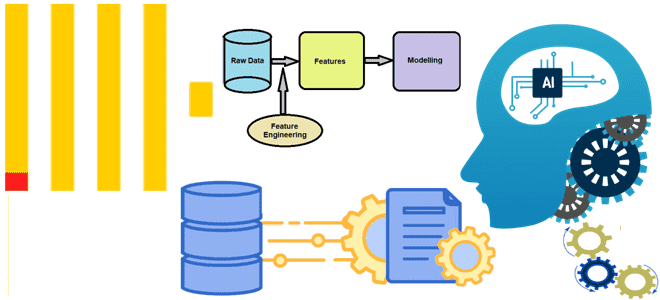
Что такое хранилище признаков, зачем это нужно в машинном обучении, каковы его главные компоненты и как использовать ClickHouse в качестве Feature Store для ML-задач. Хранилище признаков для машинного обучения: архитектура и принципы работы Feature Store Будучи колоночной базой данных, ClickHouse отлично подходит на роль хранилища фичей (Feature Store) для задач...

24 сентября вышел очередной релиз Apache Spark. Он не содержит новых фичей, но зато в нем есть несколько полезных оптимизаций и исправлений безопасности. Читайте далее о самом главном из них, связанном с утечкой токена делегирования Hadoop. Зачем нужны токены делегирования Hadoop в Spark и как они работают В выпуске Apache...
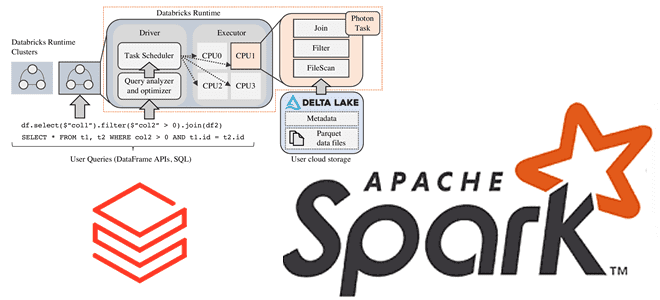
Зачем Databricks выпустила новый движок выполнения запросов Spark SQL для ML-приложений, как он работает и где его настроить: возможности и ограничения Photon Engine. Преимущества Photon Engine для ML-нагрузок Spark-приложений Чтобы сделать Apache Apark еще быстрее, разработчики Databricks выпустили новый движок выполнения запросов - Photon Engine. Это высокопроизводительный механизм запросов, который...

Зачем хранить данные в Apache Kafka постоянно и как это сделать: варианты использования и пример архитектурного решения Infinite Storage от Confluent Cloud, который лег в основу Tiered Storage. Infinite Storage от Confluent Cloud для бесконечного хранения данных в Apache Kafka Изначально Apache Kafka, как и любой другой брокер сообщений, не...

Разработчики ClickHouse с завидной регулярностью радуют новыми релизами. Не прошло и месяца, как опубликован очередной выпуск этой колоночной СУБД, версия 24.8 LTS от 20 августа 2024. О ее главных новинках читайте далее. Несовместимые изменения Начнем с самых важных и несовместимых изменений. В релизе ClickHouse 24.8 LTS для clickhouse-client и clickhouse-local...
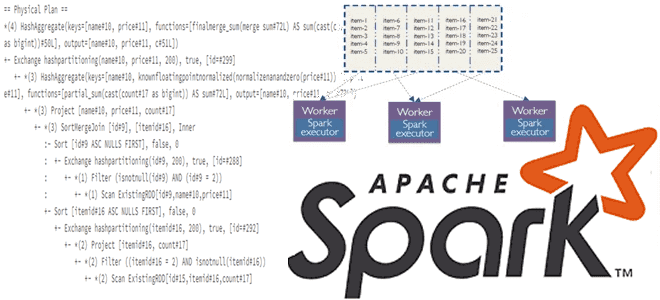
Что такое Dynamic Partition Pruning в Spark SQL, как работает этот метод оптимизации пакетных запросов, зачем его использовать в задачах аналитики больших данных, и каким образом повысить эффективность его практического применения. Что такое Dynamic Partition Pruning и зачем это нужно в Spark SQL Параллельная обработка данных в Apache Spark обеспечивается...
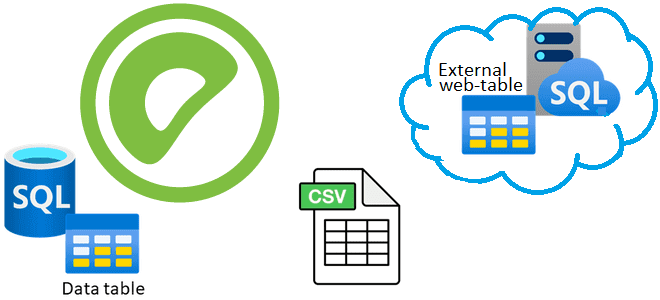
Что такое внешние веб-таблицы, зачем они нужны, чем отличаются от обычных external tables и как создать такую таблицу в Greenplum на основе команд и на основе URL. Зачем нужны внешние веб-таблицы в Greenplum О том, что в Greenplum есть внешние (external) и сторонние (foreign) таблицы, которые обеспечивают доступ к данным,...

2 августа 2024 года вышел свежий релиз Apache Flink. Знакомимся с главными новинками выпуска 1.20 для упрощения потоковой обработки данных в мощных управляемых конвейерах: новые материализованные таблицы, единый механизм слияния файлов для контрольных точек, улучшения DataStream API и пакетных операций. Улучшения Flink SQL Начнем с новинок Flink SQL, одной из...

Новая логика дедупликации данных, ограничения работы с матпредставлениями, дополнительные SQL-функции и улучшения производительности ClickHouse 24.7: краткий обзор ключевых особенностей июльского выпуска. Несовместимые изменения и новые фичи 30 июля 2024 года вышел очередной релиз ClickHouse, в котором довольно много изменений, несовместимых с прошлыми версиями. В частности, в реплицированных базах данных теперь...
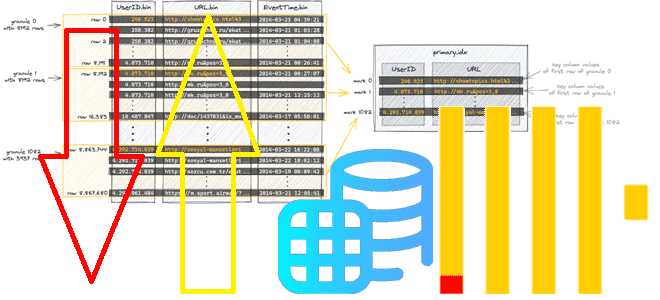
Зачем в ClickHouse 24.6 добавлена настройка optimize_row_order для оптимизации порядка строк MergeTree-таблиц, как она работает и где ее применять. Как связаны индексация и сортировка таблиц в ClickHouse Даже не будучи классической реляционной СУБД, ClickHouse поддерживает индексацию, насколько это возможно в его колоночной природе, индексируя первичным ключом целую группу строк (гранулу)...
Что такое rich-функции в Apache Flink, зачем они нужны, чем отличаются от обыкновенных UDF и как с ними работать: простой пример на PyFlink с запуском в Google Colab. Rich-функции в Apache Flink Будучи очень мощным фреймворком для разработки распределенных потоковых приложений, Apache Flink не только предоставляет широкий набор stateful-функций, но...

20 июня 2024 года вышел очередной релиз Greenplum. Разбираемся с ключевыми новинками выпуска 7.2: сканирование индекса в AO-таблицах, изменения в оптимизаторе GPORCA, улучшенная обработка геопространственных данных и новая служба централизованного управления сегментами Postmaster. Новинки Greenplum 7.2 для дата-инженера Начнем с изменений, повышающих производительность Greenplum. Одним из них стало сканирование индекса...
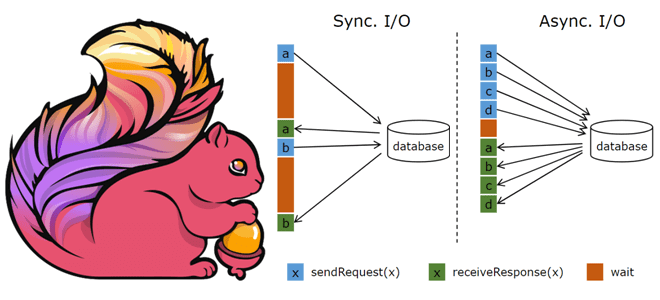
API асинхронного ввода-вывода в Apache Flink и как его использовать для асинхронной интеграции данных из внешней системы с потоком событий. Основы асинхронной обработки в Apache Flink Обогащение потоков данных информацией из внешних систем является довольно сложным кейсом из-за необходимости синхронизировать скорость поступления событий с задержкой доступа к внешнему источнику. При...

Как устроен потоковый запрос Spark Structured Streaming на уровне кода: интерфейсы, их методы и как их настроить, создание и запуск StreamingQuery. Создание потокового запроса в Spark Structured Streaming Хотя структурированная потоковая передача Spark основана на SQL-движке этого фреймворка, в ней гораздо больше сложных абстракций. Например, с точки зрения программирования потоковый...