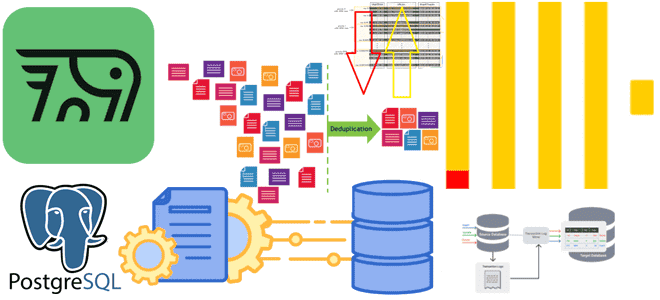
Почему ключи сортировки в ClickHouse могут стать причиной появления дублей или пропусков при CDC-передаче изменений из PostgreSQL и как этого избежать: особенности логической репликации из транзакционной базы данных в аналитическую. Влияние ключей сортировки на CDC-передачу изменений из PostgreSQL в ClickHouse Продолжая разбираться с дублированием данных при передачи изменений из PostgreSQL...
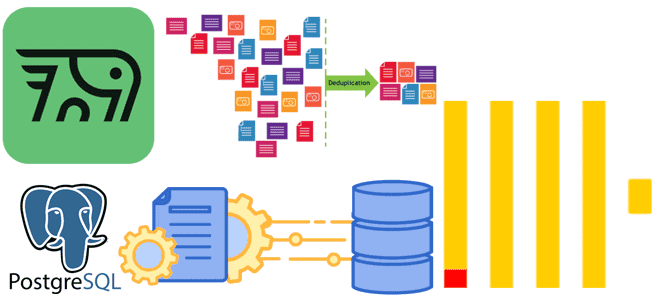
Почему табличный движок ReplacingMergeTree в PeerDB и ClickPipes не избавит от дублей при передаче измененных данных из PostgreSQL в ClickHouse и можно ли полностью выполнить дедупликацию с помощью модификатора FINAL, политики строк, обновляемых представлений или агрегатных и оконных функций. Как движок ReplacingMergeTree допускает дубли при импорте изменений из PostgreSQL в...
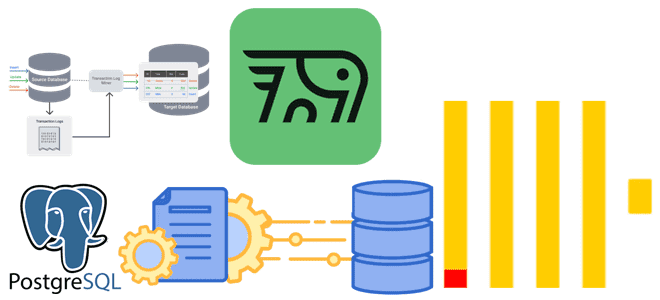
Как передать изменения данных из транзакционной базы в аналитическую без дублей и задержек: CDC-ETL из PostgreSQL в ClickHouse с PeerDB. CDC для ClickHouse с PeerDB и ClickPipes Возможности Clickhouse позволяют построить на нем корпоративное хранилище данных целиком или реализовать отдельный слой, например, для денормализованных витрин. Также совместное использование транзакционных и...
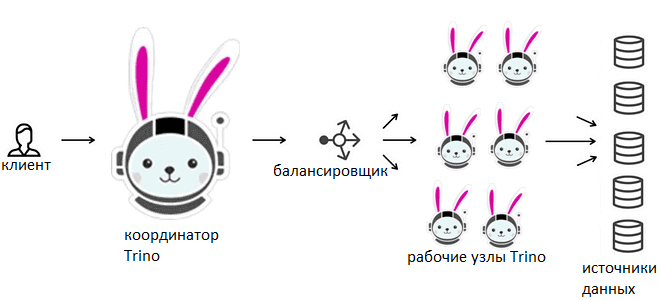
Как ускорить работу Trino при росте нагрузки и сэкономить на кластере при ее сокращении: автомасштабирование рабочих узлов и операций записи, а также настройка групп ресурсов. Масштабирование кластера Классическим способом справиться с растущими вычислительными нагрузками в гомогенной распределенной системе является горизонтальное масштабирование кластера. Это сводится к добавлению новых узлов, которые отвечают...
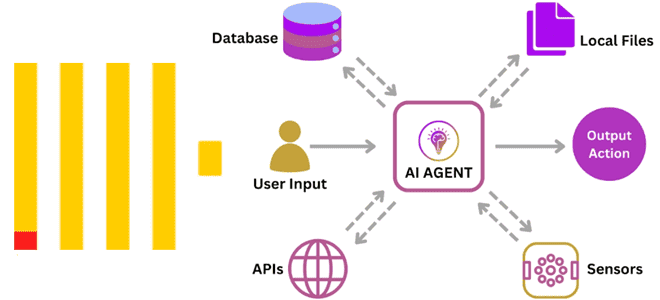
Зачем использовать ClickHouse для аналитики в реальном времени с агентами ИИ и как это сделать: современные вызовы внедрения LLM. Как реализовать ML-систему агентского ИИ с ClickHouse Продолжим разговор про агентский ИИ на основе LLM, когда ML-система не просто реагирует на запросы пользователя, а работает автономно, интеллектуально решая задачи без прямого...

7 февраля 2025 года вышел очередной релиз ClickHouse. Знакомимся с его главными новинками: ускорение параллельного хэш-соединения, индексы MinMax на уровне таблицы, автоинкременты полей и улучшенное объединение таблиц с табличной функцией merge. Улучшение параллельного хэш-соединения в ClickHouse 25.1 В ClickHouse 25.1 добавлено 15 новых функций, 36 улучшений и 77 исправлений ошибок....

Особенности хранения и аналитической обработки JSON-документов в ClickHouse, MongoDB, Elasticsearch, DuckDB и PostgreSQL: объяснение бенчмаркингового теста. JSON в ClickHouse Недавно мы писали про бенчмаркинговое сравнение хранения и обработки JSON-данных в ClickHouse, MongoDB, Elasticsearch, DuckDB и PostgreSQL. В этом тесте, проведенном самими разработчиками ClickHouse, эта СУБД показала максимальную эффективность, которая обоснована...

Почему ClickHouse требует меньше места для хранения JSON-документов и быстрее выполняет аналитические запросы к ним по сравнению с MongoDB, Elasticsearch, DuckDB и PostgreSQL: бенчмаркинговый тест от разработчиков колоночной СУБД. Как Clickhouse делает быстрее агрегации в JSON-данных Хотя бенчмаркинговые тесты от вендоров редко бывают объективными, просматривать их довольно интересно. Недавно мне...
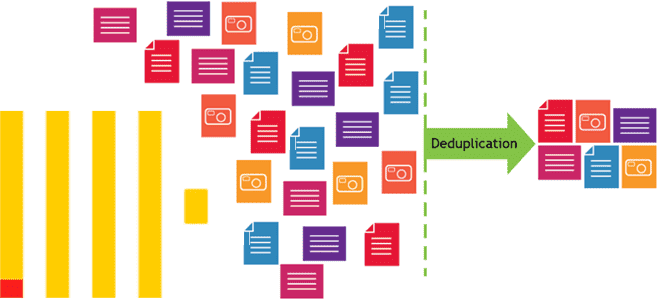
Почему в хранилище и витрину данных могут попасть дубли, чем это чревато и какие встроенные механизмы дедупликации есть в ClickHouse. Примеры OPTIMIZE-запросов и работы с движком ReplacingMergeTree. Причины дублирования данных и их последствия Дублирование данных в хранилищах и в витринах – довольно частая проблема в дата-инженерии. Это приводит к росту...
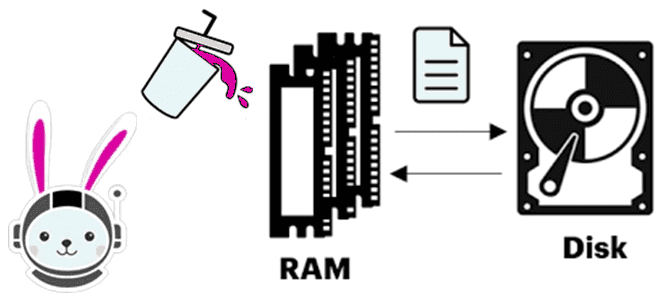
Что происходит, когда Trino не хватает памяти для выполнения SQL-запроса, как выполняется сброс промежуточных результатов на диск и почему механизм spill-to-disk не избавляет от OOM-ошибок. Spill-to-disk: сброс промежуточных результатов на диск в Trino Продолжая вчерашний разговор про нехватку памяти (OOM, Out Of Memory) в Trino, сегодня рассмотрим, как работает spill-механизм...
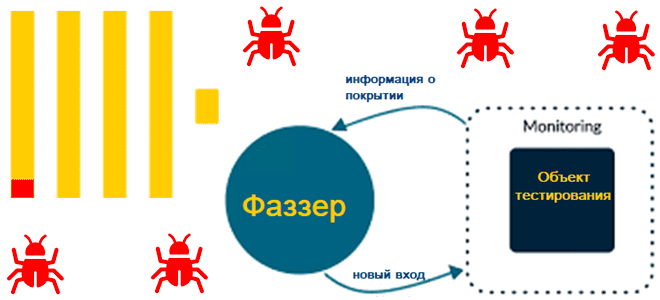
Что такое фаззинг-тестирование, зачем нужен новый фаззер для ClickHouse, и как BuzzHouse выявляет сложные проблемы и потенциальные уязвимости самой популярной колоночной СУБД, Что такое фаззинг-тестирование баз данных Поскольку база данных тоже программный продукт, перед выпуском в релиз она тестируется. Используемых при этом методов тестирования довольно много, и одним из них...

Что такое Apache Doris, как его использовать для построения хранилища данных и чем это отличается от ClickHouse. Сценарии применения и критерии выбора основы DWH. Что такое Apache Doris Недавно мы рассматривали, почему ClickHouse подходит для реализации хранилища данных на основе эталонной архитектуры Medallion благодаря поддержке более 70 форматов файлов, материализованным...
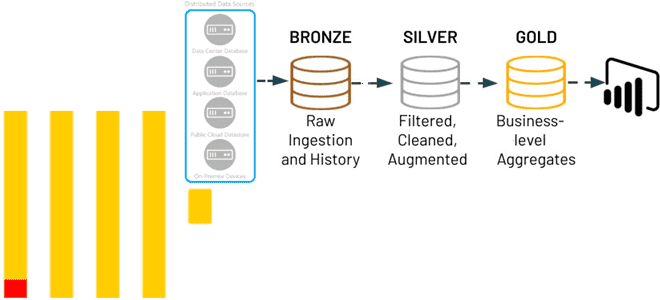
Почему ClickHouse подходит для архитектуры данных Medallion и как реализовать это слоистое хранилище средствами колоночной СУБД без сторонних инструментов: лучшие практики и примеры использования. 3 слоя архитектуры данных Medallion Слоистая архитектура, предложенная компанией Databricks, сегодня считается классикой для построения озер и хранилищ данных. Она предполагает реализацию 3-х уровней (слоев): Бронза,...
Зачем создавать разные проекции таблиц в базе данных и как это работает в Clickhouse: практический пример с агрегатным запросом. Возможности и ограничения механизма проекций в колоночной аналитической СУБД. Что такое проекции и как они реализованы в ClickHouse Поскольку основное назначение ClickHouse – аналитика больших объемов данных в реальном времени, это...
Чем полезна поддержка gRPC в Clickhouse и как ее реализовать: разбираем интерфейс удаленного вызова процедур на примере потоковой вставки событий пользовательского поведения из Kafka в таблицу колоночной базы данных со стриминговым выводом. Поддержка gRPC в ClickHouse ClickHouse поддерживает gRPC – фреймворк от Google и система удаленного вызова процедур с открытым...
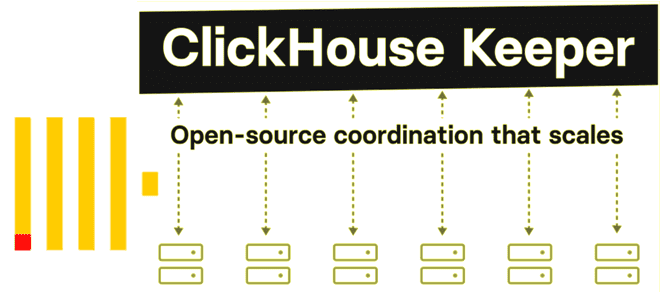
Что не так с Apache Zookeeper и почему разработчики ClickHouse решили заменить его на встроенный сервис синхронизации метаданных на базе RAFT-протокола с линеаризацией записи и чтения. Как работает ClickHouse Keeper и где его настроить. Что не так с Apache Zookeeper Многие распределенные системы, которые состоят из нескольких узлов, для обеспечения...
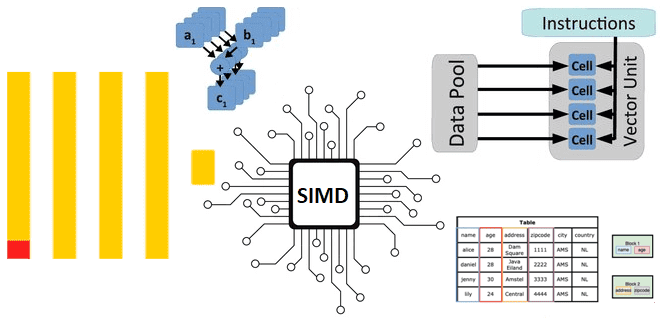
Как ClickHouse реализует параллельные векторные вычисления над большим объемом данных на любых аппаратных платформах: диспетчеризация ЦП для выполнения SIMD-инструкций в сложных функциях. Реализация векторных вычислений в ЦП Как мы уже отмечали здесь, ClickHouse имеет встроенную поддержку векторных вычислений, когда при выполнении одной инструкции процессора производится не одна операция, а одновременно...

Что такое Observability и чем ClickHouse хорош для обеспечения наблюдаемости, как хранить журналы и трассировки в этой колоночной базе данных и для чего реализована интеграция с OpenTelemetry. Что такое Observability и чем ClickHouse хорош для обеспечения наблюдаемости Будучи колоночной базой данных, ClickHouse отлично подходит для мониторинга и анализа системных метрик,...
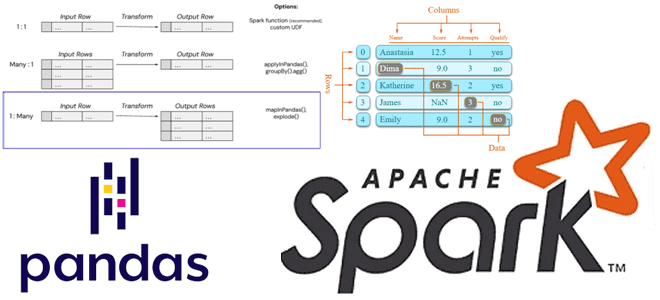
Как применить пользовательскую функцию Python к объектам pandas в распределенной среде Apache Spark. Варианты использования Pandas UDF, applyInPandas() и mapInPandas() на практических примерах. Разница между Pandas UDF, applyInPandas и mapInPandas в Apache Spark Недавно я показывала пример сравнения быстродействия метода applyInPandas() с функцией apply() библиотеки pandas. Однако, помимо applyInPandas() в...
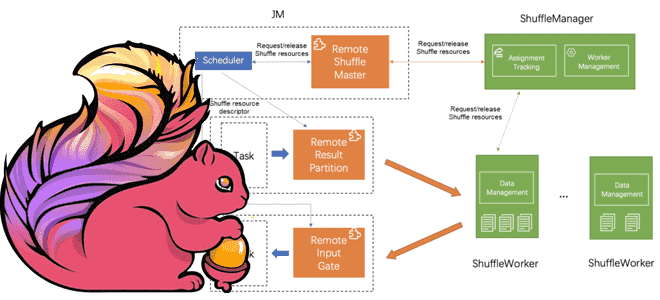
Что такое Remote Shuffle Service в Apache Flink, зачем это нужно и как служба удаленного перемешивания позволяет создавать масштабируемые и надежные приложения для унифицированной потоковой и пакетной обработки больших объемов данных. Что такое Remote Shuffle Service в Apache Flink Apache Flink рассматривает пакетную обработку как частный случай потоковых вычислений. Однако,...