
Чтобы сделать наши курсы по Apache Spark для дата-инженеров еще более полезными, сегодня рассмотрим, как PySpark-задания могут считывать данные из корзин объектного хранилища AWS S3, используя Python-пакет boto3. Читайте далее, что представляет собой этот SDK, как использовать его вместе с IAM-ролями, а также как обеспечить безопасность конфиденциальных данных с помощью...
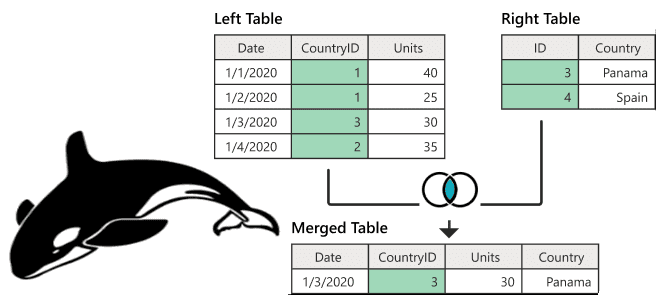
Поиск данных по нескольким таблицам в реляционных базах данных реализуется через SQL-запрос с оператором JOIN. В NoSQL-хранилищах такая возможность может отсутствовать. Разбираем, как соединить таблицы в Apache HBase и причем здесь MapReduce. Варианты реализации JOIN в Apache HBase Будучи популярной NoSQL-базой, которая реализует возможности Google BigTable для Apache Hadoop, HBase...

Поскольку Apache NiFi является распределенной системой стека Big Data, для него очень значимы вопросы балансировки нагрузки. Поэтому сегодня разберем важную для обучения дата-инженеров и администраторов кластера NiFi тему по балансировке нагрузки и распространению данных в этом потоковом ETL-фреймворке. Как происходит балансировка нагрузки в кластере Apache NiFi До версии 1.8 в...
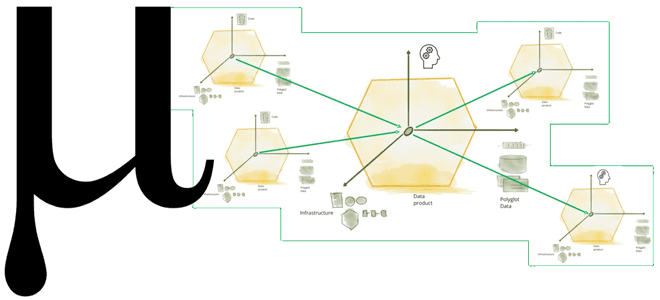
Что не так с конвейерной моделью обработки данных и почему архитектура Data Mesh с потоковой передачей событий не решают всех проблем пакетной парадигмы. Зачем нужна новая архитектура данных под названием Мю, какие инструменты и принципы она использует для устранения технологической неоднородности отдельных технологий Big Data, а также при чем здесь...

В этой статье для обучения дата-инженеров и администраторов кластера Apache Kafka разберем, какие ошибки создают медленные потребители и как решить их, просто изменив значений конфигураций по умолчанию. А также познакомимся с Lighthouse - еще одним полезным инструментом мониторинга системных метрик, который позволит обнаружить эти и другие проблемы. Проблема медленных потребителей...

Сегодня рассмотрим, зачем нужно внешнее хранилище метаданных для Apache Hive, и как запустить его высокодоступный и масштабируемый сервис в Amazon EKS путем контейнеризации приложения. Зачем нужно внешнее хранилище метаданных Apache Hive? Apache Hive используется для доступа к данным, хранящимся в распределенной файловой системе Hadoop (HDFS) через стандартные SQL-запросы. Это NoSQL-хранилище...

Можно ли применять Apache Spark Structured Streaming для пакетных заданий и в каких случаях это целесообразно. Разбираемся, как устроена потоковая передача событий в Spark Structured Streaming, с какой частотой разные режимы триггеров микропакетной обработки данных запускают потоковые вычисления и что выбрать дата-инженеру. Потоковая передача событий и пакетные задания: versus или...

Чтобы сделать наши курсы по Apache Flink еще более полезными для дата-инженеров и разработчиков распределенных приложений потоковой аналитики больших данных, сегодня разберем, как работают источники данных потоковой обработки на примере топиков Kafka. Источники данных в Apache Flink Наряду с Apache Spark, Flink также является популярным фреймворком пакетной и потоковой обработки...
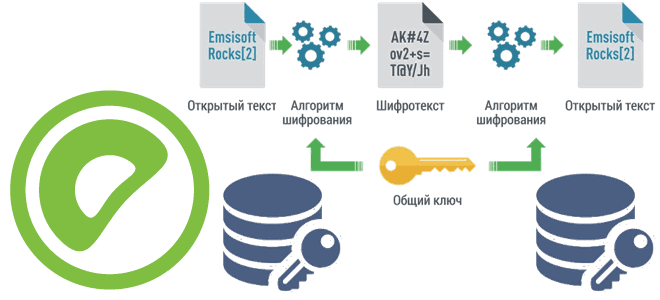
Чтобы сделать наши курсы по Greenplum еще более полезными для дата-инженеров и администраторов, сегодня познакомимся с pgcrypto – важным расширением этой MPP-СУБД, которое предоставляет криптографические функции, чтобы хранить некоторые столбцы данных в зашифрованном виде. Как установить расширение pgcrypto и использовать его для улучшения безопасности Greenplum. Шифрование данных в Greenplum База...

Сегодня разберем распространенные трудности корпоративных платформ обработки и хранения Big Data, а также как избежать этих проблем, используя современные методы и средства проектирования дата-архитектур и инструменты инженерии данных. 7 главных проблем с платформами данных Обычно каждая data-driven компания органично развивает свои платформы данных, усложняя их архитектуры. Но этот процесс эволюционного...
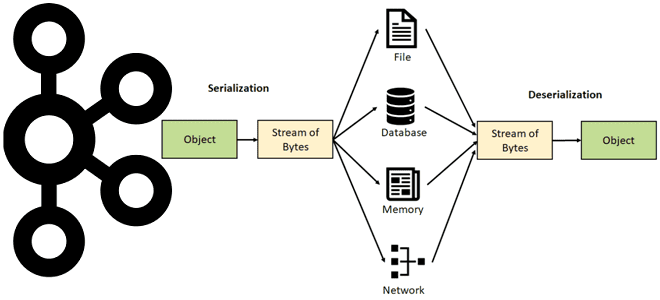
Недавно мы писали про сериализацию и десериализацию данных в Apache Kafka. Продолжая эту важную для обучения дата-инженеров и разработчиков распределенных приложений тему, рассмотрим особенности преобразования и валидации сообщений в JSON-формате, а также поговорим про автоматическую идентификацию формата сообщения. Сериализация и десериализация данных в Apache Kafka Выполняя роль интеграционной платформы, Apache...
В июле 2022 года на конференции Data and AI Summit компания Databricks представила новый проект для экосистемы Apache Spark под названием Spark Connect. Что это такое и как оно пригодится разработчикам распределенных приложений и дата-инженерам, читайте далее. Что не так с Apache Spark и зачем нужен новый проект Databricks Появившись...
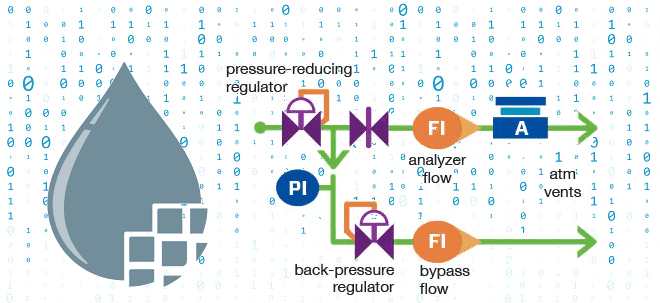
Чтобы сделать наши курсы для дата-инженеров по Apache NiFi еще более полезными, сегодня мы рассмотрим, что такое обратное давление и как этот механизм используется при потоковой обработке данных. Также поговорим про визуализацию back pressure в GUI, математические модели прогнозирования пороговых значения и настройку конфигураций. Что такое обратное давление в потоковой...

9 сентября 2022 года VMware Tanzu выпустили Greenplum 6.22. А спустя месяц, 7 октября вышел апгрейд этого релиза с исправлением ошибок. Разбираем, что нового в этих выпусках: полезные функции, улучшения и исправления ошибок, особенно важные для администратора кластера и дата-инженера. Greenplum 6.22.0 Сентябрьское обновление Greenplum 6.22.0 включает следующие функциональные возможности...

Недавно мы рассматривали, как дата-инженеры Airbnb перевели аналитические нагрузки корпоративного озера данных с Apache Hive на Iceberg и Spark. Продолжая разговор про эти фреймворки реализации Data Lake, сегодня разберем стратегии миграции озера данных с Apache Hive на Iceberg. Зачем уходить с Apache Hive на Iceberg и как это сделать Напомним,...

В этой статье для обучения дата-инженеров и разработчиков приложений потоковой аналитики больших данных рассмотрим, на что следует обратить внимание при развертывании Apache Flink в реальных проектах. Обработка опоздавших данных, тонкости сериализации, проблемы неравномерного распределения и большие состояния заданий. Обработка опоздавших данных в Apache Flink В потоковой обработке данных, которую поддерживает...
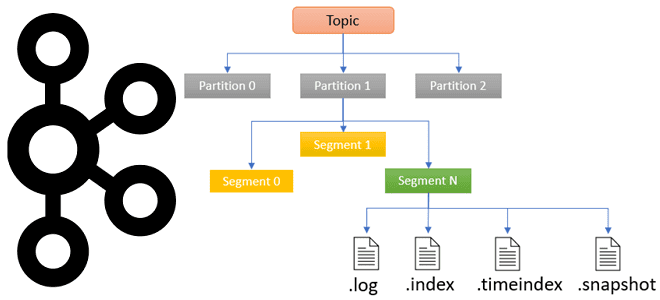
Чтобы сделать наши практические курсы по Apache Kafka еще более полезными, сегодня рассмотрим, в каких файлах хранятся сообщения, смещения и состояния продюсера, а также функции работы с ними для потоковой передачи событий. Средства обработки и хранения данных в Apache Kafka Прежде, чем погружаться в тонкости хранения данных в Apache Kafka,...

Сегодня мы продолжим говорить про Apache Spark Structured Streaming и его применение для обновления данных в таблицах Delta Lake. А также на практических примерах разберем, как выполняются основные операции работы с данными средствами Spark Structured Streaming API. Таблицы в Delta Lake Delta Lake – это уровня хранилища данных с открытым...
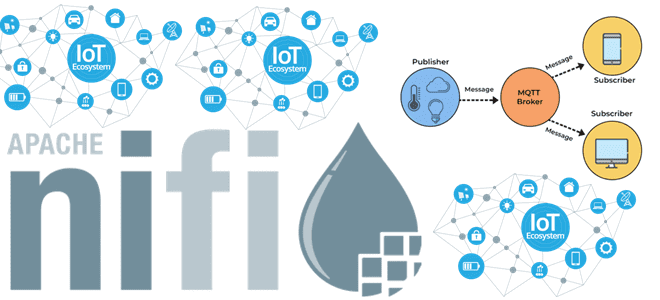
В прошлой статье про обновление Apache NiFi мы писали, что в новой версии 1.18.0 улучшено взаимодействие с протоколом MQTT, который активно используется в системах интернета вещей. Сегодня разберем более подробно, как наладить сбор и публикацию данных в MQTT-топики с помощью процессоров Apache NiFi, а также разберем, что такое брокер HiveMQ....

Продолжая недавний разговор про Apache Spark Structured Streaming, сегодня рассмотрим, как этот движок потоковой обработки данных помогает дата-инженеру реализовать идемпотентную запись в таблицы Delta Lake, а также выполнить операции слияния и обновления/вставки в помощью метода foreachBatch(). Идемпотентность потоковых приложений Apache Spark Идемпотентность – важное свойство распределенных систем, которое гарантирует, что...