
Зачем хранить данные в Apache Kafka постоянно и как это сделать: варианты использования и пример архитектурного решения Infinite Storage от Confluent Cloud, который лег в основу Tiered Storage. Infinite Storage от Confluent Cloud для бесконечного хранения данных в Apache Kafka Изначально Apache Kafka, как и любой другой брокер сообщений, не...
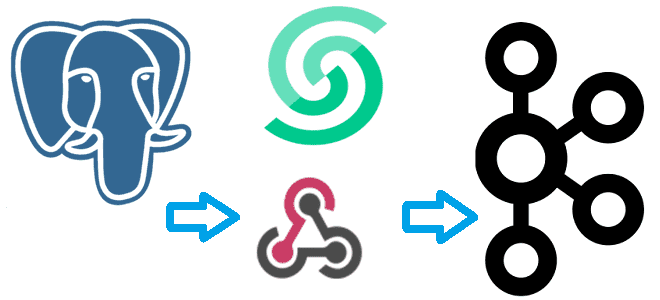
Что такое вебхук и как отправить событие из PostgreSQL в Apache Kafka, используя API Webhook на платформе Upstash. NoCode-интеграция БД и брокера сообщений: практический пример. Практический пример: CDC из PostgreSQL в Kafka через веб-хуки Веб-хук или перехватчик – это настраиваемый обратный HTTP-вызов из одной системы к другой. Он используется для...
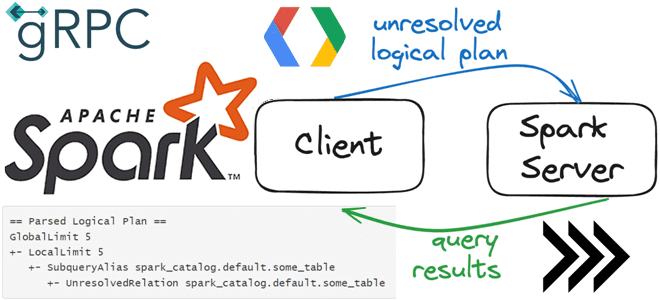
Что общего у клиент-серверной архитектуры Spark Connect с JDBC-драйвером подключения к БД, как взаимодействуют клиент и сервер по gRPC, как подключиться к серверу и указать обязательность поля в схеме proto-сообщения. Как работает Spark Connect О том, что представляет собой Spark Connect и зачем нужен этот клиентский API, позволяющий удаленно подключаться...
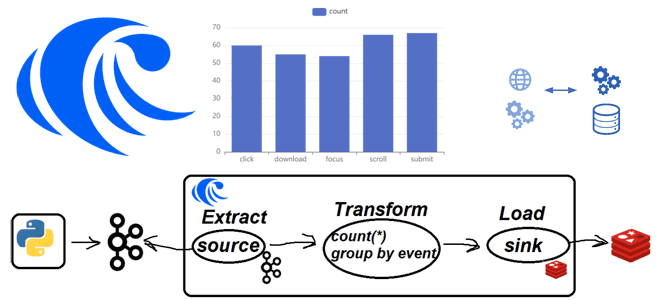
Практическая демонстрация потоковой агрегации событий пользовательского поведений из Apache Kafka с записью результатов в Redis на платформе RisingWave: примеры Python-кода и конвейера из SQL-инструкций. Постановка задачи Одной из ярких тенденций в современном стеке Big Data сегодня стали платформы данных, которые позволяют интегрировать разные системы между собой, поддерживая как пакетную, так...
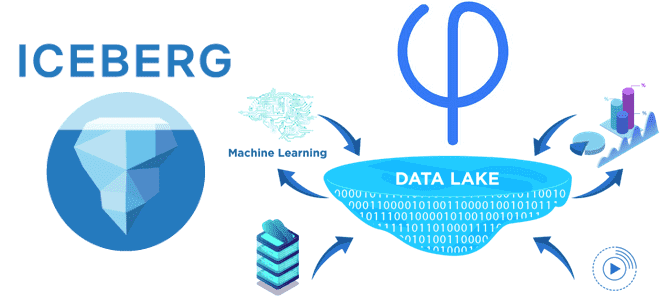
Архитектура Data Lake: что не так с потоковыми обновлениями данных в Data Lake, как Apache Iceberg реализует эти операции и почему Upsolver решили улучшить этот формат Проблема потоковых обновлений в Data Lake и 2 подхода к ее решению Считается, что озеро данных (Data Lake) предлагают доступное и гибкое хранилище, позволяющее...
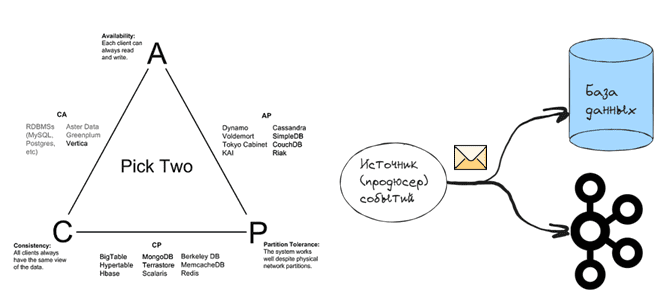
Проклятье CAP-теоремы: проблема целостности данных в распределенной системе и варианты ее решения. 3 шаблона проектирования микросервисной EDA-архитектуры на Apache Kafka: transactional outbox, Event Sourcing и listen to yourself. Что такое проблема двойной записи в распределенных гетерогенных системах Согласно CAP-теореме, распределенная система в любой момент времени обеспечивает выполнение только 2-х требований...
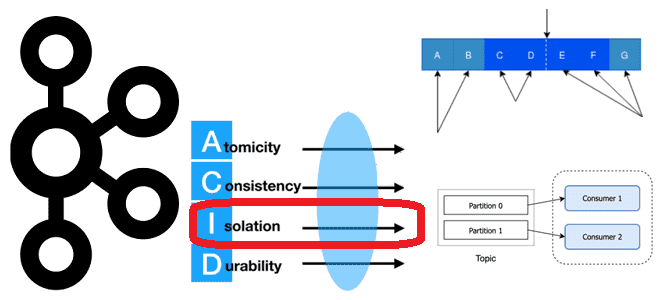
Как Apache Kafka реализует требование к изоляции потребления сообщений, опубликованных транзакционно, и где это настроить в клиентских API, зачем отслеживать LSO, для чего прерывать транзакцию, и какими методами это обеспечивается в библиотеке confluent_kafka. Транзакционое потребление: изоляция чтения сообщений в Apache Kafka При том, что Apache Kafka не является базой данных,...
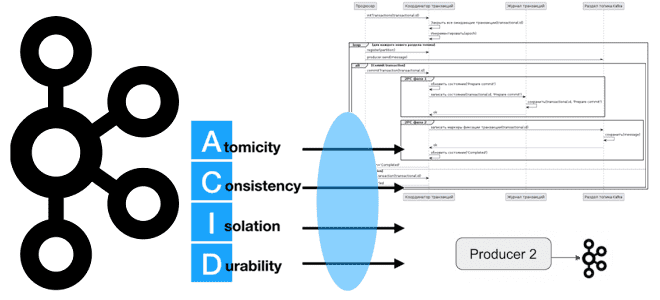
Как Apache Kafka реализует требование к атомарности транзакций с помощью координатора и журнала транзакций: принцип Atomic в ACID и его иллюстрация на UML-диаграмме последовательности публикации сообщений в раздел топика. Транзакционная публикация сообщений в Apache Kafka Хотя Apache Kafka не является базой данных, эта платформа потоковой передачи событий все же хранит...
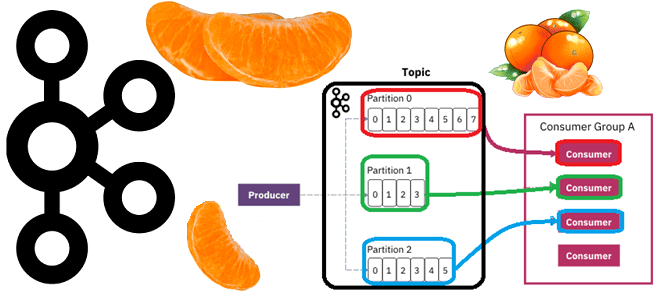
Почему раздел называется единицей параллелизма и как определить оптимальное число разделов в топике Apache Kafka в зависимости от количества потребителей и вариативности их поведения, разницы пропускной способности публикации и потребления сообщений, семантики партиционирования, толерантности к упорядоченности событий и ресурсных возможностей узла кластера. Что учитывать при разделении топика Apache Kafka Хотя...
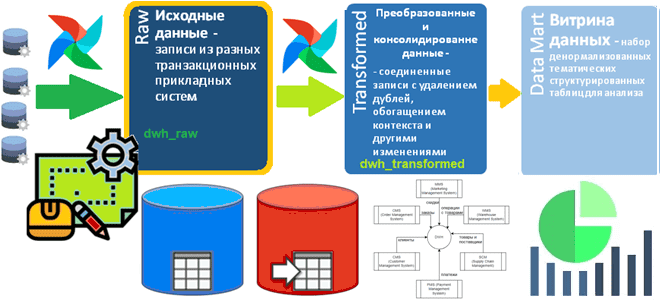
Как определить структуру Raw-слоя корпоративного хранилища данных: пример проектирования и DDL-скрипт для кейса электронной коммерции, выбор компонентов решения для архитектуры данных. Постановка задачи: анализ систем-источников Сегодня корпоративные хранилища данных (DWH, Data Warehouse) обычно реализуются в виде нескольких баз данных, связанных ETL-процессами. Причем каждая из этих гомогенных или гетерогенных, т.е. на...

От оркестрации и синхронизации конвейеров обработки данных до управления хранилищами, включая хранение состояний для stateful-приложений: сложности проектирования архитектуры потоковой обработки событий и способы их решения. Основные сложности проектирования современной архитектуры данных Из-за принципиальных отличий потоковой парадигмы обработки данных от пакетной, что разбиралось здесь, задача проектирования дата-конвейеров сильно усложняется, т.к. редко...
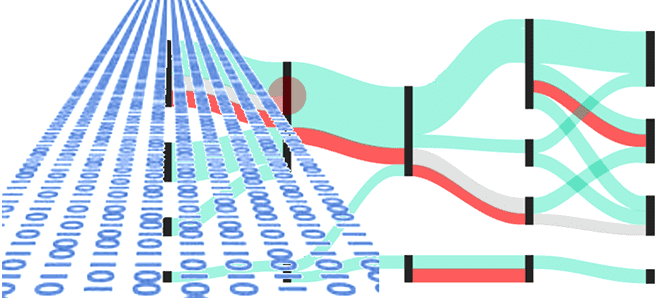
Чем пакетная парадигма обработки данных отличается от пакетной и как она реализуется на практике: принципы работы и воплощение в Big Data на примере Apache Spark, Kafka и Flink. Еще раз о разнице потоковой и пакетной парадигмы обработки данных Пакетная обработка и потоковая обработка — это две разные парадигмы обработки данных....
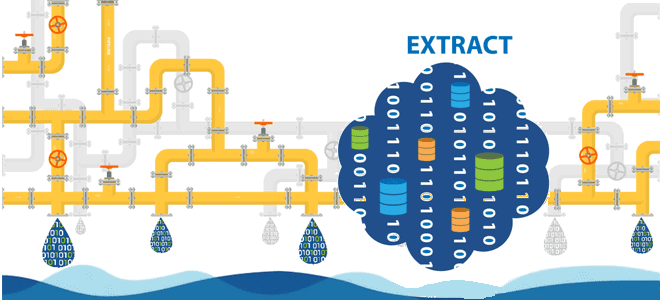
Большинство ETL-конвейеров извлекают данные из реляционных баз в пакетном или микропакетном режиме. Читайте далее, по каким шаблонам реализовать операции извлечения. Моментальные снимки: периодическая выгрузка данных из исходных таблиц Полная периодическая выгрузка данных из одной или нескольких таблиц – это, пожалуй, самый простой метод извлечения изменяемых данных. По своей сути результат полной...
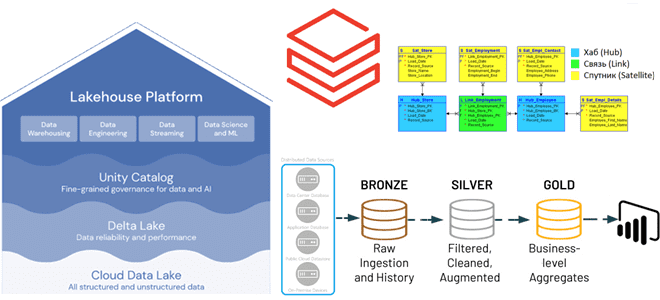
Преимущества методологии Data Vault для проектирования архитектуры данных Lakehouse, а также лучшие практики ее использования с максимальной эффективностью для корпоративного хранилища. Принципы методологии Data Vault и их применение к проектированию DWH Существует множество различных методологий проектирования данных, которые можно использовать при разработке аналитической системы, например, модели звезды и снежинки, подходы...
Как отметки времени о событиях в архитектуре данных Lakehouse позволяют обеспечить безопасность Delta Lake: примеры извлечения и преобразования, а также лучшие практики. Почему отметки времени в логах системных событий так важны для архитектуры больших данных Архитектура Lakehouse построена на открытых стандартах и API, которые позволяют сочетать ACID-транзакции и управление данными...
Что такое Databricks SQL и как его ускорить, используя кэширование данных: типы хранилищ данных в платформе Lakehouse и виды кэшей. Что такое Databricks SQL Платформа Databricks Lakehouse предоставляет комплексное решение для хранения данных. Она построена на открытых стандартах и API. Эта архитектура данных сочетает ACID-транзакции и управление данными корпоративных хранилищ...
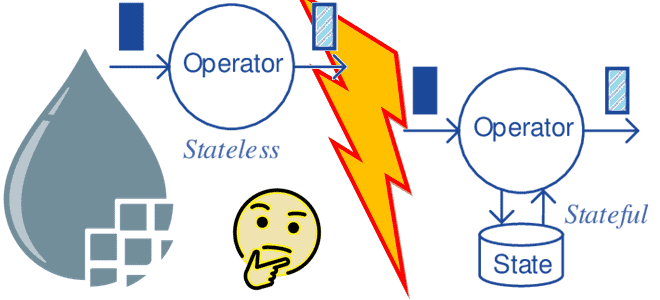
Недавно мы писали, что такое Apache NiFi без сохранения состояния и чем он отличается от классического приложения потокового конвейера обработки данных. Сегодня рассмотрим особенности и ограничения Stateless-механизма и наилучшие сценарии использования в сравнении с классическим движком. Особенности и ограничения Stateless-движка Напомним, классический NiFi предназначен для запуска большого многопользовательского приложения, в...

Зачем разделять таблицы в озере данных, что не так с Hive-разделением и Z-упорядочение в Delta Lake и как работает жидкая кластеризация (Liquid Clustering) – новая стратегия оптимизации размещения данных от Databricks. Что не так с Hive-разделением и Z-упорядочение таблиц в Delta Lake В озере данных физическое расположение данных может оказать...
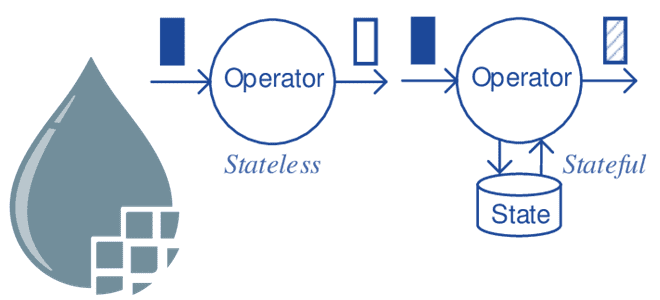
Чем Stateless-движок отличается от классического механизма потоковой обработки данных Apache NiFi, каковы его ключевые принципы работы и почему здесь особенно важна надежность источника. Классический Apache NiFi: основные понятия Приложение Apache NiFi можно рассматривать как два отдельных, но взаимосвязанных компонента: подлинности потока и его движок. Объединив их в одном приложении, NiFi...
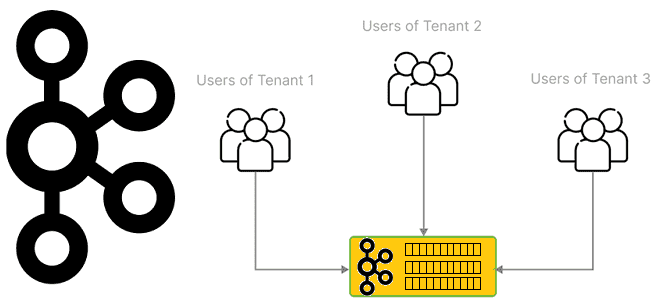
Что такое мультитенантность и как администратору Apache Kafka настроить изоляцию арендаторов в мультиарендном кластере: конфигурации, квоты и лайфхаки. Что такое мультиарендность и как реализовать эту модель для кластера Kafka Мультитенантность (мультитенантность, multitenancy) переводится с английского как множественная аренда и в контексте архитектуры ПО означает разделение одного экземпляра приложения между несколькими...