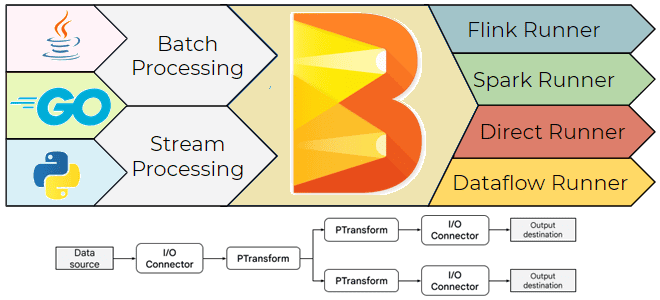
Что такое Apache Beam, зачем он нужен, чем полезен дата-инженеру и как его использовать: архитектура, принципы работы и примеры построения пакетных и потоковых конвейеров обработки данных. Что такое Apache Beam и зачем он нужен Хотя выбор технологического стека – один из важнейших вопросов архитектурного проектирования, иногда требуется универсальное решение построения...
Почему репортеры мониторинга системных метрик Flink, отправляющие данные в Prometheus, не решают проблемы предварительной обработки измерений с IoT-устройств, и как новый коннектор расширяет сферу применения фреймворка потоковой обработки. Встроенные средства мониторинга системных метрик Flink В декабре 2024 года вышел новый коннектор Apache Flink к Prometheus – популярной базе данных временных...
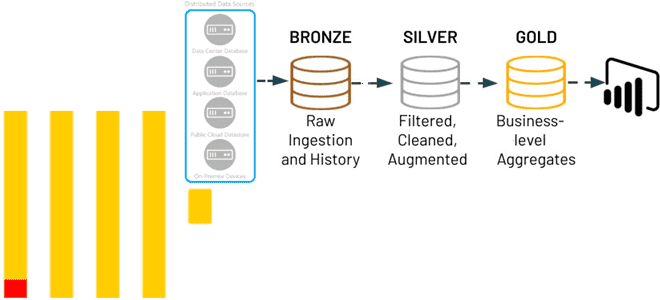
Почему ClickHouse подходит для архитектуры данных Medallion и как реализовать это слоистое хранилище средствами колоночной СУБД без сторонних инструментов: лучшие практики и примеры использования. 3 слоя архитектуры данных Medallion Слоистая архитектура, предложенная компанией Databricks, сегодня считается классикой для построения озер и хранилищ данных. Она предполагает реализацию 3-х уровней (слоев): Бронза,...

Сложности развертывания контейнерных stateful-приложений и как их решить с Argo Rollouts и Kubernetes Downward API: примеры YAML-конфигураций канареечного развертывания Spark-приложения. Расширение стратегий развертывания в Kubernetes с Argo Rollouts Мы уже писали, в чем сложности оркестрации параллельных заданий на платформе Kubernetes и как их можно решить с помощью Argo Workflows -...
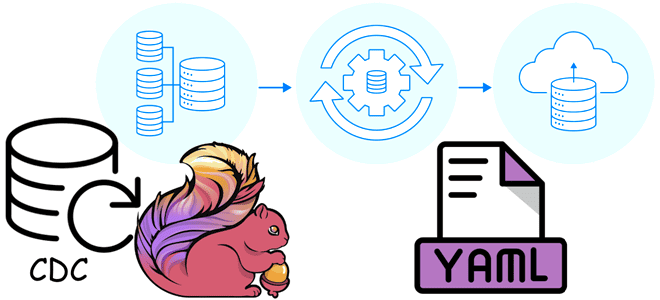
Как описать ETL-конвейер захвата, преобразования и передачи изменения данных в YAML-файле: пример конфигурации Flink CDC из PostgreSQL в Elasticsearch. ETL-конвейер Flink CDC в YAML-файле Apache Flink позволяет строить надежные конвейеры обработки данных, используя не только с внутренние API, но и с помощью дополнительных компонентов. Одним из таких компонентов является Flink...

Как расширение Citus повышает производительность PostgreSQL, организуя распределенный кластер с помощью шардирования и почему этого недостаточно для эффективных OLAP-запросов как в Greenplum. Что такое Citus для PostgreSQL Поскольку Greenplum представляет собой массив отдельных баз данных PostgreSQL 12, работающих вместе для представления единого образа базы данных, у тех, кто знакомится с...

Как работает исполнитель Celery в Apache AirFlow, зачем ему очередь сообщений и каким образом это помогает масштабировать параллельное выполнение задач. Как работает исполнитель Celery в Apache AirFlow Именно исполнитель (Executor) в Apache Airflow отвечает за выполнение задач в рабочих процессах, определяя их локацию и последовательность, а также использование ресурсов. Хотя...

Как реализовать концепцию обратного давления (backpressure) в потоковой обработке событий с Apache Kafka: настройка конфигураций на стороне приложений-продюсеров и потребителей, а также мониторинг системных метрик. Обратное давление при публикации событий в Kafka Мы уже писали о том, зачем нужна концепция обратного давления (backpressure) в потоковой передаче событий и как она...
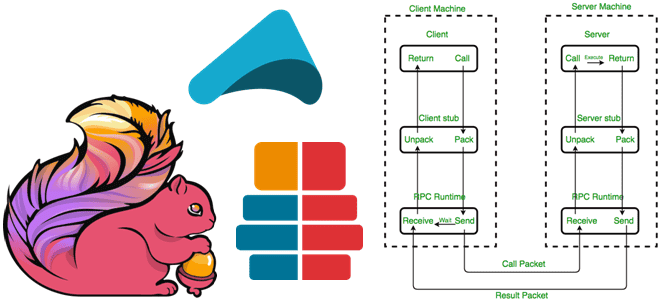
Зачем и как Apache Flink использует удаленный вызов процедур, с помощью каких технологий реализуется это RPC-взаимодействие и почему в 2023 году Akka заменен на Pekko. Удаленный вызов процедур в Apache Flink Мы уже рассказывали, как RPC-вызовы используются для коммуникации между компонентами Spark. Удаленный вызов процедур используется и в Apache Flink,...

Что общего между Trino и dbt, чем они отличаются и в каких случаях выбирать тот или иной инструмент для инженерии и анализа данных. Краткий ликбез для начинающего дата-инженера и аналитика. Сходства и отличия Trino и dbt Trino и dbt (Data Build Tool) — это два популярных инструмента с открытым исходным...
Что не так с классическими ETL/ELT-конвейерами транзакционных и аналитических систем в гибридное хранилище LakeHouse, и как дата-инженеры платформы Confluent хотят решить эти проблемы с помощью Tableflow, передавая события из Kafka в таблицы Iceberg. Очередная попытка унификации пакетной и потоковой парадигмы Чтобы обеспечивать потребности современного бизнеса в пакетной и потоковой аналитике,...
Зачем Trino статистика таблиц, как MPP-движок создает план выполнения SQL-запросов к разным источникам данных, применяя CBO-оптимизацию, а также полную или частичную передачу обработки предикатов в базовое хранилище. Внутренние оптимизации Trino В отличие от MapReduce с материализацией промежуточных результатов на диске, в массово-параллельной архитектуре Trino промежуточные результаты передаются между рабочими узлами...
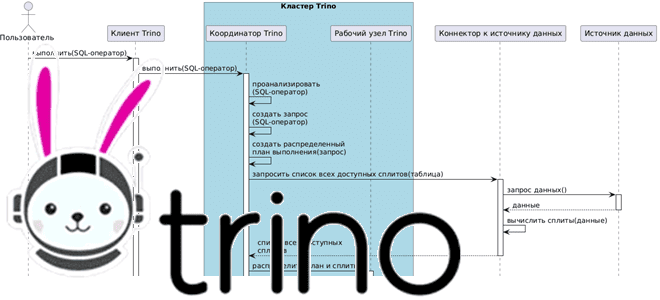
Как взаимодействуют рабочие узлы Trino между собой и с координатором кластера, а также с клиентскими приложениями и драйверами при выполнении SQL-запросов к данным из внешних источников без их фактического копирования. Последовательность выполнения запросов в кластере Trino Продолжая разбираться с Trino, сегодня рассмотрим, как этот аналитический движок с массово-параллельной архитектурой (MPP,...
Как без копирования анализировать данные из разных источников в реальном времени с помощью SQL-запросов: каталоги и коннекторы Trino. Коннекторы Trino: как они работают и что настроить в каталоге Вчера мы разобрали, как устроен кластер Trino – аналитического движка с массово-параллельной архитектурой (MPP, Massively Parallel Processing), который обрабатывает данные на нескольких...
Как с помощью SQL-запросов анализировать огромные объемы данных из множества источников в реальном времени без их фактического копирования. Архитектура и принципы работы MPP-движка Trino. Что такое Trino и зачем он нужен Массово-параллельная архитектура (MPP, Massively Parallel Processing) с разделяемой памятью, когда система состоит из отдельных узлов, которые вместе выполняют одну...
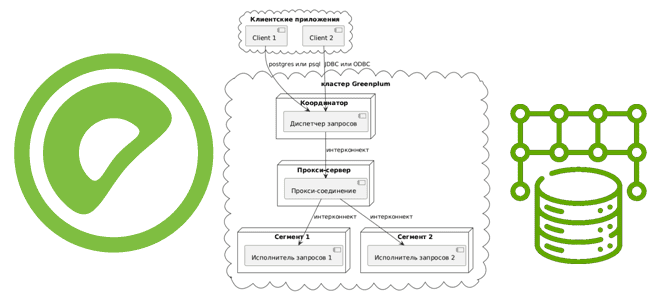
Как сегменты Greenplum взаимодействуют друг с другом для выполнения распределенных SQL-запросов, чем UDPIFC-режим интерконнекта лучше TCP-протокола, зачем проксировать межсетевые соединения и какими командами это сделать. Что такое интерконнекты в Greenplum Greenplum представляет собой массив отдельных баз данных PostgreSQL 12, работающих вместе для представления единого образа базы данных. Точкой входа в...
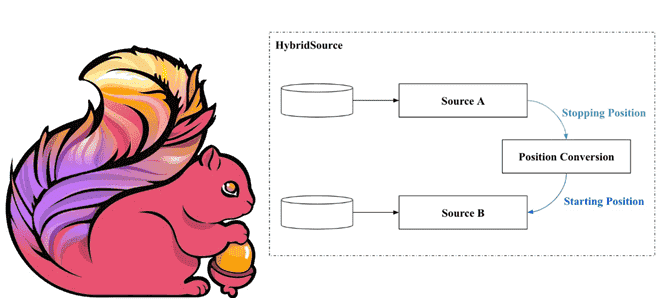
Как задание Apache Flink может читать информацию из разных источников данных в одном потоке. Что такое HybridSource и как с ним работать: разбираем на примере файла и топика Kafka. Что такое гибридный источник данных Иногда заданию Flink необходимо считывать данные из нескольких источников в последовательном порядке. Напомним, источником данных для...

23 октября 2024 года опубликован предварительный выпуск Apache Flink. Знакомимся с самыми яркими новинками этого мажорного релиза: удаленные API, коннекторы и конфигурации, динамическая оптимизация логических планов, а также дизагрегированное состояние и управление им. Критические изменения: удаление устаревших компонентов Начнем с критических изменений, связанных с удалением устаревших компонентов. В Apache Flink...
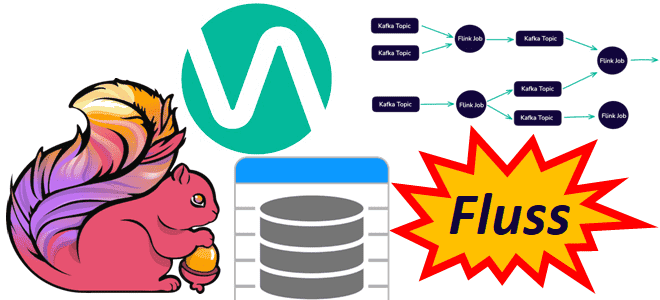
Чтобы сделать конвейеры обработки данных еще более эффективными, устраняя промежуточные хранилища для потоковых вычислений и сократить количество ETL-инструментов, немецкая компания Ververica разработала Fluss – потоковое хранилище для Apache Flink. Читайте далее, что это и чем полезно в непрерывной обработке потоков Big Data. Что не так с архитектурой конвейеров обработки данных...
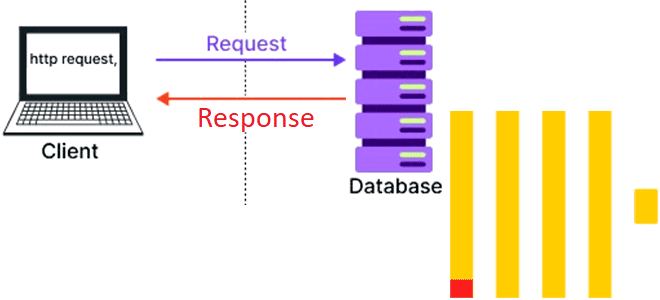
Как реализовать систему с двухзвенной архитектурой на ClickHouse и браузере. Возможности колоночной СУБД для создания одностраничных веб-приложений. Возможности ClickHouse для одностраничных веб-приложений Хотя трехзвенная архитектура (клиент -> бэк-> база данных) уже давно стала стандартом де-факто в разработке веб-приложений, двухзвенная архитектура, когда бизнес-логика переносится в базу данных, до сих пор встречается....