
Сегодня мы рассмотрим популярные Big Data инструменты обработки потоковых данных: Apache Kafka Streams и Spark Streaming: чем они похожи и чем отличаются. Стоит сказать, что Спарк Стриминг и Кафка Стримс – возможно, наиболее популярные, но не единственные средства обработки информационных потоков Big Data. Для этой цели существует еще множество альтернатив,...

В этой статье мы продолжим говорить про основы Apache Kafka Streams для начинающих и рассмотрим одно из самых важных свойств Кафка – возможность обработки любых данных, накопленных с начала работы Big Data системы. Что такое окна Apache Kafka Streams и зачем они нужны Кафка обеспечивает объективную достоверность накопленных исторических данных...
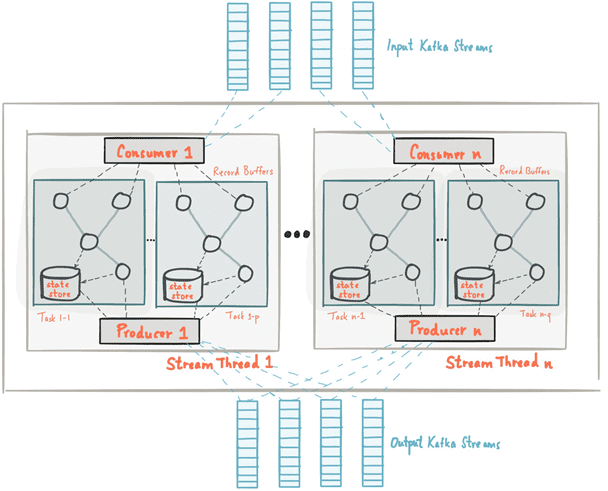
Как мы уже писали, в Apache Kafka Streams таблица и поток данных – это базовые и взаимозаменяемые понятия. Сегодня поговорим о том, как работать с этими объектами Big Data с помощью внутренних средств Кафка Стримс, используя готовые методы высокоуровневого языка DSL и низкоуровневый API-интерфейс для распределенной обработки потоковых данных в...
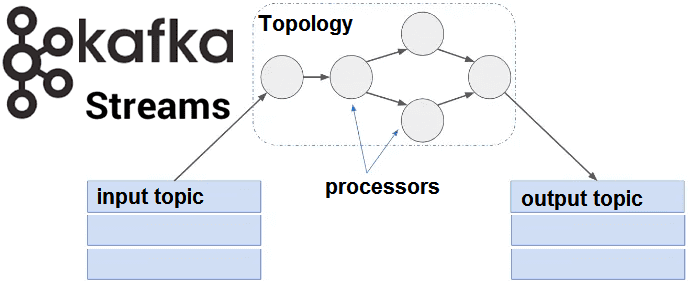
В продолжение темы про основы Apache Kafka Streams для начинающих, сегодня мы поговорим про то, как абстрактные понятия топика (topic), таблицы (table) и потока (stream) позволяют распараллелить обработку информационных потоков. Читайте в нашем новом материале, что такое обработчики потоков Кафка Стримс, как они обрабатывают разделы топиков (topic partition) Kafka и...
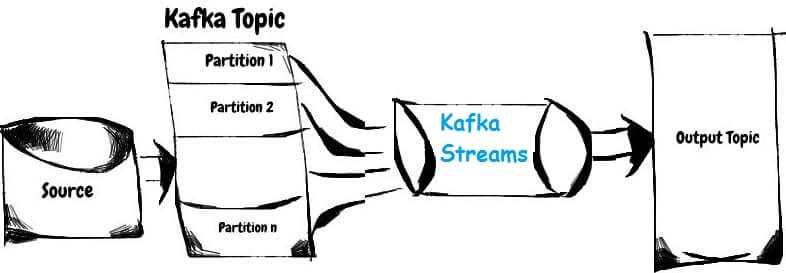
Сегодня мы поговорим про базовые понятия Apache Kafka Streams: потоки, таблицы и топики Кафка. Читайте в нашей статье, как Stream, Table и Topic связаны между собой, чем они похожи, когда таблица становится потоком и почему это обеспечивает эластичность и отказоустойчивость распределенных потоковых приложений Big Data. Что такое таблица, топик и...
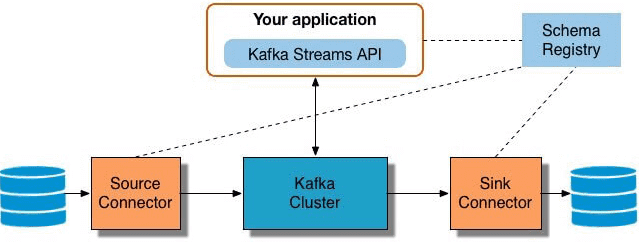
Мы уже рассказывали про Apache Kafka Streams API. В продолжение этой темы, сегодня отметим ключевые преимущества этой технологии, особенно важные для DevOps-инженера и разработчика Big Data систем, а также поговорим про некоторые недостатки и возможные альтернативы Кафка Стримс API. 5 главных достоинств Apache Kafka Streams API Для DevOps-инженера Big Data...
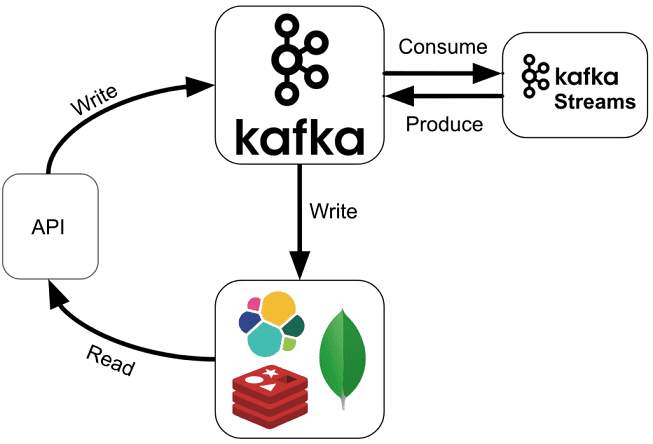
Продолжая разговор про Apache Kafka Streams, сегодня мы расскажем, как API этой мощной библиотеки упрощает жизнь DevOps-инженеру и разработчику Big Data систем. Читайте в нашей статье, как Kafka Streams API эффективно обрабатывать большие данные из топиков Кафка на лету без использования Apache Spark, а также быстро создавать и развертывать распределенные...

Читайте в нашей сегодняшней статье, как Apache Kafka Streams помогает быстро создавать приложения для обработки потоков Big Data без кластера Кафка, работать с состояниями распределенных программ без базы данных, эффективно тестировать и разворачивать потоковые микросервисы согласно DevOps-подходу, а также реальные кейсы практического применения этой технологии. Что такое Apache Kafka Streams...

Продолжая разговор про форматы Big Data файлов, сегодня мы рассмотрим разницу между линейными и колоночными типами, а также расскажем о том, как выбирать между AVRO, Sequence, Parquet, ORC и RCFile при работе с Apache Hadoop, Kafka, Spark, Flume, Hive, Drill, Druid и других средствах работы с большими данными. Итак, форматы...

Мы уже упоминали формат Parquet в статье про Apache Avro, одну из наиболее распространенных схем данных Big Data, часто используемую в Kafka, Spark и Hadoop. Сегодня рассмотрим более подробно, чем именно хорошо Apache Parquet и как он отличается от других форматов Big Data. Что такое Apache Parquet и как он...

Для высоконагруженных Big Data систем и платформ интернета вещей (Internet of Things, IoT) с непрерывными информационными потоками Apache Kafka, практически, стала стандартом де факто для обмена сообщениями и управления очередями. Аналогичную популярность среди DevOps-инструментов завоевал Kubernetes (K8s) как наиболее мощное средство для автоматизации развертывания и управления контейнеризованными приложениями. В этой...

Мы уже рассказывали, зачем нужна интеграция Apache Kafka и Spark Streaming. Сегодня рассмотрим, как технически организовать такой Big Data конвейер по непрерывной обработке потоковых данных в режиме реального времени. Способы интеграции Наладить двустороннюю связь между Apache Kafka и Spark Streaming возможны следующими 2-мя способами: получение сообщений через службу синхронизации Zookeeper...
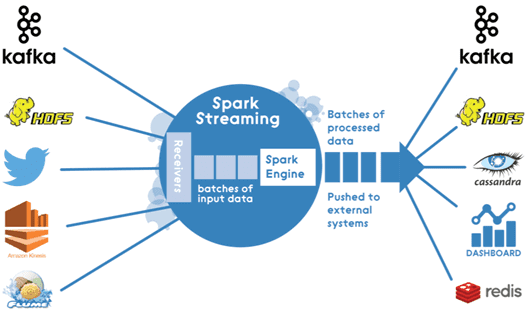
В этой статье мы рассмотрим архитектуру Big Data конвейера по непрерывной обработке потоковых данных в режиме реального времени на примере интеграции Apache Kafka и Spark Streaming. Что такое Spark Streaming и для чего он нужен Spark Streaming – это надстройка фреймворка с открытым исходным кодом Apache Spark для обработки потоковых...

Apache Kafka – не единственный программный брокер сообщений и система управления очередями, используемая в высоконагруженных Big Data проектах. Кафка часто сравнивают с другим популярным продуктом аналогичного назначения – RabbitMQ. В сегодняшней статье мы рассмотрим, чем похожи и чем отличаются Apache Kafka и RabbitMQ, а также поговорим о том, что следует...

Мы уже рассказывали о сериализации, схемах данных и их важности в Big Data на примере Schema Registry для Apache Kafka. В продолжение ряда статей про основы Кафка для начинающих, сегодня мы поговорим про Apache Avro – наиболее популярную схему и систему сериализации данных: ее особенностях и применении в технологиях Big...
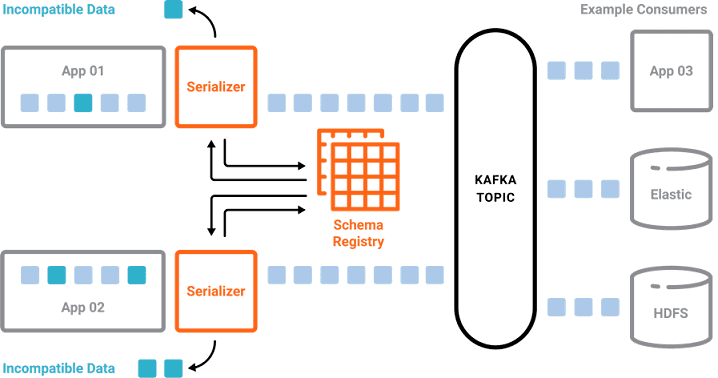
Продолжая серию публикаций про основы Apache Kafka для начинающих, в этой статье мы рассмотрим, зачем этой распределенной системе управления сообщениями нужен реестр схем данных (Schema Registry) и что такое сериализация файлов Big Data. Что такое схемы данных в Big Data и как они используются Понятие схемы неразрывно связано с форматом...

В рамках серии публикаций про основы Apache Kafka для начинающих, сегодня мы поговорим про информационную безопасность этой популярной в сфере Big Data распределенной системы управления сообщениями: шифрование, защищенные протоколы, аутентификация, авторизация и другие средства cybersecurity. Что обеспечивает безопасность Apache Kafka в кластере Big Data Информационная безопасность Apache Kafka основана на...
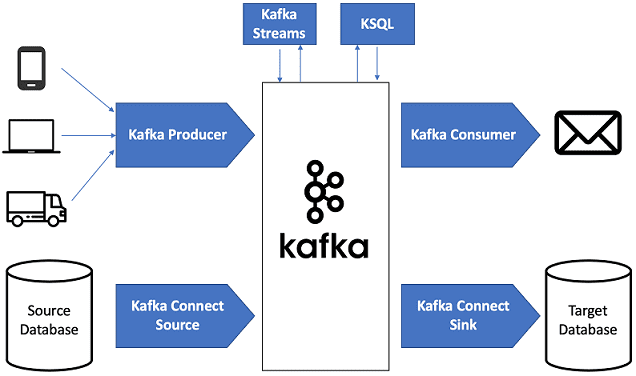
Продолжая разговор про основы Apache Kafka, сегодня мы рассмотрим, почему этот распределённый брокер сообщений стал таким популярным в архитектуре систем Big Data. Читайте в нашей статье, как Кафка обеспечивает высокую производительность процессов сбора и агрегации информационных потоков от множества источников, надежно гарантируя долговечную сохранность сообщений, и эффективно интегрируется с другими...
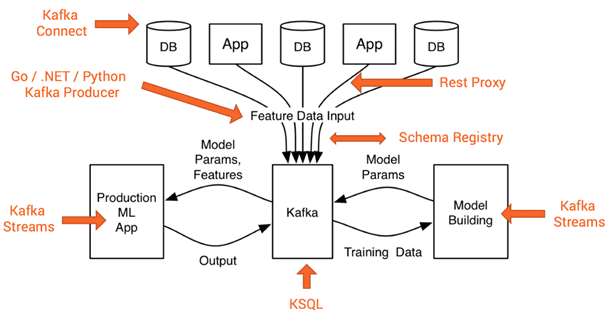
Рассмотрев основы Apache Kafka, сегодня мы расскажем о месте этого распределённого брокера сообщений в архитектуре Big Data систем. Читайте в нашей статье, какие компоненты Кафка обеспечивают ее использование в программных продуктах машинного обучения (Machine Learning, ML), интернете вещей (Internet Of Things, IoT), системах бизнес-аналитики (Business Intelligence, BI), а также других...

Мы уже упоминали Apache Kafka в статье про промышленный интернет вещей (Industrial Internet Of Things, IIoT). Сегодня поговорим о том, где и для чего еще в Big Data проектах используется эта распределённая, горизонтально масштабируемая система обработки сообщений. Как работает Apache Kafka Apache Kafka позволяет в режиме онлайн обеспечить сбор и...