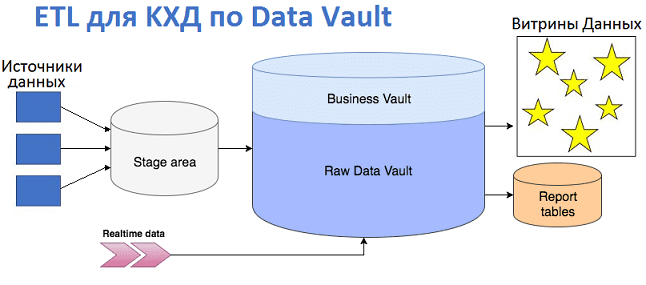
Продолжая разговор про проектирование корпоративных хранилищ данных с использованием подхода Data Vault, сегодня мы рассмотрим, как эта модель влияет на дизайн ETL-процессов и их реализацию. Читайте в нашей статье про загрузку данных в КХД по модели Data Vault и проблемы, которые могут при этом возникнуть, а также способы их решения...
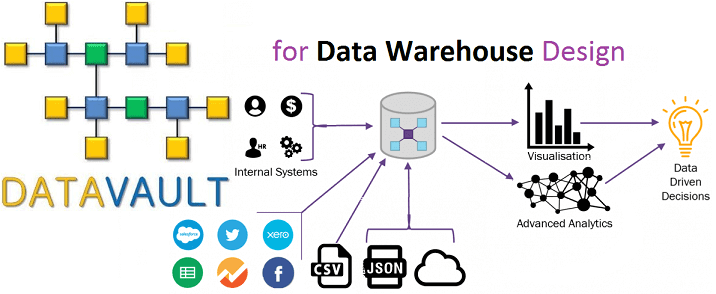
Вчера мы рассмотрели, что такое Data Vault, почему возникла эта модель и чем она полезна при проектировании архитектуры корпоративных хранилищ данных (КХД) и озер данных (Data Lake). Сегодня разберем ключевые понятия Data Vault и поговорим про возможности Data Vault 2.0 для области больших данных (Big Data). Ключевые понятия Data Vault...
Сегодня мы поговорим о проектировании архитектуры корпоративных хранилищ данных (КХД) и рассмотрим, какие методы и инструменты используются для моделирования структуры DWH и динамики ETL-процессов. В этой статье про основы Data Modelling разберем, что такое OLAP и OLTP, почему 3-я нормальная форма стала стандартом в SQL-СУБД, чем схемы звезды отличается от...

В продолжение темы про корпоративные хранилища данных, сегодня мы рассмотрим облачные варианты Data Warehouse с учетом тренда на расширенную аналитику Big Data на базе машинного обучения. Читайте в нашей статье про синергию классической LSA-архитектуры локального КХД с Лямбда-подходом, MPP-СУБД, а также Apache Hadoop, Spark, Hive и другими технологиями больших данных....

В этой статье мы расскажем, что такое корпоративное хранилище данных, зачем оно нужно и как устроено. Еще рассмотрим основные достоинства и недостатки Data Warehouse, а также чем оно отличается от озера данных (Data Lake) и как традиционная архитектура КХД может использоваться при работе с большими данными (Big Data). Где хранить...

Мы уже рассказывали про профессиональный стандарт бизнес-аналитика – руководство BABOK и его значимость в области больших данных. Сегодня рассмотрим еще 3 подобных свода знаний, которые полезны для архитектора, разработчика, менеджера, инженера, исследователя и аналитика Big Data: PMBOK, SWEBOK и DMBOK. А также разберем, что такое EABOK и насколько это применимо...
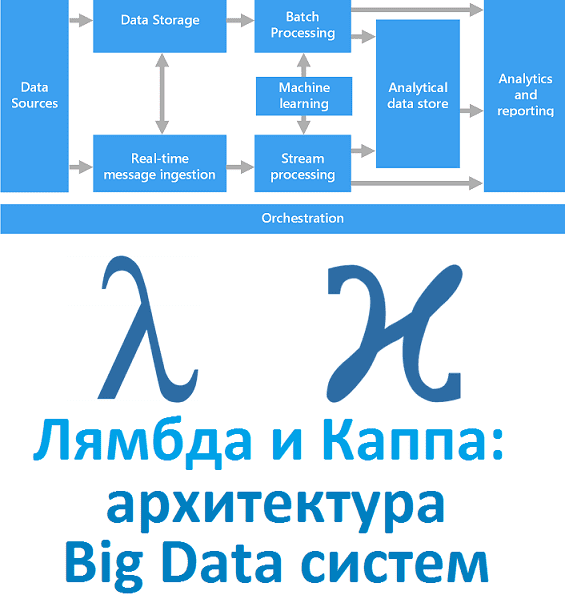
Вчера мы рассказали, что такое лямбда-архитектура. Сегодня рассмотрим Каппа - альтернативный подход к проектированию Big Data систем. Читайте в нашей статье, зачем нужна эта концепция, каковы ее достоинства и недостатки, чем Каппа отличается от Лямбда, где это используется на практике и при чем тут Apache Kafka с Machine Learning. Зачем...
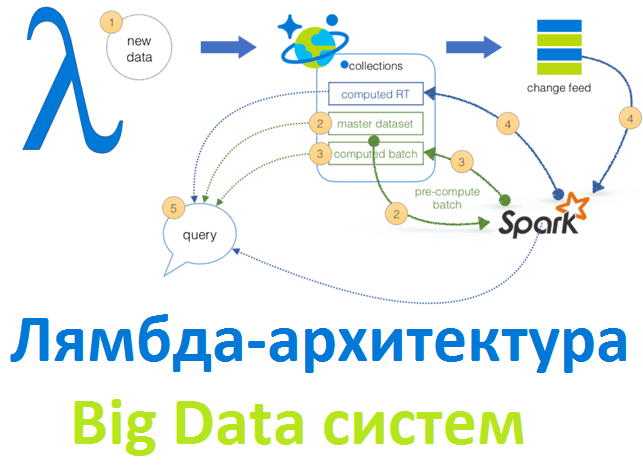
Рассматривая основы больших данных, сегодня мы расскажем лямбда-архитектуру, одну из двух главных подходов к построению Big Data систем. Читайте в нашей статье, зачем нужна эта концепция и как она работает, а также при чем тут машинное обучение, интернет вещей, Apache Spark и Hadoop. Что такое Лямбда-архитектура и зачем она нужна...
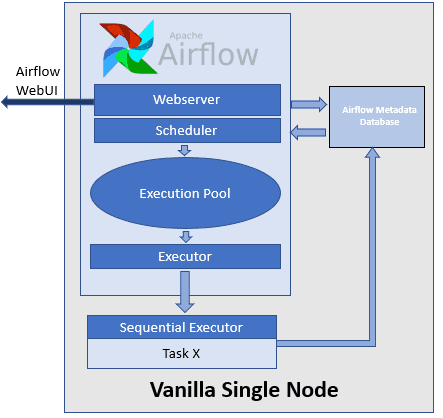
Недавно мы рассказывали про Airflow Kubernetes Executor, который позволяет выполнять задачи DAG-графа Эйрфлоу в среде Kubernetes, развертывая Docker-контейнер на отдельном пользовательском модуле (pod). Сегодня рассмотрим, какие еще есть исполнители задач в Apache Airflow, как они используются при автоматизации batch-процессов обработки больших данных и с какими проблемами можно столкнуться при их...
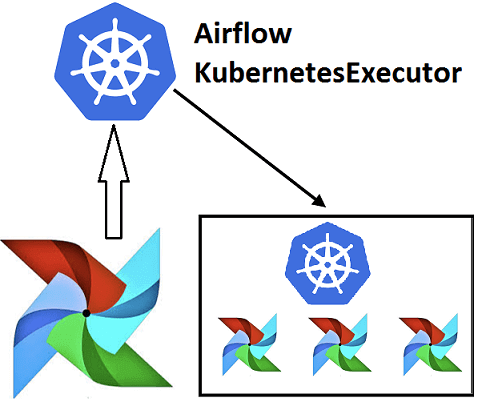
Эффективное обучение AirFlow, также как курсы по Spark, Hadoop, Kafka и другим технологиям больших данных (Big Data) также включают нюансы интеграции этого фреймворка с другими средами. Например, вчера мы рассматривали преимущества DevOps-подхода к разработке Data Flow на примере взаимосвязи Apache Airflow с Kubernetes посредством специальных операторов. Продолжая эту тему, сегодня...

Вчера мы рассказали, почему запускать Airflow на Kubernetes – это эффективно и выгодно для всех участников batch-процессов с большими данными (Big Data): разработчиков Data Flow, Data Scientist’ов, аналитиков и инженеров. Сегодня рассмотрим, что такое Airflow Kubernetes Operator и чем он отличается от подобной разработки компании Google. Как работает AirFlow Kubernetes...

Чтобы обучение Airflow было максимально приближенным к практике, сегодня мы поговорим про особенности реального внедрения этого фреймворка для разработки, планирования и мониторинга пакетных процессов обработки больших данных (Big Data) с учетом современного DevOps-подхода. Читайте в нашей статье, зачем вообще нужна связка Apache Эйрфлоу с Kubernetes и как это реализовать технически....

Продолжая говорить про обучение Airflow, сегодня мы рассмотрим ключевые преимущества и основные проблемы этой библиотеки для автоматизации часто повторяющихся batch-задач обработки больших данных (Big Data). Также мы собрали для вас пару полезных советов, как обойти некоторые ограничения Airflow на примере кейсов из Mail.ru, IVI и АльфаСтрахования. Чем хорош Apache AirFlow:...

Обычно курсы по Spark подробно рассказывают, чем хорош этот Big Data фреймворк для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных. Но, чтобы обучение Apache Spark было максимально полезным, стоит знать и о недостатках этого многофункционального инструмента обработки больших данных. Сегодня мы рассмотрим некоторые проблемы, которые возникают при практическом...

Однажды мы уже рассматривали, зачем Apache Kafka, Hadoop, HBase и другие Big Data системы используют Zookeeper, почему он необходим в распределенных проектах и чем можно заменить его заменить. Сегодня поговорим о том, как работает этот популярный централизованный сервис для поддержки информации о конфигурации, именования, обеспечения синхронизации распределенных приложений и предоставления...

Рассматривать обучение Кафка интереснее на практических примерах. Сегодня мы расскажем, как Apache Kafka применяется в одной из крупнейших промышленных компаний России - ПАО «Северсталь». Эта статья написана на основе выступления Доната Фетисова, главного архитектора «Северсталь Диджитал». Доклад был представлен 7 декабря 2019 года на очередном ИТ-митапе компании Авито по Big...

Вчера мы рассказывали, от чего зависит скорость работы Apache Kafka и как можно повысить. Сегодня рассмотрим подробнее, как именно конфигурация отправителей (производителей, producers) сообщений влияет на общую производительность этой распределенной Big Data системы потоковой агрегации событий. Что такое конфигурация производителей Apache Kafka Напомним, общая производительность Кафка зависит от следующих факторов:...

Продолжая практическое обучение Kafka, сейчас мы рассмотрим, от чего зависит производительность этой распределенной Big Data системы потоковой агрегации событий. Частично эту тему мы уже рассматривали в статье про применение Кафка в высоконагруженных проектах. Читайте в сегодняшнем материале, какие параметры влияют на скорость работы Кафка и как можно ее повысить. Как...
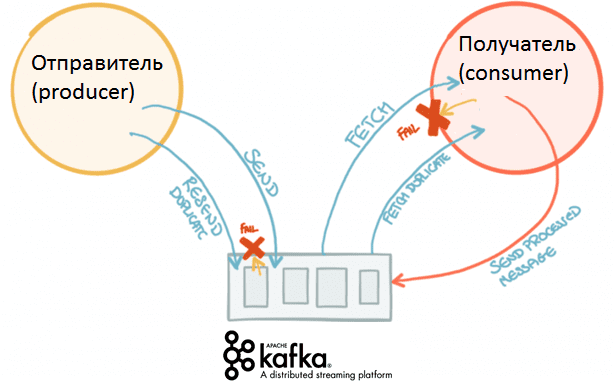
Вчера мы говорили про концепцию QaaS, очереди сообщений в Apache Kafka и другие проблемы производительности высоконагруженных систем с использованием этой Big Data платформы. Сегодня рассмотрим сложности многопоточной обработки событий в разном порядке: когда возникают подобные ситуации и как их решить. Для этого еще раз сравним Кафку с ее вечным конкурентом,...

При всех достоинствах Apache Kafka, для этого популярного Big Data средства управления сообщениями характерны определенные трудности в обеспечении производительности. Сегодня мы поговорим про некоторые проблемы использования этого распределенного брокера сообщений в высоконагруженных системах. В качестве реального примера рассмотрим особенности практического использования Кафка в отечественном сервисе объявлений Авито. Что такое высоконагруженная...