
Чтобы добавить в наши курсы для дата-инженеров еще больше реальных примеров и лучших DataOps-практик, сегодня мы расскажем, как специалисты крупной норвежской компании DNB обеспечивают надежный доступ к чистым и точным массивам Big Data, применяя передовые методы проектирования данных и реализации конвейеров их обработки. В этой статье мы собрали для вас...

Аналитика больших данных напрямую связана с их качеством, которое необходимо отслеживать на каждом этапе непрерывного конвейера их обработки (Pipeline). Сегодня рассмотрим методы и средства обеспечения Data Quality на примере корпорации Airbnb. Читайте далее про лучшие практики повышения качества больших данных от компании-разработчика самого популярного DataOps-инструмента в мире Big Data, Apache...

Продолжая разговор про обучение Apache Spark для инженеров данных на практических примерах, сегодня разберем, как организовать интеграцию этого Big Data фреймворка с MPP-СУБД Greenplum. В этой статье мы расскажем о коннекторе Greenplum-Spark, который позволяет эффективно связывать эти средства работы с большими данными, выстраивая аналитический конвейер их обработки (data pipeline). Типовые...

В этой статье разберем, что такое прикладная аналитика больших данных на примере практического использования Apache Kafka и Druid в Netflix для обработки и визуализации метрик пользовательского поведения. Читайте далее, зачем самой популярной стриминговой компании отслеживать показатели клиентских устройств и как это реализуется с помощью Apache Druid, Kafka и других технологий...

Недавно мы рассказывали про систему онлайн-аналитики Big Data на базе Apache Kafka, Spark Streaming и Druid для площадки рекламных ссылок Outbrain, а затем на этом же кейсе рассматривали, зачем нужен Graceful shutdown в потоковой обработке больших данных. Сегодня в рамках этого примера разберем, как снизить нагрузку при потоковой передаче множества...
Продвигая наши курсы по Apache AirFlow для инженеров Big Data, сегодня расскажем, чем этот фреймворк отличается от Luigi – другого достаточно известного инструмента оркестровки ETL-процессов и конвейеров обработки больших данных. В этой статье мы собрали для вас сходства и отличия Apache AirFlow и Luigi, а также их достоинства и недостатки,...
Чтобы максимально приблизить обучение Airflow к практической работе дата-инженера, сегодня мы рассмотрим, какие еще есть альтернативы для оркестрации ETL-процессов и конвейеров обработки больших данных. Читайте далее, что такое Luigi, Argo, MLFlow и KubeFlow, где и как они используются, а также почему Apache Airflow все равно остается лучшим инструментом для оркестрации...

Продолжая разбирать, как работает аналитика больших данных на практических примерах, сегодня мы рассмотрим, что такое Graceful shutdown в Apache Spark Streaming. Читайте далее, как устроен этот механизм «плавного» завершения Спарк-заданий и чем он полезен при потоковой обработке больших данных в рамках непрерывных конвейеров на базе Apache Kafka и других технологий...

Современная аналитика больших данных ориентируется на обработку Big Data в реальном времени. Такие вычисления «на лету» позволяют в режиме онлайн узнавать о критически важных производственных показателях и оперативно понимать клиентские потребности. Это существенно ускоряет и автоматизирует цикл принятия управленческих решений в соответствии с требованиями сегодняшнего бизнеса. Обычно для реализации архитектуры...

Сегодня поговорим про особенности перехода с локального Hadoop-кластера в облачное SaaS-решение от Google – платформу Dataproc. Читайте далее, какие 5 шагов нужно сделать, чтобы быстро развернуть и эффективно использовать облачную инфраструктуру для запуска заданий Apache Hadoop и Spark в системах хранения и обработки больших данных (Big Data). Шаги переноса Data...

В этой статье рассмотрим архитектуру и принципы работы системы хранения, аналитической обработки и визуализации больших данных на базе компонентов Hadoop, таких как Apache Spark, Hive, Tez, Ranger и Knox, развернутых в облачном Google-сервисе Dataproc. Читайте далее, как подключить к этим Big Data фреймворкам BI-инструменты Tableau и Looker, а также что обеспечивает...

Вчера мы рассматривали проблему управления накладными расходами в сложных конвейерах обработки больших данных на примере использования Apache AirFlow в агрегаторе аренды частного жилья Airbnb. Сегодня разберем, как именно инженеры компании решили проблему роста накладных расходов, отделив бизнес-логику от логики оркестрации в конвейерах Spark-заданий. Читайте далее про принципы проектирования Big Data...
Продолжая разговор про конвейеры обработки больших данных, сегодня рассмотрим пример использования Apache AirFlow в агрегаторе аренды частного жилья Airbnb. Читайте далее, в чем коварство накладных расходов при росте ETL-операций и других data pipeline’ов по запуску и выполнению заданий Spark, Hadoop и прочих технологий Big Data. Еще в этой статье разберем,...

Чтобы сделать наши курсы по Apache Kafka для разработчиков Big Data систем еще более интересными, а обучение – запоминающимся, сегодня мы рассмотрим еще несколько примеров реализации микросервисной архитектуры на этой стриминговой платформе. А также поговорим про проблемы удаления данных в этой архитектурной модели, разобрав кейс компании Twitter по построению корпоративного...

В этой статье мы рассмотрим комплексный конвейер (pipeline) обработки больших данных с помощью алгоритмов машинного обучения (Machine Learning) для системы речевого анализа Callinter от китайской компании Fano Labs. Apache Kafka играет ключевую роль в этом аналитическом конвейере, ежедневно обеспечивая бесперебойную стабильность и высокую производительность интеллектуальной обработки нескольких тысяч часов звонков....
Продолжая разговор про инженерию больших данных, сегодня рассмотрим, как построить ETL-pipeline на открытых технологиях Big Data. Читайте далее про получение, агрегацию, фильтрацию, маршрутизацию и обработку потоковых данных с помощью Apache NiFi, Kafka и Spark, преобразование JSON, а также обогащение и сохранение данных в Hive, HDFS и Amazon S3. Пример потокового...

Мы уже писали, что такое Kafka Connect и как этот инструмент обеспечивает потоковую передачу данных между Apache Kafka и другими системами на примере интеграции с Elasticsearch. Сегодня рассмотрим новый коннектор, который позволяет загружать данные из топиков Apache Kafka в платформу удаленного мониторинга работоспособности мобильных и веб-приложений New Relic через гибкий REST API....
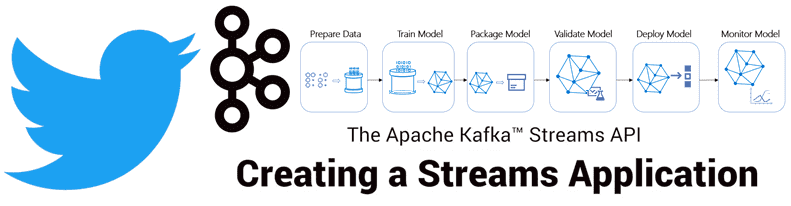
Продолжая разговор про практическое применение Apache Kafka на примере организации рекомендательной системы Twitter, сегодня мы рассмотрим, как с помощью Kafka Streams был разработан конвейер сбора и агрегации данных для машинного обучения (Machine Learning). Читайте в нашей статье про особенности объединения больших данных через LeftJoin и InnerJoin в Apache Kafka Streams. Архитектура приложения...
Недавно мы рассказывали про преимущества event-streaming архитектуры с помощью Apache Kafka на примере The New York Times. В продолжение этой темы Apache Kafka, сегодня поговорим про использование этой Big Data платформы в Twitter для построения конвейера потоковой регистрации событий в рекомендательной системе на базе алгоритмов машинного обучения (Machine Learning). Как...

Apache NiFi – это простая и мощная система для обработки и распределения больших данных в потоковом режиме, которая отлично справляется с огромными объемами и скоростями, оперируя с сотнями гигабайт и даже терабайтами информации. Однако, на практике при работе с этой Big Data платформой можно столкнуться с проблемой ввода-вывода (IOPS, Input-Output...