
Почему в одной организации возникает рассогласование данных, чем опасна такая рассинхронизация, как ее обнаружить и устранить: подходы и решения для повышения качества данных. Что такое data silos и как найти локальные «болота данных» Рассогласование в данных возникает при разной логике обработки одной и той же информации. Это мешает принимать объективные...

Как выполняется вставка данных в ClickHouse, от чего зависит ее скорость и каким образом ее повысить: последовательность операций загрузки и ее оптимизации. От чего зависит скорость вставки данных в ClickHouse Поскольку ClickHouse часто используется для построения хранилищ или витрин данных, скорость загрузки данных в эту базу очень важна. Хотя на...
Денормализация таблиц, оптимизация SQL-запросов, словари вместо измерений и AggregatingMergeTree-движок с инкрементными матпредставлениями для приема измененных данных из PostgreSQL в ClickHouse. Оптимизация SQL-запросов Хотя передача изменений из PostgreSQL в ClickHouse может сопровождаться дублированием или потерями данных, эти проблемы решаемы, о чем мы рассказывали здесь и здесь. Однако, репликация данных из реляционной...

Чем ML-сценарии работы с данными отличаются от типовых аналитических нагрузок и почему колоночные форматы не справляются с ними: сложности Parquet и ORC в хранении данных для машинного обучения. Почему колоночные форматы не справляются со всеми ML-сценариями Хотя колоночный формат хранения данных хорошо подходит для многих современных сценариев, таких как машинное...
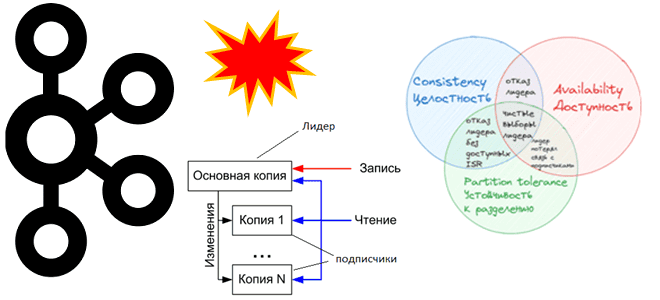
Как Apache Kafka реализует компромиссы CAP-теоремы и при чем здесь чистые выборы лидера: проблемы целостности, доступности и устойчивости в распределенной системе с репликацией данных. CAP-теорема в кластере Apache Kafka При публикации сообщений в Apache Kafka, развернутой в кластере из нескольких узлов, данные сохраняются в брокере-лидере раздела, а затем реплицируются по...
Почему ключи сортировки в ClickHouse могут стать причиной появления дублей или пропусков при CDC-передаче изменений из PostgreSQL и как этого избежать: особенности логической репликации из транзакционной базы данных в аналитическую. Влияние ключей сортировки на CDC-передачу изменений из PostgreSQL в ClickHouse Продолжая разбираться с дублированием данных при передачи изменений из PostgreSQL...
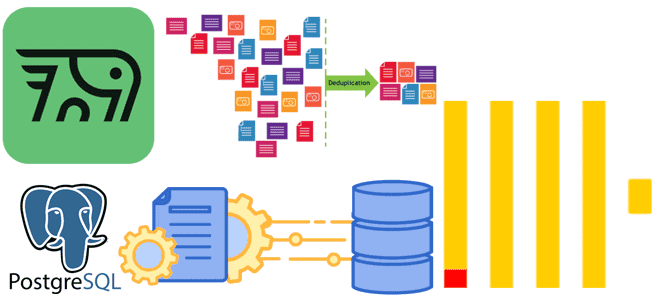
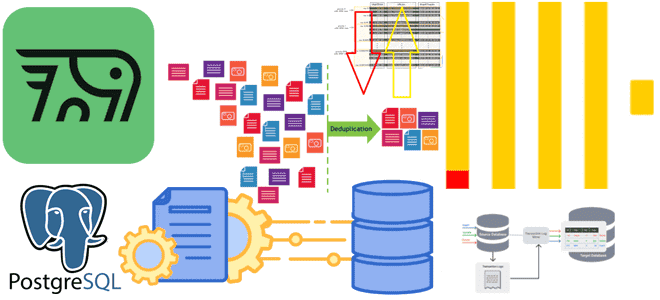
Почему табличный движок ReplacingMergeTree в PeerDB и ClickPipes не избавит от дублей при передаче измененных данных из PostgreSQL в ClickHouse и можно ли полностью выполнить дедупликацию с помощью модификатора FINAL, политики строк, обновляемых представлений или агрегатных и оконных функций. Как движок ReplacingMergeTree допускает дубли при импорте изменений из PostgreSQL в...
Как передать изменения данных из транзакционной базы в аналитическую без дублей и задержек: CDC-ETL из PostgreSQL в ClickHouse с PeerDB. CDC для ClickHouse с PeerDB и ClickPipes Возможности Clickhouse позволяют построить на нем корпоративное хранилище данных целиком или реализовать отдельный слой, например, для денормализованных витрин. Также совместное использование транзакционных и...
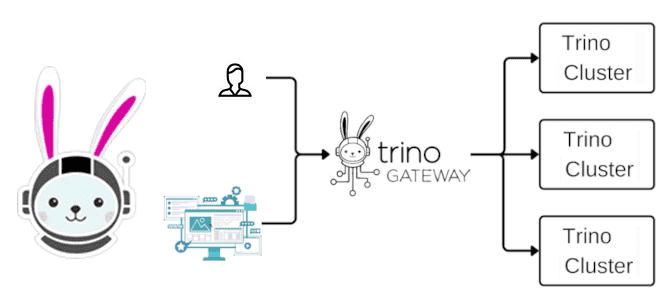
Что такое Trino Gateway, зачем он нужен и как работает: для чего делить один большой кластер Trino на несколько маленьких и как к ним обращаться без изменений на стороне клиентов. Проблемы бесконечного масштабирования кластера Благодаря горизонтальному масштабированию, о котором мы говорили вчера, кластер Trino можно расширять, добавляя новые рабочие узлы....
Почему можно программировать на Python для разработки JVM-приложений: как Java-фреймворки с Python API, такие как Apache Spark и Flink, транслируют Python-код, организуя межпроцессное взаимодействие. Способы трансляции Python-кода для исполнения в JVM Большинство фреймворков для разработки высоконагруженных приложений написаны на Java. Например, Apache Spark или Flink. При этом они предоставляют Python...
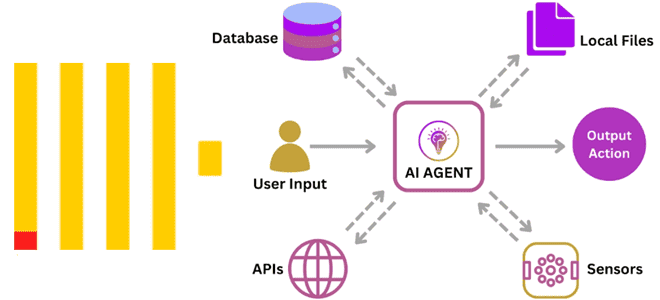
Зачем использовать ClickHouse для аналитики в реальном времени с агентами ИИ и как это сделать: современные вызовы внедрения LLM. Как реализовать ML-систему агентского ИИ с ClickHouse Продолжим разговор про агентский ИИ на основе LLM, когда ML-система не просто реагирует на запросы пользователя, а работает автономно, интеллектуально решая задачи без прямого...
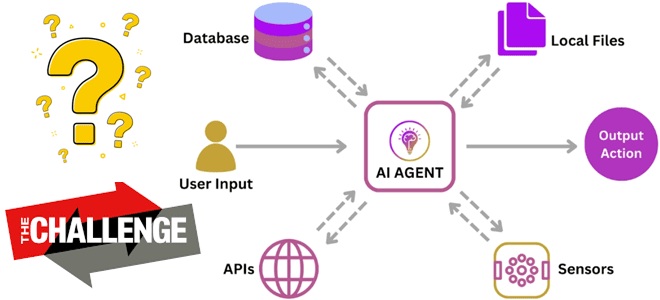
Чем хорош агентский ИИ, какие риски и проблемы с ним связаны, и как их избежать: технические и организационные меры внедрения ML-систем в реальный бизнес. Что сдерживает внедрение агентского ИИ Мы уже писали об агентском ИИ, когда ML-система не просто реагирует на запросы пользователя, а работает автономно, интеллектуально решая задачи без...

Особенности хранения и аналитической обработки JSON-документов в ClickHouse, MongoDB, Elasticsearch, DuckDB и PostgreSQL: объяснение бенчмаркингового теста. JSON в ClickHouse Недавно мы писали про бенчмаркинговое сравнение хранения и обработки JSON-данных в ClickHouse, MongoDB, Elasticsearch, DuckDB и PostgreSQL. В этом тесте, проведенном самими разработчиками ClickHouse, эта СУБД показала максимальную эффективность, которая обоснована...

Почему ClickHouse требует меньше места для хранения JSON-документов и быстрее выполняет аналитические запросы к ним по сравнению с MongoDB, Elasticsearch, DuckDB и PostgreSQL: бенчмаркинговый тест от разработчиков колоночной СУБД. Как Clickhouse делает быстрее агрегации в JSON-данных Хотя бенчмаркинговые тесты от вендоров редко бывают объективными, просматривать их довольно интересно. Недавно мне...
Почему Trino не заменит Flink, Spark и Airflow: границы применимости MPP-движка распределенного выполнения SQL-запросов к реляционным и нереляционным источникам данных. Почему Trino не заменит Flink, Spark и Airflow Хотя Trino отлично подходит для быстрой ad-hoc аналитики, позволяя SQL-запросами в реальном времени обращаться к различным базам данных, включая нереляционные хранилища и...
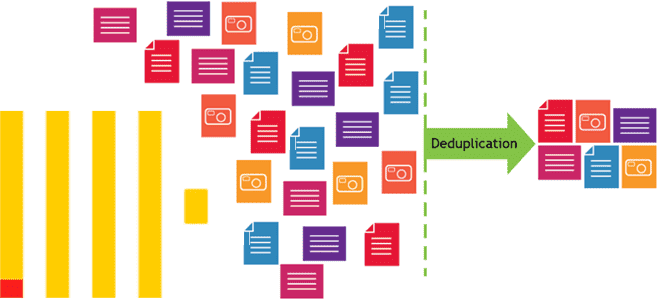
Почему в хранилище и витрину данных могут попасть дубли, чем это чревато и какие встроенные механизмы дедупликации есть в ClickHouse. Примеры OPTIMIZE-запросов и работы с движком ReplacingMergeTree. Причины дублирования данных и их последствия Дублирование данных в хранилищах и в витринах – довольно частая проблема в дата-инженерии. Это приводит к росту...

Чем Apache Beam отличается от Apache Flink, что и когда выбирать, зачем их совмещать для реализации сложных конвейеров обработки больших объемов данных с помощью распределенных stateful-приложений, и как это работает. Сходства и отличия Apache Beam и Flink Хотя Apache Beam является унифицированной моделью определения пакетных и потоковых конвейеров параллельной обработки данных,...

Что такое Apache Doris, как его использовать для построения хранилища данных и чем это отличается от ClickHouse. Сценарии применения и критерии выбора основы DWH. Что такое Apache Doris Недавно мы рассматривали, почему ClickHouse подходит для реализации хранилища данных на основе эталонной архитектуры Medallion благодаря поддержке более 70 форматов файлов, материализованным...
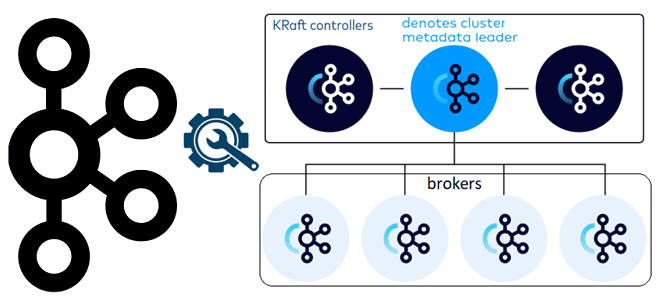
Чем контроллеры Kafka в режиме KRaft отличаются от режима Zookeeper, как их настроить и чем статический кворум отличается от динамического: краткий ликбез для администратора кластера. Брокеры и контроллеры: новые роли серверов Kafka в режиме KRaft Поскольку уже совсем скоро, в мажорном релизе Kafka 4.0, ожидается полный отказ от Zookeeper в...

Почему генеративный ИИ основан на потоковой обработке данных и EDA-архитектуре, для чего оценивать качество LLM-модели и как построить такую систему мониторинга: подходы и технологии. О важности потоковой обработки данных и EDA-архитектуры для LLM-систем Все больше современных бизнес-приложений включают в себя большие языковые модели (LLM, Large Language Model), чтобы автоматизировать поддержку...