
При том, что Apache Spark является одной из главных технологий стека Big Data, этот фреймворк не очень хорошо работает с множеством файлов небольшого размера. Поэтому в рамках обучения дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим, почему это происходит, зачем динамически сжимать файлы в Apache Spark и как это делает платформа...

Продолжая разбирать кейс компании Tesla по организации централизованного управления устройствами интернета вещей (Internet of Things, IoT), сегодня разберем, как выполняется обработка сообщений в топиках Apache Kafka с помощью Confluent Schema Registry и Kafka Streams. Читайте далее, как определить потоковый процессор для парсинга данных в CSV и JSON-форматах с использованием схемы...

В рамках курсов для дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим пример построения системы потоковой передачи для аналитики больших данных на базе Apache Kafka, Spark и Google BigQuery. Читайте далее про Proof of Concept для конвейера продуктовой аналитики, который обрабатывает 50 миллиардов событий каждый день, и какие важные уроки ИТ-архитектор...

Являясь лидером отрасли, IoT-устройства Tesla обрабатывают триллионы событий в день, чтобы повысить эффективность своих электроавтомобилей. Однако, такая производительность была получена не сразу: чтобы достичь ее, инженерам компании пришлось решить множество проблем из области интернета вещей (Internet of Things, IoT). Сегодня рассмотрим, как часть из них была решена с помощью Apache...
В рамках программы курсов по Greenplum и Arenadata DB, сегодня рассмотрим важную для разработчиков и администраторов тему об особенностях оптимизатора SQL-запросов GPORCA, который ускоряет аналитику больших данных лучше встроенного PostgreSQL-планировщика. Читайте далее, как выбирать ключ дистрибуции, почему для GPORCA важна унифицированная структура многоуровневой партиционированной таблицы и каким образом оптимизаторы обрабатывают...

YARN считается самым распространенным диспетчером ресурсов в кластерах Apache Hadoop и Spark, отвечая за выделение ресурсам распределенным приложениям. Сегодня в рамках обучения дата-инженеров и администраторов Hadoop рассмотрим достоинства и недостатки 3-х вариантов планирования ресурсов в YARN. Читайте далее, что такое иерархия очереди и как вычисляется ее мгновенная справедливая доля. Планирование...

Инженерия данных нужна не только большим компаниям с крупными Big Data проектами. Сегодня рассмотрим, как Apache AirFlow повышает эффективность low-code фреймворка Zapier с помощью своего REST API и Amazon SQS. Также читайте далее об интеграции приложений без разработки кода и удаленный запуск Matillion-заданий в AWS с AirFlow. Low Code интеграция...

В этой статье для дата-инженеров и администраторов Apache Kafka рассмотрим, зачем Confluent выпустил премиум коннектор Splunk S2S Source и как на базе этих платформ построить эффективную систему потоковой аналитики больших данных. Также читайте далее, что такое универсальный сервер рассылки Splunk и какие конфигурации коннектора позволяют автоматически создавать топик Kafka для сбора...
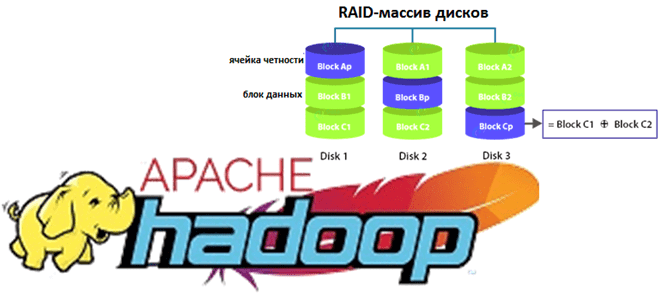
Недавно мы рассказывали про новые функции свежего релиза Apache Hadoop 3.3.1. Сегодня разберем подробнее, что такое Erasure Coding и как эта технология кодирования со стиранием экономит место в распределенной файловой системе HDFS. Также заглянем внутрь EC и рассмотрим, чем алгоритм Рида-Соломона лучше ассоциативной операции XOR для обеспечения отказоустойчивости хранилища больших...
Чтобы добавить в курсы по Apache AirFlow еще больше полезных примеров, сегодня рассмотрим, как избежать дублирования кода при загрузке данных. Этот пример пригодится дата-инженерам в работе с ELT-процессами наполнения информацией корпоративных хранилищ и озер данных. Читайте про фреймворк динамической загрузки данных на базе конфигурационных YAML-файлов, DAG-фабрик и загрузчиков. Проблема дублирования...

Поскольку Greenplum и Arenadata DB основаны на популярной open-source СУБД PostgreSQL, сегодня разберем, чем они отличаются от этой объектно-реляционной базы данных. Далее вас ждет краткий и понятный ответ на вопрос Greenplum vs PostgreSQL: сходства и отличия этих систем с учетом аналитики больших данных и практических кейсов дата-инженерии. Что общего между...

Специально для разработчиков распределенных приложений, Data Scientist’ов и аналитиков больших данных, работающих с Apache Spark, в этой статье мы собрали несколько полезных советов по ежедневным операциям в этом фреймворке. Читайте далее, как добавить библиотеку TypeSafe в файл sbt-конфигурации Spark-приложения, получить датафреймы из JSON-массивов и структур, а также обработать CSV-формат с...
В рамках курсов по Apache Kafka для разработчиков и администраторов кластера, сегодня заглянем под капот AdminClient и на практических примерах разберем, как динамически создавать новый топик и описывать его программным способом через API. Еще рассмотрим, почему метод deleteTopics() нужно применять очень осторожно, а также вспомним основы ООП, говоря про классы...

Чтобы дополнить наши курсы по Kafka и Spark интересными примерами, сегодня рассмотрим практический кейс разработки микросервисного конвейера машинного обучения на этих фреймворках. Читайте далее, зачем выносить ML-компонент в отдельное Python-приложение от остальной части Big Data pipeline’а, и как Docker поддерживает эту концепцию микросервисного подхода. Постановка задачи и компоненты микросервисного ML-конвейера...

Постоянно обновляя наши курсы по Apache Hadoop для администраторов кластеров и инженеров данных, сегодня рассмотрим главные новинки июньского релиза 2021. Читайте далее, как поддержка Erasure Coding сэкономит место в HDFS, зачем обновляться до 8-ой версии Java, чем хорош YARN Timeline Service v.2, как повысить надежность кластера Hadoop еще больше и...

Продолжая обучение основам Apache Hadoop для начинающих администраторов, сегодня рассмотрим архитектуру и принципы работы YARN в кластере. Также разберем, какие отказы могут случиться на каждом из его компонентов и как Resource Manager системы YARN обеспечивает высокую доступность кластера Apache Hadoop. Зачем Apache Hadoop нужен YARN и как он работает Поскольку...
6 июня 2021 года компания Confluent, которая продвигает коммерческую версию платформы Apache Kafka, выпустила новый релиз ksqlDB. Сегодня рассмотрим самые важные исправления ошибок и новые функции ksqlDB 0.19.0, уделив особое внимание SQL-запросам соединения таблиц через JOIN по внешнему ключу. ТОП-10 исправленных ошибок в новом релизе ksqlDB Напомним, ksqlDB – это...

Мы уже рассказывали про коннектор Greenplum-Spark, 2-я версия которого вышла в октябре 2020 года. А сегодня рассмотрим российскую альтернативу для отечественной MPP-СУБД Arenadata DB на базе Greenplum, выпущенную компанией Аренадата в июле 2021 года. Краткий обзор ADB-Spark Connector: архитектура, принципы работы, сценарии использования, а также отличия от PXF-фреймворка и варианта...

При том, что Apache Hadoop – высоконадежная экосистема хранения и аналитики больших данных, отказы случаются и в ней. Сегодня в рамках обучения начинающих администраторов и разработчиков Hadoop разберем, какие типы сбоев возможны в распределенной файловой системе HDFS и механизмы их предупреждения, а также рассмотрим процедуру вывода узлов из кластера для...

14 июля 2021 года вышел минорный релиз Apache NiFi – версия 1.14.0. Сегодня рассмотрим его главные фичи, исправленные ошибки и улучшения, уделив особое внимание новым функциям обеспечения информационной безопасности в этой популярной платформе управления потоками Big Data. ТОП-5 новинок Apache NiFi 1.14.0 В новом выпуске Apache NiFi 1.14.0 исправлено 139...