В этой статье поговорим про Viewflow: что такое, как устроено, чем полезно аналитикам данных и Data Scientist’ам. Встречайте новый фреймворк на базе Apache AirFlow от DataCamp – американского edu-стартапа в области ИИ, который упрощает создание и управление материализованными представлениями на SQL, R и Python в концепции low code, т.е. практически...
Совмещение Airflow с Kubernetes уже становится стандартом де-факто для дата-инженеров. Недавно мы рассказывали про 3 популярные среды развертывания и сопровождения этого ETL-фреймворка в Kubernetes. Продолжая эту тему, сегодня рассмотрим, какие операторы использовать для контейнерного запуска batch-задач, а также поговорим о том, как Docker-образы помогут решить проблему изменения версий Python и...

Для практического использования Apache Airflow в production дата-инженеру необходимо не только обучение основам работы с этим фреймворком, но и знания о базовой инфраструктуре его развертывания. Поэтому сегодня поговорим о 3-х популярных средах для развертывания и сопровождения этого ETL-фреймворка: Astronomer, Google Cloud Composer и Amazon Managed Workflows, разобрав их основные возможности...
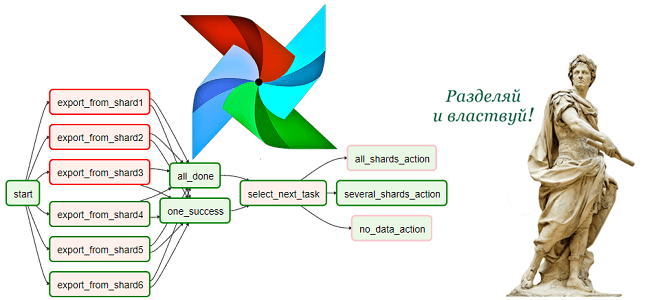
Чтобы сделать обучение дата-инженеров еще более полезным, сегодня мы рассмотрим проблему управления взаимозависимыми цепочками задач в Apache AirFlow. Читайте далее, как бразильская ИТ-компания QuintoAndar разработала промежуточный компонент Mediator на базе одноименного шаблона архитектурного проектирования ПО, чтобы облегчить взаимодействие между разными DAG’ами в конвейерах обработки больших данных. Проблема взаимозависимых DAG’ов в...

Практическое обучение дата-инженеров – это не просто курсы по основам Big Data, а полезные рекомендации с реальными примерами. Поэтому сегодня рассмотрим, как работать с DAG в Apache AirFlow еще эффективнее с помощью параметров конфигурации, плагинов, меток, шаблонов, переменных и еще 10 различных инструментов. 15 лучших практики для DAG в Apache...

Чтобы добавить в наши обновленные авторские курсы для дата-инженеров по Apache AirFlow еще больше интересного, сегодня продолжим разбирать полезные дополнения релиза 2.0 и поговорим, почему разделение фреймворка на пакеты делает его еще удобнее. Также рассмотрим практический пример создания общедоступного провайдера из локального Python-пакета с собственными операторами, хуками и прочими компонентами....
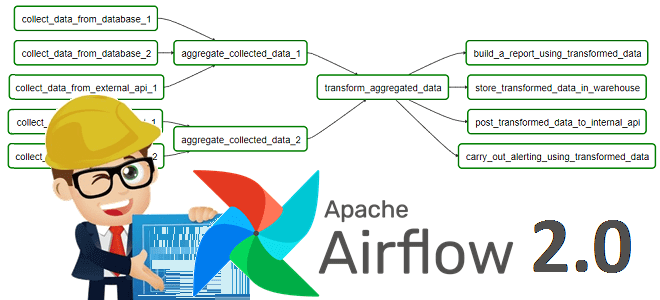
В поддержку наших полностью обновленных авторских курсов для инженеров данных по Apache AirFlow, сегодня рассмотрим новые способы определения DAG, которые были добавлены в релизе 2.0. Читайте далее, что под капотом TaskFlow API, как поместить задачи в TaskGroup, чем dag_policy отличается от task_policy и почему все это упрощает работу инженера Big...

Продолжая разговор про оптимизацию приложений Apache Spark в Kubernetes, сегодня разберем, как сократить расходы на облачный кластер с помощью спотовых узлов. А в качестве практического примера рассмотрим кейс компании Weather2020, дата-инженеры которой смогли всего за 3 недели развернуть террабайтные ETL-конвейеры в AWS с AirFlow и Spark на Kubernetes без глубокой...

Чтобы дополнить наши курсы по Spark для разработчиков распределенных приложений и инженеров данных практическими примерами, сегодня рассмотрим кейс американской ИТ-компании ThousandEyes, которая разрабатывает программное обеспечение для анализа производительности локальных и глобальных сетей. Читайте далее, как создать надежный конвейер и устойчивое озеро данных (Data Lake) для быстрой аналитики Big Data в...

Хорошие курсы дата-инженеров предполагают не только изучение теории и практики, но и проверку полученных знаний. Поэтому сегодня мы предлагаем вам открытый интерактивный тест по Apache AirFlow. Ответьте на 10 простых вопросов и узнайте, насколько хорошо вы знакомы с особенностями администрирования и эксплуатации этого популярного фреймворка для автоматизации batch-заданий обработки и...
Поскольку курсы инженеров Big Data предполагают практическое обучение на реальных кейсах, сегодня поговорим про тестирование конвейеров обработки и аналитики больших данных и разберем несколько прикладных примеров для компонентов экосистемы Apache Hadoop. Читайте далее про проверку работоспособности, а также поиск ошибок в Spark-заданиях и DAG-цепочках Airflow. Конвейер для конвейера: сложности тестирования...

В рамках обучения инженеров больших данных, вчера мы рассказывали о новой версии Apache AirFlow 2.0, вышедшей в декабре 2020 года. Сегодня рассмотрим особенности перехода на этот релиз: в чем сложности миграции и как их решить. Читайте далее про сохранение кастомизированных настроек, тонкости работы с базой метаданных и конфигурацию для развертывания...

В конце 2020 года вышел мажорный релиз Apache AirFlow, основные фишки которого мы рассмотрим в этой статье. Читайте далее про 10 главных обновлений Apache AirFlow 2.0, благодаря которым этот DataOps-инструмент для пакетных заданий обработки Big Data стал еще лучше. 10 главных обновлений Apache AirFlow 2.0 Напомним, разработанный в 2014 году...

Чтобы сделать самостоятельное обучение технологиям Big Data по статьям нашего блога еще более интересным, сегодня мы предлагаем вам простой интерактивный тест по основам больших данных, включая администрирование кластеров, инженерию конвейеров и архитектуру, а также Data Science и Machine Learning. Тест по основам больших данных для новичков В продолжение темы,...

Аналитика больших данных напрямую связана с их качеством, которое необходимо отслеживать на каждом этапе непрерывного конвейера их обработки (Pipeline). Сегодня рассмотрим методы и средства обеспечения Data Quality на примере корпорации Airbnb. Читайте далее про лучшие практики повышения качества больших данных от компании-разработчика самого популярного DataOps-инструмента в мире Big Data, Apache...
Продвигая наши курсы по Apache AirFlow для инженеров Big Data, сегодня расскажем, чем этот фреймворк отличается от Luigi – другого достаточно известного инструмента оркестровки ETL-процессов и конвейеров обработки больших данных. В этой статье мы собрали для вас сходства и отличия Apache AirFlow и Luigi, а также их достоинства и недостатки,...
Чтобы максимально приблизить обучение Airflow к практической работе дата-инженера, сегодня мы рассмотрим, какие еще есть альтернативы для оркестрации ETL-процессов и конвейеров обработки больших данных. Читайте далее, что такое Luigi, Argo, MLFlow и KubeFlow, где и как они используются, а также почему Apache Airflow все равно остается лучшим инструментом для оркестрации...

Вчера мы рассматривали проблему управления накладными расходами в сложных конвейерах обработки больших данных на примере использования Apache AirFlow в агрегаторе аренды частного жилья Airbnb. Сегодня разберем, как именно инженеры компании решили проблему роста накладных расходов, отделив бизнес-логику от логики оркестрации в конвейерах Spark-заданий. Читайте далее про принципы проектирования Big Data...
Продолжая разговор про конвейеры обработки больших данных, сегодня рассмотрим пример использования Apache AirFlow в агрегаторе аренды частного жилья Airbnb. Читайте далее, в чем коварство накладных расходов при росте ETL-операций и других data pipeline’ов по запуску и выполнению заданий Spark, Hadoop и прочих технологий Big Data. Еще в этой статье разберем,...

Мы уже рассказывали про основные достоинства и недостатки Apache Airflow, с которыми чаще всего можно столкнуться при практическом использовании этого оркестратора конвейеров обработки больших данных (Big Data). Сегодня рассмотрим некоторые специфические ограничения, характерные для этой open-source платформы и способы решения этих проблем на реальных примерах. Все по плану: 5 особенностей...