
Продвигая наши курсы по Greenplum и Arenadata DB, сегодня рассмотрим, что представляет собой облачная платформа VMware Tanzu Greenplum, где ее можно развернуть и каковы преимущества cloud-решения по сравнению с локальной версией этой MPP-СУБД. Что такое VMware Tanzu Greenplum и чем это отличается от open-source версии Напомним, в 2020 году корпорация...

Продвигая наши курсы по Greenplum и Arenadata DB, сегодня рассмотрим пару полезных лайфхаков, как избежать избыточного потребления памяти, настроив конфигурационные параметры операционной системы хоста. Читайте далее, почему не стоит задавать слишком большой размер страниц виртуальной памяти, зачем администратору контролировать количество spill-файлов и как в этом помогает утилита gp_toolkit. Операционная система...

Недавно мы рассказывали про KafkaJS – клиент Apache Kafka для Node.js, который отличается небольшим размером и простым развертыванием с удобным API. Сегодня рассмотрим еще пару полезных инструментов визуализации данных о Kafka-кластере на базе KafkaJS и Prometheus. Читайте далее, что такое FlowKat и Monokl, а также зачем они нужны дата-инженеру, разработчику...
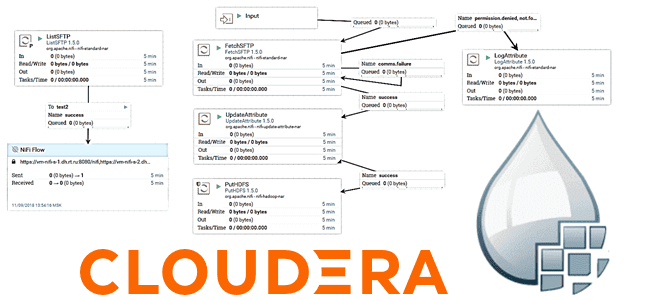
В рамках обучения дата-инженеров сегодня заглянем под капот системы Cloudera Flow Management, которая является частью платформы Cloudera DataFlow и основана на Apache NiFi. Вас ждет разбор основных концепций жизненного цикла потоковой разработки и их реализация в Apache NiFi с практическими примерами и рекомендациями по применению. Что такое Cloudera Flow Management...

Хотя наши практические курсы по Greenplum и Arenadata DB больше ориентированы на аналитиков и дата-инженеров, чем на администраторов, в программы обучения также включены важные сведения по настройке этих MPP-СУБД. В этой статье мы собрали лучшие практики системного конфигурирования кластера Greenplum, которые помогут повысить эффективность аналитики больших данных в этой Big...
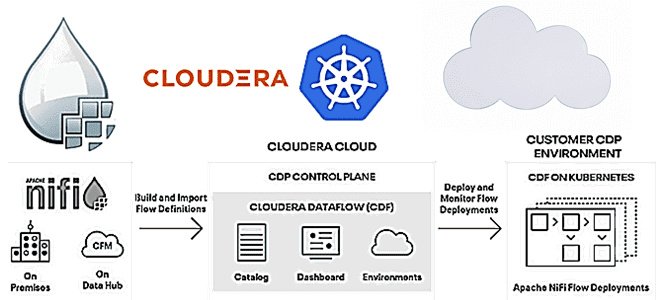
Чтобы сделать наши курсы по Apache NiFi для дата-инженеров еще более полезными, сегодня рассмотрим новые возможности последнего релиза Cloudera Flow Management 2.1.1 на базе этого фреймворка. Выпущенная в апреле 2021 года, платформа Cloudera Flow Management в составе публичного и частного облака предоставляет Apache NiFi версии 1.13.2, включая дополнительные компоненты, а...
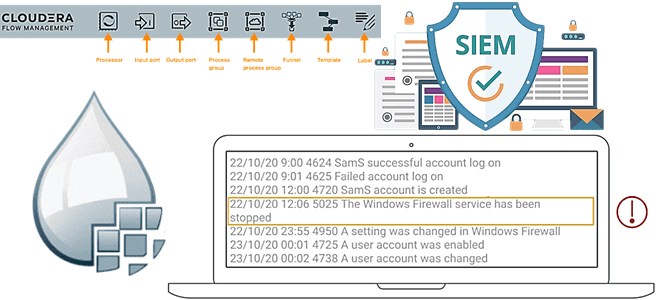
В этой статье для дата-инженеров рассмотрим, что такое Cloudera Flow Management и как это позволяет ускорить аналитику больших данных в кейсах информационной безопасности. Читайте далее о преимуществах SIEM-анализа, преобразования и распределения security-событий с помощью Apache NiFi и его легковесного агента MiNiFi для устройств интернета вещей (Internet Of Things, IoT). Что...
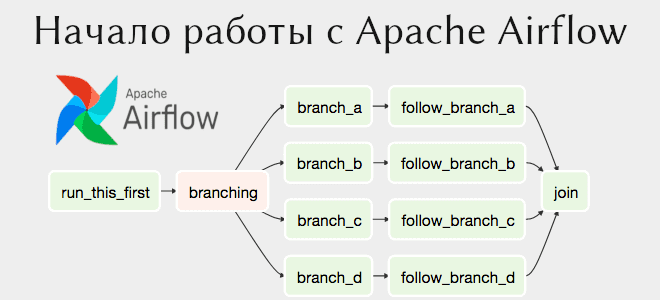
В прошлой статье мы рассмотрели установку Apache Airflow на свой компьютер. Данная платформа предназначена для планирования задач, например, выполнения скриптов Bash и Python в заданное время, в заданной последовательности. Сегодня на примере выполнения двух Bash-команд расскажем, как создать свой первый граф. Читайте в этой статье: связи между задачами, создание графа...

Apache Airflow имеет множество зависимостей, поэтому установка может быть проблематичной. В отличие от 1-й версии, Airflow 2 устанавливается гораздо проще. В этой статье разберем установку Apache Airflow через пакетный менеджер pip и через Docker. Локальная установка Apache Airflow Apache Airflow был протестирован на: Python: 3.6, 3.7, 3.8, 3.9 СУБД (Система...
В рамках программы курсов по Greenplum и Arenadata DB, сегодня рассмотрим важную для разработчиков и администраторов тему об особенностях оптимизатора SQL-запросов GPORCA, который ускоряет аналитику больших данных лучше встроенного PostgreSQL-планировщика. Читайте далее, как выбирать ключ дистрибуции, почему для GPORCA важна унифицированная структура многоуровневой партиционированной таблицы и каким образом оптимизаторы обрабатывают...

YARN считается самым распространенным диспетчером ресурсов в кластерах Apache Hadoop и Spark, отвечая за выделение ресурсам распределенным приложениям. Сегодня в рамках обучения дата-инженеров и администраторов Hadoop рассмотрим достоинства и недостатки 3-х вариантов планирования ресурсов в YARN. Читайте далее, что такое иерархия очереди и как вычисляется ее мгновенная справедливая доля. Планирование...

Apache Storm обычно сравнивают со другими популярными фреймворками потоковой аналитики больших данных: Spark и Flink. Однако для несложной обработки событий дата-инженер может заменить эти платформы более легким инструментом маршрутизации потоковых данных в виде Apache NiFi. Сегодня сравним Apache NiFi co Storm и разберем практический пример, когда предпочтительнее именно его для...
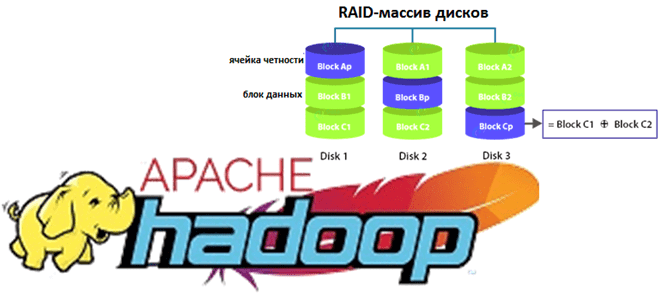
Недавно мы рассказывали про новые функции свежего релиза Apache Hadoop 3.3.1. Сегодня разберем подробнее, что такое Erasure Coding и как эта технология кодирования со стиранием экономит место в распределенной файловой системе HDFS. Также заглянем внутрь EC и рассмотрим, чем алгоритм Рида-Соломона лучше ассоциативной операции XOR для обеспечения отказоустойчивости хранилища больших...
Чтобы добавить в курсы по Apache AirFlow еще больше полезных примеров, сегодня рассмотрим, как избежать дублирования кода при загрузке данных. Этот пример пригодится дата-инженерам в работе с ELT-процессами наполнения информацией корпоративных хранилищ и озер данных. Читайте про фреймворк динамической загрузки данных на базе конфигурационных YAML-файлов, DAG-фабрик и загрузчиков. Проблема дублирования...

Поскольку Greenplum и Arenadata DB основаны на популярной open-source СУБД PostgreSQL, сегодня разберем, чем они отличаются от этой объектно-реляционной базы данных. Далее вас ждет краткий и понятный ответ на вопрос Greenplum vs PostgreSQL: сходства и отличия этих систем с учетом аналитики больших данных и практических кейсов дата-инженерии. Что общего между...

В этой статье в поддержку курсов по Apache NiFi заглянем под капот этой платформы маршрутизации потоковых данных и рассмотрим, как дата-инженер может создать собственный процессор. Смотрите далее, как устроены процессоры в Apache NiFi, что общего между отношениями и маршрутами движения потоковых данных, как создать FlowFile, зачем нужен метод onTrigger() и...
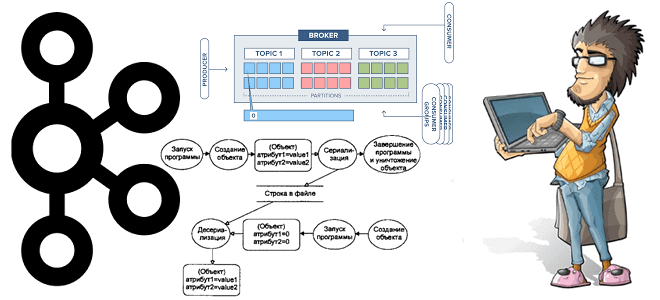
В рамках курсов по Apache Kafka для разработчиков и администраторов кластера, сегодня заглянем под капот AdminClient и на практических примерах разберем, как динамически создавать новый топик и описывать его программным способом через API. Еще рассмотрим, почему метод deleteTopics() нужно применять очень осторожно, а также вспомним основы ООП, говоря про классы...

Обучая разработчиков и администраторов Greenplum, а также в рамках продвижения курсов по Arenadata DB, сегодня рассмотрим, как SQL-оптимизатор ORCA ускоряет аналитику больших данных, позволяя реализовать многостороннее соединение таблиц через JOIN-запросы. Читайте далее, что такое GPORCA, как его использовать, насколько он эффективен по сравнению с другими планировщиками SQL-запросов в этой MPP-СУБД...

Мы уже писали про преимущества разделения пакетов в Apache AirFlow 2.0. Сегодня рассмотрим, как открытый реестр Python-пакетов от компании Astronomer облегчает разработку конвейеров обработки данных, чем провайдеры отличаются от модулей и насколько удобно дата-инженеру всем этим пользоваться. От монолита к мульти-пакетной архитектуре в Apache Airflow 2.0 Напомним, во 2-ой версии...

Постоянно обновляя наши курсы по Apache Hadoop для администраторов кластеров и инженеров данных, сегодня рассмотрим главные новинки июньского релиза 2021. Читайте далее, как поддержка Erasure Coding сэкономит место в HDFS, зачем обновляться до 8-ой версии Java, чем хорош YARN Timeline Service v.2, как повысить надежность кластера Hadoop еще больше и...