
В продолжение недавней статьи для дата-инженеров по эффективной работе с Apache AirFlow, сегодня разберем еще несколько рекомендаций от компании Astronomer, которая продвигает и коммерциализирует этот ETL-оркестратор. Чем полезна микрооркестрация с несколькими средами AirFlow, как обеспечить повторное использование и воспроизводимость, зачем нужна интеграция с инструментами и процессами CI/CD. Микрооркестрация с множеством...
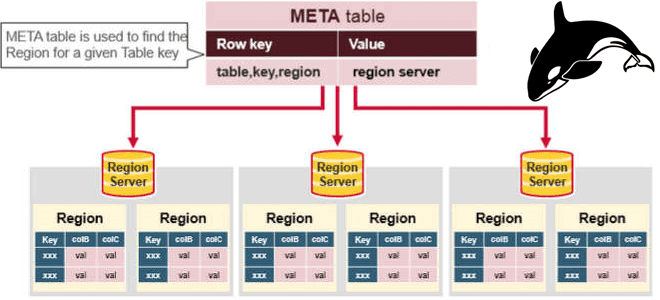
Сегодня затронем тему администрирования кластеров Apache HBase и рассмотрим, приносит ли реальную пользу совместное размещение нескольких региональных серверов (RegionServer) на одном узле кластера. Сравнительный анализ по тестам YCSB-бенчмарка. Регионы и сервера Apache HBase Напомним, Apache HBase является популярной колоночной NoSQL-СУБД, которая работает поверх распределенной файловой системы HDFS и обеспечивает возможности...
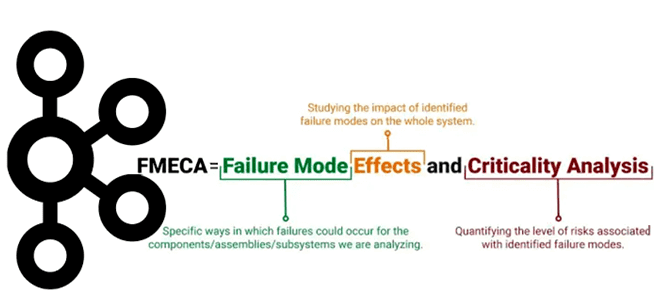
Хотя Apache Kafka является надежной платформой потоковой обработки событий, что особенно важно для распределенных приложений, отказы случаются и в ней. Сегодня разберем важную для обучения разработчиков и дата-инженеров тему про идентификацию и обработку отказов в Kafka-приложениях с помощью простого, но эффективного метода теории надежности. Что такое FMECA-анализ, как его проводить...

Как настроить Apache Spark 3.0.1 и Hive 3.1.2 на Hadoop 3.3.0: тонкости установки и конфигурирования для обучения администраторов кластера и инженеров с примерами команд и кода распределенных приложений. Запуск Spark-приложения на Hadoop-кластере Прежде всего, для настройки кластера Apache Spark нужен работающий кластер Hadoop. Сама установка и настройка выполняется в 2...

Сегодня рассмотрим несколько рекомендаций по построению масштабной и устойчивой экосистемы интеграции корпоративных данных на базе Apache AirFlow от компании Astronomer, которая активно способствует продвижению и коммерциализации этого популярного инструмента дата-инженерии. Как организовать эффективную маршрутизацию рабочих процессов с пакетным ETL-оркестратором: 3 лучших практики. Стандартизация сред разработки и промышленной эксплуатации с Kubernetes...

Почему следует избегать PythonOperator в конвейере обработки пакетных данных на Apache Airflow и что использовать вместо этого оператора для описания задач DAG. Когда лаконичный CLI лучше наглядного GUI, где и как применять библиотеку Python Fire для оркестрации, а также планирования запуска batch-заданий. Зачем нам CLI или что не так с PythonOperator...

Запуск Apache Airflow с Kubernetes сегодня стал стандартом де-факто. Однако, при практическом развертывании Airflow с помощью исполнителя Kubernetes и оператора пода в кластере этой платформы оркестрации контейнерных приложений возникает множество препятствий и трудностей. Сегодня рассмотрим, как обойти их с помощью service-mesh проекта с открытым исходным кодом Istio, какие проблемы могут при...

Сообщество разработчиков Apache NiFi регулярно радует новыми выпусками. Не успели мы полностью освоить январский релиз 2022, в начале марта появилась еще более свежая версия этого потокового маршрутизатора. Самое главное в Apache NiFi 1.16.0 для дата-инженера и администратора кластера. Главные новинки Apache NiFi 1.16.0 Apache NiFi 1.16.0 включает несколько десятков улучшений,...

Как организовать удобный мониторинг за приложениями Apache Spark в кластере Kubernetes с помощью Prometheus и Grafana: пошаговый guide для администраторов и дата-инженеров с примерами. Создаем свою альтернативу наглядным дэшбордам AWS EMR с Java-библиотекой Dropwizard Metrics и средством настройки оповещений Alertmanager. Не только AWS EMR или как следить за Spark-приложениями в...

В октябре прошлого года вышел крупный релиз Apache AirFlow 2.2.0. Разбираем его главные фичи, которые больше всего интересны с точки зрения инженерии данных: пользовательские расписания и декораторы, отложенные задачи, а также валидация параметров DAG по JSON-схеме. Краткий обзор обновлений AirFlow 2.2.0 Хотя последней версией популярного batch-планировщика задач Apache Airflow на...

Недавно мы писали про декабрьский релиз Apache NiFi. Спустя месяц, 18 января 2022 года сообщество выпустило новую версию фреймворка – 1.15.3 с аутентифицированным доступом к SFTP-серверам через прокси-серверы SOCKS и улучшенным потреблением памяти. Разбираем 9 исправленных багов и 2 улучшения, а также особенности миграции на свежий выпуск. Снова про библиотеки...

Развивая наши курсы по Apache Spark и AirFlow для дата-инженеров и администраторов кластеров, сегодня рассмотрим кейс крупного маркетплейса Joom по переходу от 2-ой версии фреймворка на облачной платформе EMR к развертыванию сотен распределенных заданий на 3-ей версии в Amazon Elastic Kubernetes Service. Про сокращение расходов, повышение производительности и апдейт вычислительных движков. Постановка...
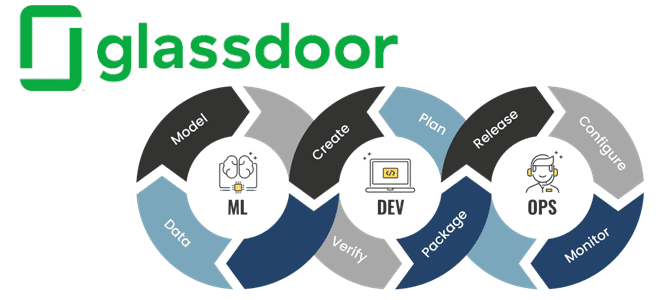
Практическая реализация MLOps-концепции на примере международной рекрутинговой компании Glassdoor. Как построить самоуправляемую автоматизированную систему разработки и сопровождения ML-моделей с MLFlow, Apache Spark и AirFlow, Kubernetes, GitLab, SageMaker Feature Store, Whylogs, Jenkins, Spinnaker и Prometheus с Grafana. Предыстория: зачем MLOps в Glassdoor Glassdoor с 2008 года помогает соискателям по всему миру...

В этой статье для дата-инженеров и администраторов кластеров разберем, как автоматически масштабировать поды Kubernetes с Apache AirFlow в зависимости от метрик рабочей нагрузки из внешней платформы Datadog с помощью демона StatsD, а также ресурса и контроллера HorizontalPodAutoscaler. Автоматическое горизонтальное масштабирование в Kubernetes Одна из сильных сторон Kubernetes заключается в его...

Сегодня рассмотрим пару важных тем для администратора Greenplum: требования к программно-аппаратному окружению, а также особенности установки и настройки этой MPP-СУБД. Еще разберем, как Arenadata Cluster Manager облегчает и автоматизирует эти процессы в Arenadata DB. Программное окружение Greenplum: операционные системы и Java Greenplum 6 работает на следующих платформах операционных систем: Red...

В этой статье для разработчиков Data Flow, инженеров данных и администраторов Apache AirFlow рассмотрим, как организовать мониторинг этого batch-оркестратора через популярный корпоративный мессенджер Slack. Хотя по умолчанию Airflow имеет встроенную возможность отправлять оповещения по электронной почте, это не самый оперативный способ сообщить о критичной проблеме, к примеру, когда DAG с...
В статье для дата-инженеров и администраторов Apache Hadoop разберем, как реализовать инкрементное резервное копирование таблиц HBase из кластеров CDH/CDP в облачное объектное хранилище AWS S3. Практический пример от международной ИТ-компании Clairvoyant. 5 способов резервного копирования в Apache HBase Apache HBase - это популярная колоночная NoSQL-СУБД, которая работает поверх распределенной файловой...
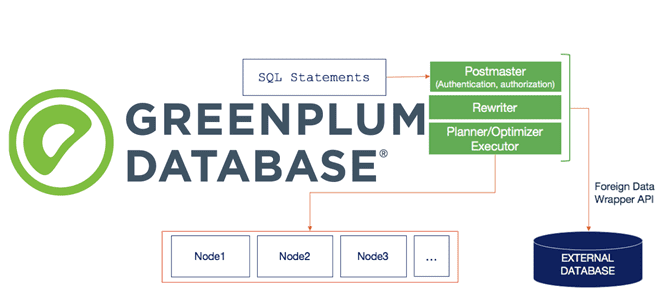
Сегодня продолжим разбираться с интеграционным фреймворком Greenplum и рассмотрим, как PXF реализует SQL-запросы к различным OLAP и OLTP-источникам, поддерживая разные форматы данных. Зачем создавать внешнюю таблицу для Greenplum и какие параметры при этом указывать, а также чем хороша технология оптимизации pushdown. SQL и PXF: интеграция Greenplum с внешними источниками на...
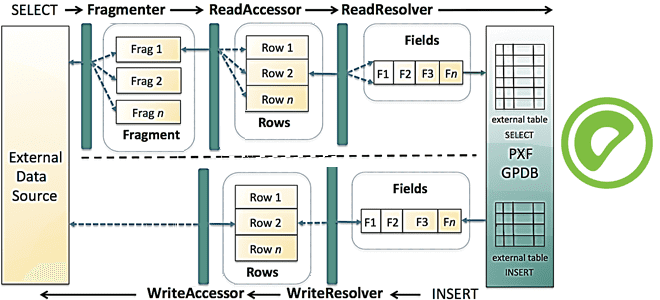
Специально для дата-инженеров, разработчиков OLAP-конвейеров и архитекторов DWH на MPP-СУБД Greenplum и Arenadata DB сегодня рассмотрим, что представляет собой PXF, из каких компонентов он состоит и как они взаимодействуют друг с другом, чтобы обеспечить параллельный высокопроизводительный доступ к данным и объединенную обработку запросов к разнородным источникам. Что PXF и зачем...

Постоянно обновляя наши курсы по Apache Kafka, сегодня рассмотрим еще один полезный инструмент для администраторов, дата-инженеров и разработчиков, который повышает эффективность взаимодействия с этой распределенной платформой потоковой обработки событий. Что такое Saamsa, какие проблемы Kafka она решает и как ее использовать на практике. 5 вопросов разработчика и дата-инженера к Apache...