
1 августа 2022 года вышел очередной выпуск самого популярного потокового ETL-маршрутизатора. Что нового в Apache NiFi 1.17 для дата-инженера и администратора кластера: новые фичи, исправления ошибок и главные улучшения. Главные новинки Apache NiFi 1.17 Свежий выпуск Apache NiFi 1.17.0 включает сотни исправлений ошибок, улучшений и обновлений зависимостей для повышения стабильности...

В этой статье для обучения дата-инженеров и администраторов кластера Apache NiFi разберем лучшие практики настройки этого популярного маршрутизатора потоковых данных. Какие настройки задать в операционной системе Linux и что исправить в конфигурациях самого Apache NiFi, чтобы ускорить обработку потоковых данных. Что настроить в Linux: 6 конфигураций Как и большинство серверных...

В рамках обучения дата-инженеров сегодня рассмотрим пример отправки данных в платформу сбора и анализа системных логов Splunk с помощью Apache NiFi. Как работает процессор PutSplunkHTTP, когда вместо него стоит выбрать InvokeHTTP, что такое HEC-токен и какие HTTP-методы REST API обеспечивают интеграцию Splunk с Apache NiFi. Что такое Splunk и как...
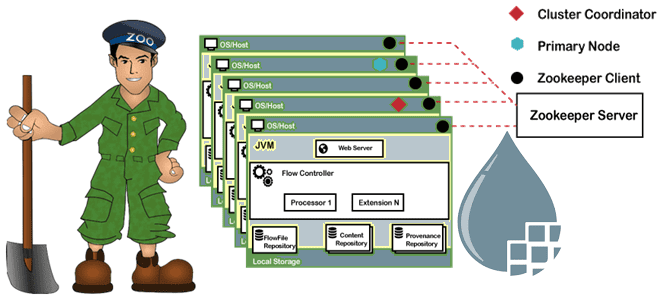
Сегодня рассмотрим важную для обучения администраторов кластера Apache NiFi тему по установке и настройке этого потокового ETL-фреймворка с использованием встроенного сервиса координации и синхронизации метаданных в распределенных системах Zookeeper. А также рассмотрим, как процесс выбора лидера в кластере Zookeeper позволяет серверам избежать аномальных всплесков трафика от клиентов и роста нагрузки....

Как Cluster Autotuner от Sync для автонастройки кластера Spark в AWS EMR помог edtech-компании Duolingo снизить затраты на 55%. Полезный сервис для дата-инженера и администратора кластера, чтобы устранить неэффективную ручную настройку, обеспечив оптимальную стоимость, производительность и надежность распределенных вычислений без изменения кода. Дорогой Apache Spark на AWS EMR Duolingo –...
Недавно мы писали про проблемы приложений Apache Flink в кластере Kubernetes. Сегодня рассмотрим, каким образом можно развернуть и запустить задания этого фреймворка распределенной обработки данных на самой популярной DevOps-платформе контейнерной виртуализации. Обзор операторов от Lyft, Google Cloud Platform, нативного расширения и возможностей платформы Ververica. Зачем и как выполнить развертывание Apache...

Сегодня рассмотрим, с какими нетиповыми ошибками может столкнуться дата-инженер при работе с Apache Flink, а также как решить эти проблемы. Где и что править, когда сервер BLOB-объектов завис из-за слишком большого количества подключений, почему не хватает памяти при развертывании Flink-приложений в кластере Kubernetes и как ускорить инициализацию заданий. Особенности работы...
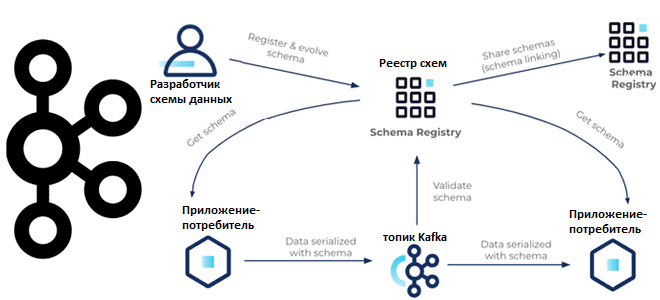
С какими проблемами качества данных сталкивается дата-инженер при работе с Apache Kafka и как реестр схем поможет их решить. Чем формат сериализации Apache AVRO отличается от JSON и Protobuf, как использовать Schema Registry и обеспечить совместимость данных: краткое пошаговое руководство для дата-инженера. Качество данных и реестр схем Apache Kafka Низкое...

В этой статье для обучения дата-инженеров и архитекторов распределенных систем рассмотрим, что такое наблюдаемость, как ее измерить и при чем здесь стандарт OpenTelemetry. А в качестве примера разберем, как французский маркетплейс Cdiscount управляет почти 1000 микросервисов в кластере Kubernetes с Apache Kafka, Jaeger, Elasticsearch и OpenTelemetry. Наблюдаемость распределенной системы: стандарт...
Мы уже рассматривали важность мониторинга приложений Apache Flink и говорили про метрики отслеживания задержки обработки данных в потоковых заданиях. Сегодня заглянем под капот этого фреймворка и разберем, какие показатели работы JVM, а также RocksDB особенно важны для дата-инженера и разработчика распределенных приложений. Метрики JVM во Flink-приложениях Напомним, основным языком разработки...
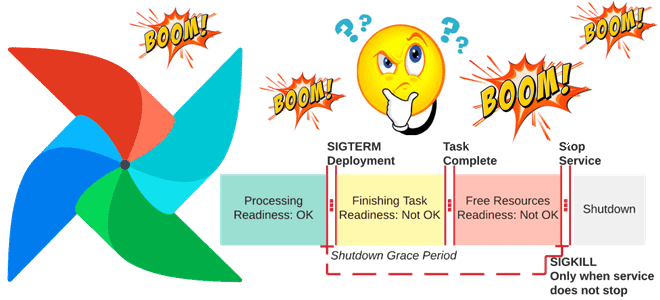
Каждый дата-инженер, который работает с Apache Airflow, сталкивался с сигналом SIGTERM, который отправляется задачам и приводит к сбою DAG. Сегодня рассмотрим, почему случается исключение airflow.exceptions.AirflowException, которое генерирует этот сигнал, и как его избежать. Тайм-аут выполнения DAG Одна из причин, по которой задача получает сигнал SIGTERM, связана с небольшим значением параметра...
Специально для обучения разработчиков распределенных приложений и дата-инженеров масштабных платформ аналитики больших данных на Apache Flink, рассмотрим наиболее важные системные показатели, а также инструменты мониторинга этих метрик. Мониторинг Flink-приложений: особенности и метрики В общем случае мониторинг приложений гарантирует, что ПО обрабатывает данные и выполняет запрошенные действия ожидаемым образом. Непрерывное отслеживание...

В свежем релизе Apache Kafka 3.2.0, который вышел 17 мая 2022 года, о чем мы писали здесь, есть много интересных улучшений для повышения устойчивости потоковых приложений. Почему важна новая фича назначения резервных задач с учетом стоек и как разработчик с дата-инженером могут использовать в помощь администратору кластера: разбор rack awareness...
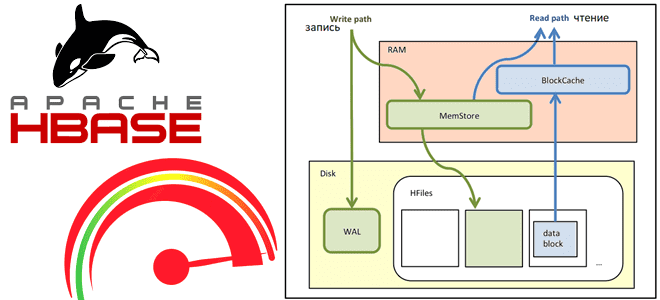
Сегодня рассмотрим, как выполняются операции чтения и записи в Apache HBase, а также с помощью каких приемов можно их ускорить. Как рассчитать оптимальное количество регионов в таблице, зачем отключать версионирование, почему размер ключа строки должен быть небольшим и еще 7 полезных лайфхаков для администратора HBase-кластера. Оптимизация записи данных в Apache...

Недавно мы писали про Apache AirFlow 2.3.0 от 30 апреля 2022 года. Сегодня более подробно разберем одну из главных новинок этого релиза – динамическое сопоставление задач. Что это такое, как работает и зачем нужно дата-инженеру. Что такое динамическое сопоставление задач в ETL-конвейере Напомним, динамическое сопоставление задач (Dynamic Task Mapping) считается...

17 мая 2022 года вышел очередной релиз главной платформы потоковой передачи событий. Смотрим самые важные обновления свежей Apache Kafka 3.2.0 с точки зрения разработчика распределенных приложений, дата-инженера и администратора кластера. ТОП-5 новинок свежей версии Apache Kafka для администратора кластера Apache Kafka 3.2.0 включает 2 новые фичи, 36 улучшений и 65...

В этой статье для обучения дата-инженеров и администраторов кластера Apache HBase разберем, почему региональные сервера могут работать некорректно при высокой нагрузке и при чем здесь SCR-конфигурация файловой системы Hadoop. Что такое Short-Circuit Read в HDFS и почему оно может снижать скорость потокового чтения в приложениях Spark Streaming. Постановка задачи: проблема...

30 апреля 2022 года вышел новый релиз Apache Airflow, который содержит более 700 коммитов с предыдущей версии 2.2.0 и включает 50 новых функций, 99 улучшений, 85 исправлений ошибок и несколько изменений в документации. Разбираемся, что особенно важно для дата-инженера в Apache Airflow 2.3.0. ТОП-7 главных фич Apache AirFlow 2.3.0: краткий...
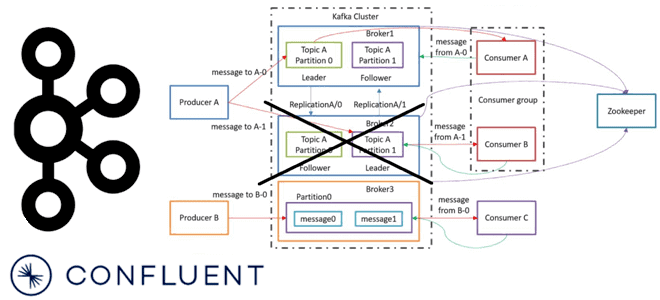
Сегодня рассмотрим важную для обучения администраторов кластера Apache Kafka тему про удаление брокеров. Что происходит, когда администратор удаляет брокер Kafka из кластера, какие сложности при этом могут возникнуть и как с ними справляется решение на базе платформы Confluent. Как вручную удалить брокер Kafka из кластера: краткий guide администратора На первый...
Интеграция Apache Airflow с инструментами CI/CD является одной из лучших практик современной дата-инженерии, о чем мы недавно писали. Читайте далее, зачем нужно управлять кодом DAG с помощью популярных систем управления версиями и как это сделать на примере GitLab CI/CD. Сложности управления DAG в разных средах AirFlow Apache Airflow считается наиболее...