
Продолжая разбираться с новинками Greenplum версии 7, выпущенной в середине декабря 2022 года, сегодня рассмотрим, как теперь работает SQL-команда с DML-запросов изменения таблиц ALTER TABLE. Как динамически менять структуру и характеристики таблицы даже тех, что предназначены только для добавления с новыми методами доступа. Модели таблиц в Greenplum: Append Only и...
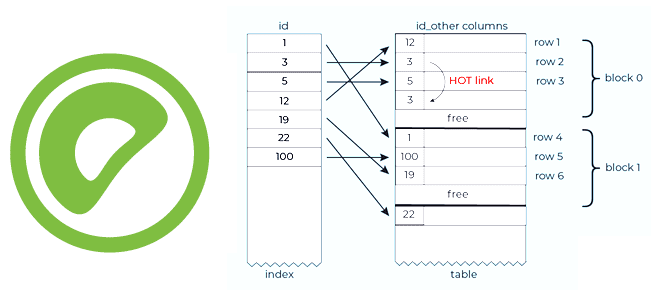
Чтобы сделать наши курсы по Greenplum еще более полезными, сегодня разберем особенности индексов и накладываемых ими ограничений на SQL-запросы к таблицам этой MPP-СУБД. Что такое уникальные индексы и как они поддерживаются в таблицах, оптимизированных для добавления, в Greenplum версии 7, выпущенной в середине декабря 2022 года. Еще раз о пользе...

Учитывая рост интереса к DevOps-инструментам, сегодня рассмотрим, зачем переводить кластер Apache Spark, управляемый YARN, в Kubernetes, и как это сделать наиболее эффективно. А также разберем, какие системные метрики контейнерных Spark-приложений надо отслеживать и с помощью каких средств. Зачем переводить кластер Apache Spark от YARN на Kubernetes Apache Spark не зря...
Чтобы сделать наши курсы по Apache Kafka еще более полезными, сегодня рассмотрим, какие интерфейсы и протоколы для связи клиента с брокером использует эта платформа потоковой передачи событий. А также рассмотрим, что обеспечивает двунаправленную совместимость API. Протоколы и интерфейсы Apache Kafka для общения клиентов с брокерами Apache Kafka использует бинарный протокол...
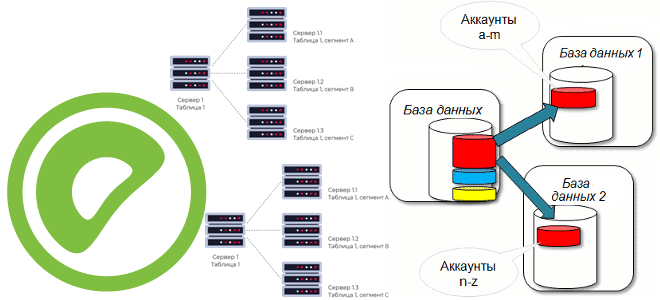
В этой статье для дата-инженеров и ИТ-архитекторов поговорим про шардирование баз данных и разберем, как этот способ горизонтального масштабирования системы реализуется в MPP-СУБД Greenplum, при чем здесь ключ дистрибуции и как его задать. Что такое шардирование БД и как оно работает Чтобы повысить производительность приложения через увеличение пропускной способности СУБД...

Недавно мы писали про чтение данных из AWS S3 с помощью PySpark-задний. Продолжая разбираться, как перейти от HDFS к облачным объектным хранилищам, сегодня рассмотрим пример чтения и записи файлов из Google Cloud Storage с помощью Apache Spark. От HDFS к GCS Распределенная файловая система Apache Hadoop (HDFS) уже много лет...

В этой статье для обучения дата-инженеров и администраторов кластера Apache NiFi познакомимся с NiFiKop – оператором, который упрощает запуск потокового ETL-маршрутизатора на платформе контейнерной виртуализации Kubernetes. 4 трудности управления кластером Apache NiFi При том, что Apache NiFI имеет множество достоинств, предоставляя возможности сбора, маршрутизации и обогащения потоков данных из разных...

Недавно мы писали про новинки сентябрьского и октябрьского релизов Greenplum 6.22, а 18 ноября 2022 года вышла новая отладочная версия, которая решает некоторые проблемы с сервером СУБД, обработкой запросов и потоком данных. Разбираемся, что стало лучше в VMware Tanzu Greenplum 6.22.2 с точки зрения администратора кластера и дата-инженера. Новинки и...

Визуализация конвейеров обработки данных особенно важна в потоковой парадигме, поэтому мы часто рассматриваем полезные средства мониторинга для Apache Kafka. Сегодня разберем, что такое Streams Explorer от Bakdata и как это пригодится для дата-инженера. Проекты Bakdata для развертывания и мониторинга приложений Kafka Streams При работе с крупномасштабными потоковыми данными крайне важно...

В этой статье для обучения дата-инженеров и администраторов кластера Apache Kafka разберем, какие ошибки создают медленные потребители и как решить их, просто изменив значений конфигураций по умолчанию. А также познакомимся с Lighthouse - еще одним полезным инструментом мониторинга системных метрик, который позволит обнаружить эти и другие проблемы. Проблема медленных потребителей...
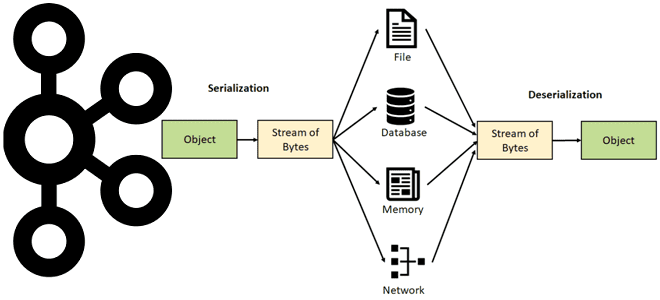
Недавно мы писали про сериализацию и десериализацию данных в Apache Kafka. Продолжая эту важную для обучения дата-инженеров и разработчиков распределенных приложений тему, рассмотрим особенности преобразования и валидации сообщений в JSON-формате, а также поговорим про автоматическую идентификацию формата сообщения. Сериализация и десериализация данных в Apache Kafka Выполняя роль интеграционной платформы, Apache...
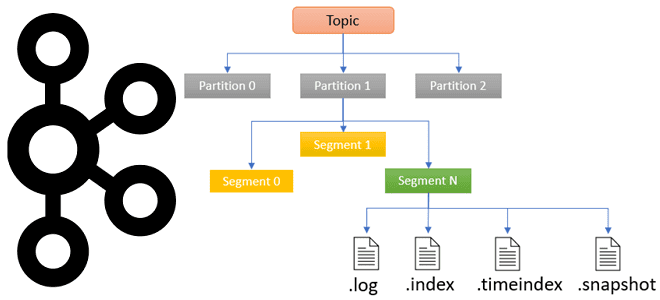
Чтобы сделать наши практические курсы по Apache Kafka еще более полезными, сегодня рассмотрим, в каких файлах хранятся сообщения, смещения и состояния продюсера, а также функции работы с ними для потоковой передачи событий. Средства обработки и хранения данных в Apache Kafka Прежде, чем погружаться в тонкости хранения данных в Apache Kafka,...

В этой статье для обучения дата-инженеров и администраторов кластера Apache AirFlow рассмотрим, как обновить этот ETL-планировщик, используя концепцию сине-зеленого развертывания. Также рассмотрим, с какими ошибками можно столкнуться, выполняя миграцию базы данных метаданных и как их решить. Сине-зеленое развертывание для обновления AirFlow Как и любое программное обеспечение, Apache AirFlow нужно периодически...

Как турецкая e-commerce компания Trendyol повысила эффективность пакетных вычислений, используя распределенную платформу потоковой обработки событий Apache Kafka вместе с серверной утилитой сбора и фильтрации данных из разных источников Logstash. Пакетная обработка данных и конвейер на Logstash Хотя сегодня все больше организаций переходят на потоковую обработку событий в реальном времени, пакетная...

Чтобы добавить в наши курсы для администраторов кластера Apache Kafka и разработчиков распределенных приложений еще больше полезных обучающих материалов, сегодня рассмотрим новый инструмент мониторинга системных метрик этой платформы потоковой передачи событий. Что такое проект Iris и чем он отличается от других популярных средств мониторинга состояния Apache Kafka, о которых мы...

8 августа 2022 года вышел очередной релиз главной технологии стека Big Data – Apache Hadoop 3.3.4. Разбираемся с ключевыми фичами этого выпуска и исправлениями ошибок, которые особенно важны для администратора кластера и дата-инженера. ТОП-10 обновлений Apache Hadoop 3.3.4 Apache Hadoop 3.3.4 включает в себя ряд значительных улучшений по сравнению с...
Недавно мы рассказывали, как организовать аутентификацию пользователей Apache NiFi через Okta OIDC в качестве сервиса провайдера удостоверений. Продолжая эту важную для обучения администраторов кластера и дата-инженеров тему, сегодня рассмотрим, как использовать SaaS-решение IBM Security Verify для управления доступом к пользовательскому интерфейсу Apache NiFi. Разбираемся с OpenID Connect для входа и...

Для практического обучения дата-инженеров и архитекторов Big Data систем сегодня рассмотрим трудности изоляции и распределения в кластере Apache HBase и способы их обхода. С какими проблемами изоляции и сбалансированного распространения данных столкнулись инженеры индийской e-commerce компании Flipkart при организации мультиарендного кластера Apache HBase и как их решили. Изоляция данных и...
В этой статье для обучения дата-инженеров и администраторов кластера разберем способы организации совместного использования DAG-файлов при развертывании Apache AirFlow в Kubernetes. Чем хорош вариант с общими томами и почему от него лучше отказаться в пользу Git. Как организовать обмен DAG-файлами в Apache AirFlow на Kubernetes Развертывание Apache AirFlow в кластере...

Мы часто делимся полезными лайфхаками и лучшими практиками администрирования и эксплуатации технологий Big Data. Сегодня специально для обучения дата-инженеров рассмотрим, как лучше настроить репозитории Apache NiFi и параметры кластера, чтобы повысить производительность и надежность этого популярного ETL-маршрутизатора потока данных. 4 репозитория Apache NiFi Репозиторий потоковых файлов содержит информацию обо всех...