
Чтобы сделать наши курсы по Apache NiFi Для дата-инженеров еще более полезными, сегодня поговорим про настройку процессоров. Читайте далее, как распараллелить задачи и потоки, задержать FlowFile, задать обратное давление и настроить другие полезные конфигурации. Как настроить конфигурации процессора Apache NiFi Будучи мощным инструментом дата-инженерии, Apache NiFi содержит множество обработчиков –...
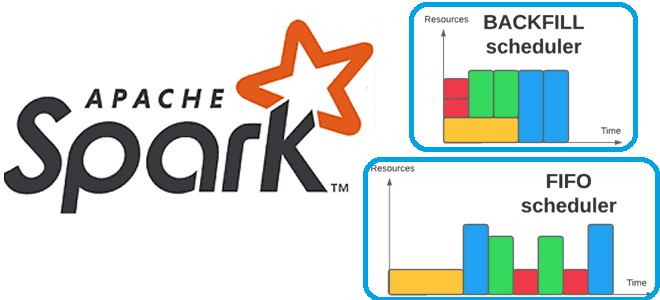
Что такое backfill-операции в конвейерах заданий Apache Spark, чем они отличаются от исторического заполнения датасетов, зачем их автоматизировать и как это сделать. Что такое backfilling для заданий Apache Spark Мы уже писали про понятие backfill на примере модификации DAG при добавлении новых заданий в конвейер Apache AirFlow. Эта функция полезна,...
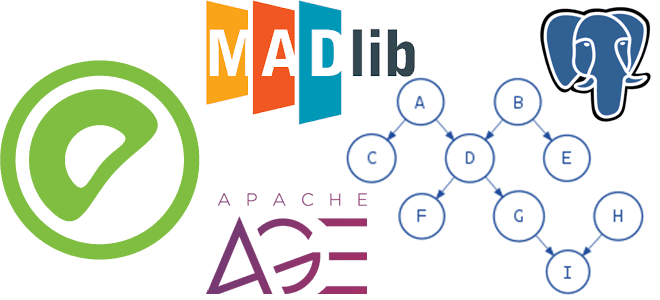
Инструменты графовых алгоритмов для аналитики больших данных в PostgreSQL и Greenplum: обзор расширений и возможностей. Знакомимся с Apache AGE и MADlib. Графовая аналитика в PostgreSQL Реляционные СУБД отлично подходят для хранения данных с четкой структурой практически в любой предметной области и предлагают широкие возможности аналитической обработки таких данных. Но иногда реляционная...

Мы уже писали, как можно развернуть контейнерные приложения Apache Flink для обработки больших объемов данных в реальном времени. В продолжение этой темы сегодня сравним развертывание Flink-заданий в Kubernetes и в кластере AWS EMR. Flink-приложение в Kubernetes: преимущества и недостатки Apache Flink — это мощный фреймворк с открытым исходным кодом для...
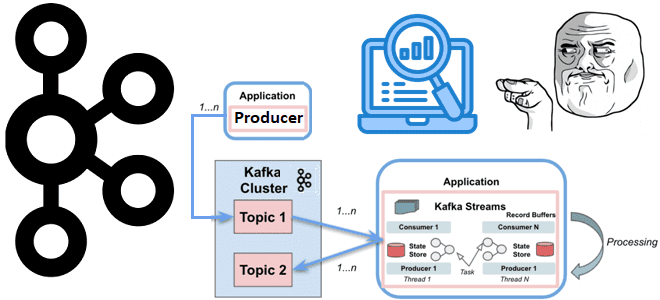
Как использовать один и тот же топик Kafka для источника и назначения данных, обеспечивая высокую пропускную способность и низкую задержку приложений Kafka Streams. А также рассмотрим, какие встроенные метрики приложений есть у Kafka Streams, как добавить свои собственные и с помощью каких инструментов их отслеживать в реальном времени. Топики и...

Сегодня познакомимся с расширением PostGIS, которое позволяет PostgreSQL и Greenplum обрабатывать пространственные данные в геолокационных и логистических задачах. Как оно устроено и каковы ограничения его практического использования в MPP-СУБД. Что такое PostGIS и как это работает Как и PostgreSQL, Greenplum поддерживает геометрические типы данных, с помощью которых можно строить статичные...

Чтобы сделать наши курсы для дата-инженеров и разработчиков распределенных приложений еще более полезными, сегодня мы расскажем про новый бесплатный сервис от маркетплейса Joom для поиска проблем с производительностью Spark-заданий. Разбираемся, как он работает и чем полезен дата-инженеру. 4 главных проблемы Spark-приложений, их последствия и трудности обнаружения Если количество Spark-приложений невелико,...
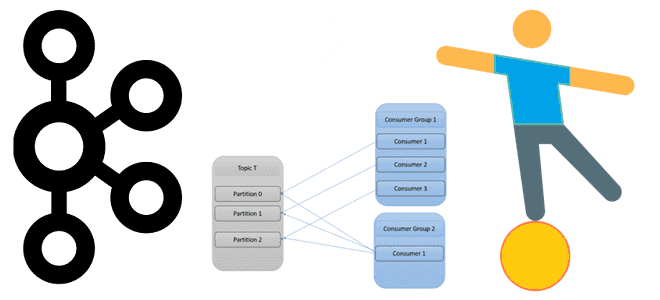
Для параллельной обработки сообщений из своих топиков Kafka использует механизм группы приложений-потребителей, о чем мы писали здесь. Читайте далее, что происходит при изменении состава группы потребителей, чем опасна частая перебалансировка и как ее избежать. Что такое перебалансировка потребителей и почему она случается? Выполняя роль интеграционного звена между приложениями-продюсерами и приложениями-потребителями...
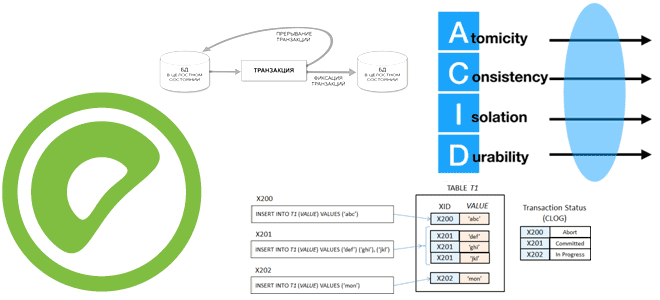
Недавно мы писали про трудности реализации ACID-требований к транзакциям в распределенных базах данных и способах их решения. Сегодня рассмотрим, как это работает в Greenplum с Arenadata DB: уровни изоляции, идентификаторы транзакций, моментальные снимки и MVCC-модель управления параллелизмом. Как GP и Arenadata DB реализуют распределенные транзакции Будучи основанной на PostgreSQL, Greenplum...
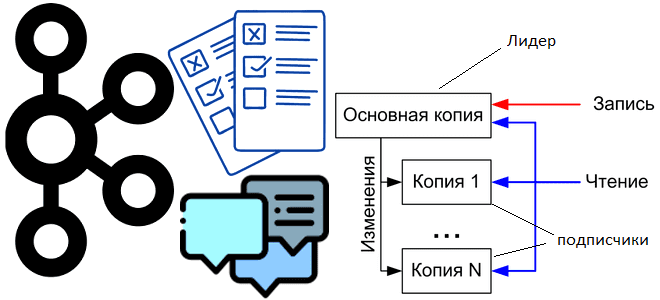
Сегодня рассмотрим, как внутренние механизмы Apache Kafka обеспечивают отказоустойчивость это потоковой платформы передачи событий, а также разберем, почему до сих пор приходится выбирать между доступностью и надежностью. Выборы нового лидера при сбое прежнего и ожидание подтверждений об успешной репликации. Поиск компромисса между надежностью и доступностью в Apache Kafka Для обеспечения...

Сегодня в рамках обучения администраторов SQL-on-Hadoop рассмотрим, как защитить данные в кластере Apache HBase от несанкционированного доступа. Аутентификация и авторизация пользователей, операторы управления доступом к таблицам, метки видимости и шифрование данных. Механизмы защиты данных в Apache HBase Как и любое хранилище, колоночно-ориентированная мультиверсионная NoSQL-СУБД типа key-value Apache HBase, которая работает...
Какие подходы позволяют увеличить емкость СУБД, чтобы повысить объем хранящихся в ней данных и ускорить вычисления. Разбираем тонкости масштабирования распределенной базы данных с массово-параллельной обработкой Greenplum: действия администратора по добавлению новых узлов в кластер. Как увеличить емкость базы данных: 4 подхода к масштабированию Чтобы увеличить емкость СУБД, т.е. объем хранимых...
Недавно мы писали об изменении статуса и улучшении протокола KRaft в Apache Kafka 3.3. Сегодня погрузимся в эту тему чуть глубже и рассмотрим, как отказ от Zookeeper влияет на количество разделов и возможность одного и того же кластера Kafka с одним набором топиков обслуживать разные типы приложений в различных бизнес-сценариях....
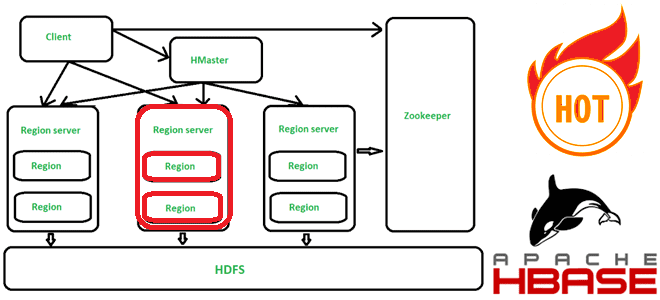
Что такое горячие точки в Apache HBase, почему они возникают, чем опасны и как их избежать. Для этого заглянем под капот NoSQL-хранилища, чтобы разобраться с особенностями хранения данных по ключу строки. Что такое горячие точки в кластере Apache HBase и почему они случаются Apache HBase представляет собой колоночно-ориентированное мультиверсионное хранилище...

23 января 2023 года вышел очередной релиз самой популярной платформы потоковой передачи событий. Разбираемся с новинками Apache Kafka 3.3.2: готовность протокола KRaft, новый API для метрик, разделитель по умолчанию для записей без ключа, исправления и улучшения, важные для дата-инженера и администратора кластера. Apache Kafka 3.3.2: главные новинки и изменения Минорный...
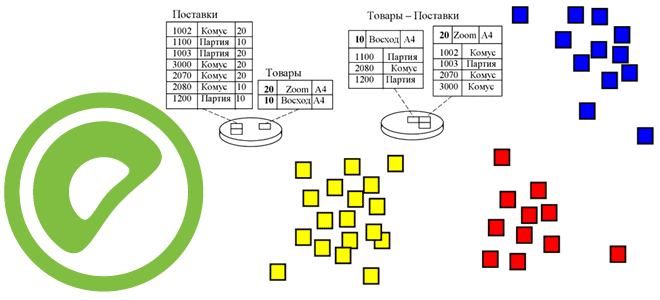
Что означает кластеризация таблиц в PostgreSQL, как это связано с индексацией и очисткой данных, чем полезно применение команды CLUSTER для AO/CO-таблиц в Greenplum 7, а также какой SQL-запрос поможет найти все кластеризованные таблицы в текущей базе данных. Как работает кластеризация таблиц в PostgreSQL Будучи основанной на объектно-реляционной базе данных PostgreSQL,...

Политики хранения, сжатия и очистки данных в топиках Apache Kafka: какие конфигурации нужно настроить, чтобы работать с файлами распределенных логов наиболее эффективно. Ликбез для администратора кластера Kafka и дата-инженера. Хранение данных в Apache Kafka Мы уже писали, что топик в Apache Kafka представляет собой не физическое, а логическое хранение данных....

Сегодня рассмотрим, как оптимизировать потребление памяти в приложениях Apache Flink, разобрав основные принципы работы и конфигурации настройки памяти этого вычислительного фреймворка. А также перечислим типовые ошибки, с которыми дата-инженер может столкнуться при разработке и эксплуатации Flink-приложений Компоненты памяти в Apache Flink Apache Flink обеспечивает эффективные рабочие нагрузки поверх JVM, строго...

Что такое SQL-оператор VACUUM, зачем эта команда нужна в Greenplum и как она работает. Разбираемся с таблицами системного каталога и тонкостями ускорения SQL-запросов в самой популярной MPP-СУБД. Что такое сборка мусора в Greenplum и PostgreSQL Напомним, в объектно-реляционной базе данных PostgreSQL, на которой основана MPP-СУБД Greenplum, о чем мы писали...

Мы уже писали про некоторые новинки свежего релиза Greenplum 7 здесь и здесь. Разбираемся, что еще полезного появилось в бета-версии, выпущенной 15 декабря 2022 года. А также рассмотрим, каковы ограничения этого выпуска и почему его пока нельзя использовать в production. Новые функции PostgreSQL Помимо возможности применения команды ALTER TABLE к...