
Зачем ограничивать доступ к папке с DAG и как это сделать: категории и роли пользователей в Apache AirFlow, способы входа в систему и конфигурации для настройки прав. Категории и роли пользователей Apache AirFlow Поскольку основным источником угрозы почти для любой информационной системы являются люди, при разработке методов обеспечения безопасности надо,...
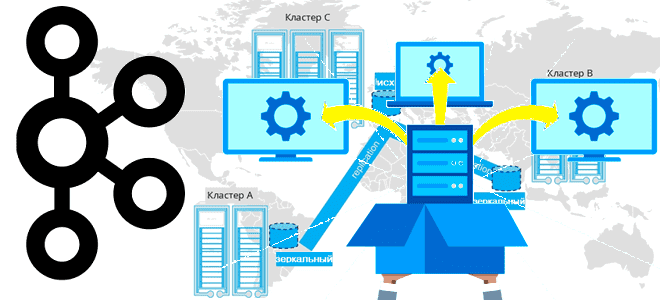
Завершая цикл статей про мультирегиональную репликацию кластеров Apache Kafka, сегодня поговорим про стратегии развертывания топологий, предлагаемых компанией Confluent. Принципы архитектуры, сравнение, сценарии, критерии выбора. Критерии выбора топологии репликации кластера Apache Kafka Для повышения надежности и производительность потоковой обработки данных с использованием Apache Kafka кластера этой платформы рекомендуется располагать в разных...
Продолжая разговор про межрегиональную репликацию Apache Kafka, сегодня рассмотрим 4 способа ее реализации: мультирегиональный кластер, MirrorMaker 2, Cluster Linking в Confluent Server и Confluent Replicator. Чем георепликация Kafka с MirrorMaker 2 отличается от решений Confluent и что выбирать для различных сценариев. Мультирегиональный кластер Confluent Геораспределенная репликация реплицирует данные по кластерам...
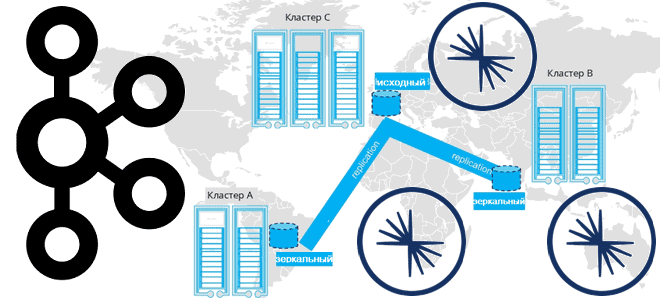
Недавно мы писали про мультирегиональную репликацию Apache Kafka. Сегодня рассмотрим, как выполнить геораспределенную репликацию с помощью Cluster Linking в Confluent Server и Kafka Connect с Confluent Replicator. Cluster Linking для Apache Kafka Связанные кластеры представляют собой 2 или более кластера в разных географических регионах. В отличие от топологии растянутого кластера,...
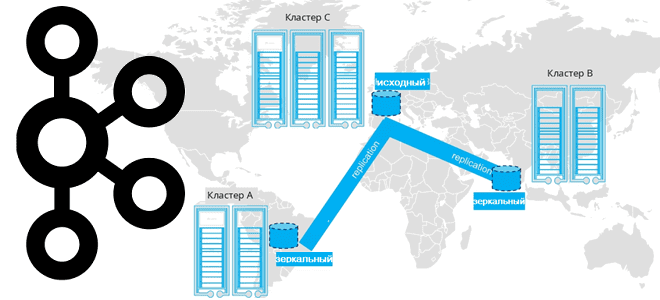
Какую топологию может иметь кластер Apache Kafka при межрегиональной репликации по нескольким ЦОД и как это реализовать. Чем брокеры-наблюдатели отличаются от подписчиков в Confluent Server и при чем здесь конфигурация подтверждений acks в приложении-продюсере. Принципы репликации данных в Apache Kafka Будучи средством интеграции информационных систем в режиме реального времени, Apache...

Какие инфраструктурные компоненты самые дорогие в эксплуатации популярной платформы потоковой передачи сообщений и как снизить затраты на сетевые ресурсы и хранилища данных при использовании Apache Kafka. TCO для Apache Kafka: что учитывать в расчете затрат Поскольку Apache Kafka используется для интеграции информационных систем в режиме реального времени, она становится критически...

Что лучше: один или несколько кластеров Apache Kafka, когда и зачем разворачивать новый кластер вместо масштабирования существующего, какие задачи администрирования поручить локальным DevOps-инженерам, а что решать централизовано. Один или несколько кластеров Apache Kafka? Продолжая разговор про эффективное управление корпоративным кластером Apache Kafka, сегодня рассмотрим, когда и зачем нужно разворачивать новый...

Зачем размещать задания Apache Spark на узлах HDFS, какую пропускную способность сети передачи данных выбрать, почему не рекомендуется использовать RAID для жестких дисков, сколько выделить памяти и ядер ЦП. Рекомендации по настройке оборудования для Spark-приложений На практике большинство заданий Spark считывает входные данные из внешней системы хранения, например, файловой системы...
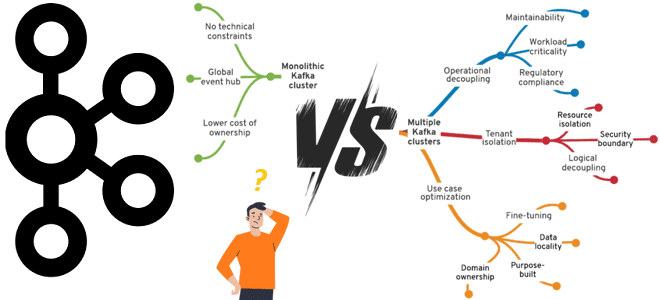
Что выбрать для эффективного управления корпоративным кластером Apache Kafka, от чего зависит уровень централизации и какие факторы влияют на принятие решений. Стратегии управления корпоративным кластером Apache Kafka Типовой вариант использования Apache Kafka – это потоковая интеграция корпоративных приложений. Чтобы эффективно использовать эту платформу потоковой передачи событий в масштабах предприятия, необходимо...
Как выполнить миграцию данных: лучшие практики и рекомендации на примере Greenplum. Особенности и принципы работы утилит gpbackup, gprestore и gpcopy. Миграция данных из Greenplum на 7 с утилитами gpbackup и gprestore Независимо от причины миграции данных из прикладной системы или корпоративного хранилища данных на новую технологию, эта процедура всегда остается...
Какие меры принять администратору кластера Apache Kafka, чтобы повысить надежность потоковой экосистемы, использующей эту распределенную платформу как средство интеграции различных приложений. Сбои в потоковой экосистеме и способы их устранения Хотя Apache Kafka считается высоконадежной системой благодаря множеству встроенных механизмов отказоустойчивости, таким как репликация и перевыборы лидера. Впрочем, это не исключает...
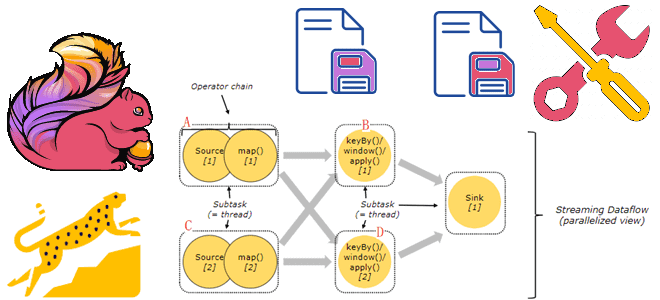
Почему хранить состояния Flink-приложений лучше на локальных SSD-диски, а не на твердотельных накопителях с удаленной файловой системой NFS или HDFS, зачем отключать блочный кэш RocksDB и как настроить параллелизм заданий. Проблемы сохранения состояния в RocksDB и способы их решения Как мы уже упоминали здесь, key-value хранилище RocksDB является самым популярным...

Ранее мы писали про проблемы повышения производительности Apache AirFlow и каковы их причины. В продолжение этой темы сегодня рассмотрим, как настроить этот ETL-оркестратор, чтобы избежать подобных ситуаций и масштабировать кластер в соответствии с нагрузкой. Настройка AirFlow на уровне среды Как мы уже отмечали, Apache AirFlow отлично масштабируется, обеспечивая высокую производительность...
Когда и почему нужно повышать производительность Apache AirFlow, как исполнитель влияет на масштабирование этого ETL-оркестратора. Почему падает производительность AirFlow и что с этим делать Типичными проблемами, которые требуют масштабирования кластера AirFlow, являются медленный доступ к файлам, недостаточный контроль над возможностями DAG, нерегулярные уровни трафика и конкуренция за ресурсы между рабочими...

10 октября 2023 года вышел очередной релиз самой популярной распределенной платформы потоковой передачи событий. Знакомимся с главными новинками Apache Kafka 3.6.0: промышленная поддержка KRaft вместо ZooKeeper, оптимизация транзакций, повышение производительности памяти и другие фичи свежего релиза для разработчика, дата-инженера и администратора. ТОП-10 новинок выпуска 3.6 Apache Kafka 3.6.0 включает 6...

Что настроить в Greenplum 7, чтобы сделать эту MPP-СУБД еще эффективнее. Обзор наиболее популярных параметров конфигурации и рекомендации по установке их значений. Ограничения подключений и выполнения SQL-запросов: 6 параметров с перезагрузкой системы Будучи зрелой системой со множеством настроек, Greenplum предоставляет администратору и дата-инженеру широкие возможности по адаптации этой СУБД к...

Зачем делать моментальные снимки состояния распределенной файловой системы Apache Hadoop, почему не стоит создавать снапшоты HDFS в корневом каталоге и как найти оптимальную частоту сохранения состояния больших данных. Как устроен механизм снапшотов в HDFS Чтобы повысить надежность системы, ее состояние необходимо периодически сохранять. Для баз данных и файловых систем эта...
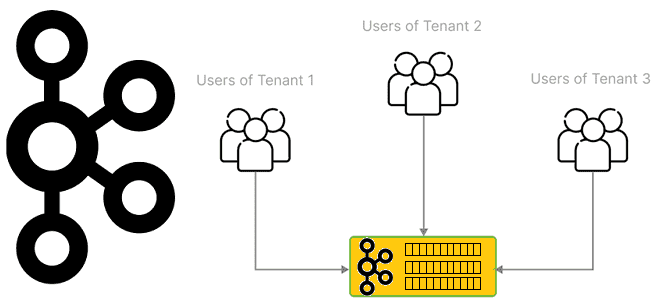
Что такое мультитенантность и как администратору Apache Kafka настроить изоляцию арендаторов в мультиарендном кластере: конфигурации, квоты и лайфхаки. Что такое мультиарендность и как реализовать эту модель для кластера Kafka Мультитенантность (мультитенантность, multitenancy) переводится с английского как множественная аренда и в контексте архитектуры ПО означает разделение одного экземпляра приложения между несколькими...
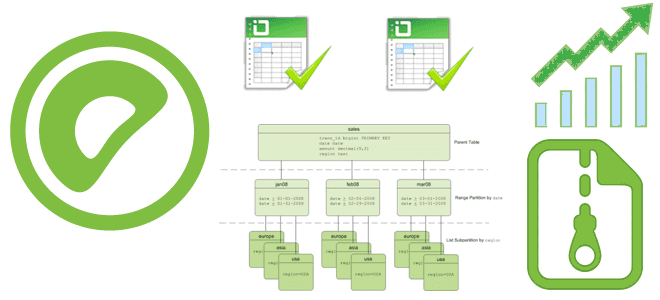
Как включить сжатие данных в Greenplum, какие алгоритмы сжатия поддерживает эта MPP-СУБД и можно ли установить разные параметры сжатия для отдельных столбцов и разделов больших таблиц. Примеры SQL-запросов и рекомендацию по настройке. Как Greenplum сжимает данные: примеры настроек и SQL-запросов Эффективное сжатие данных позволяет Greenplum снижать потребление памяти и повышать...

Как организовать миграцию схемы Neo4j и импортировать в графовую базу данные из реляционных систем. Знакомимся с инструментами проекта Neo4j Labs: Neo4j-ETL и Neo4j-Migrations. Как работает Neo4j-ETL В рамках развития своих продуктов, таких как графовая СУБД Neo4j и экосистема элементов вокруг нее (Graph Data Science, Neo4j Bloom, Neo4j Browser и пр.),...