
Зачем включать ротацию лог-файлов потоковых приложений Apache Spark, какие конфигурации помогут ее настроить и для чего сжимать файлы журналов в длительных заданиях. Чем полезна ротация лог-файлов Spark-приложений и как ее настроить Об общих принципах логирования системных событий в приложениях Apache Spark мы уже рассказывали здесь. В этой статье подробнее разберем...

Что не так с работой Apache AirFlow в многопользовательской среде, зачем предоставлять каждой команде свое развертывание ETL-фреймворка, каковы недостатки этого решения и как организовать мультитенантный кластер. Почему Apache Airflow не предназначен для многопользовательского использования В современной дата-инженерии Apache AirFlow стал наиболее популярным инструментом для пакетных ETL-процессов. Чтобы использовать его наиболее...

Как устроен планировщик заданий Apache AirFlow, от чего зависит его производительность и какие конфигурации помогут ее улучшить: настройки, приемы, рекомендуемые значения и лучшие практики. Как работает планировщик Apache AirFlow Apache AirFlow как фреймворк оркестрации пакетных процессов включает несколько компонентов. Одним из них является планировщик (scheduler), который отслеживает все задачи и...
Аналитика данных из топиков Kafka с помощью SQL-запросов: обращение к ksqlDB в Docker через CLI-интерфейс и REST API в Postman с SSH-тунелированием сервера потоковой базы данных. Практическое руководство с примерами и иллюстрациями. CLI-интерфейс ksqldb Docker-образ Confluent Kafka включает дополнительные компоненты этой платформы: ksqlDB, Kafka Connect, REST Proxy, Schema Registry). Сегодня...
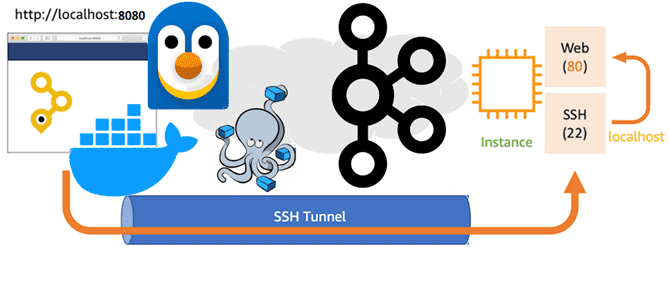
Как туннелировать порты Docker-контейнеров для доступа к Kafka на WSL в Windows с внешнего клиента: переадресация HTTP- и TCP-соединений с помощью SSH-сервера serveo. Поиск средства тунелирования и настройка портов Собственное развертывание платформы Kafka от Confluent в виде набора связанных Docker-контейнеров в WSL на Windows с GUI-интерфейсом AKHQ, о чем я...
Как настроить YAML-файл Docker Compose для доступа к Kafka на WSL в Windows: открытие портов в конфигурации развертывания с примерами (продолжение). Настройка конфигурационного YAML-файла для запуска Docker-контейнеров с компонентами Kafka на Windows в WSL Как я рассказывала вчера, для работы с компонентами платформы Kafka от Confluent, развернутой как набор связанных...

WSL и Docker для локального развертывания Apache Kafka с GUI и всеми компонентами в контейнере: моя реальная история поиска веб-интерфейса и настройки портов (начало). Развертывание Kafka на Windows с Docker в WSL В конце августа 2024 года команда serverless-платформы Upstash, на которой у меня есть рабочий инстанс Apache Kafka, разослала...
Зачем нужна автоматическая очистка таблиц системного каталога Greenplum, почему команда AUTOVACUUM выполняется локально на каждом сегменте и как ее настроить для максимальной эффективности старых кортежей в распределенной базе данных с массовой-параллельной обработкой. Параметры автоматической очистки в Greenplum О том, зачем нужна команда автоочистки в Greenplum и как она работает, мы...

29 июля 2024 года вышло очередное обновление Apache Kafka. Разбираемся с главными новинками релизе 3.8: поддержка JBOD в многоуровневом хранилище, детальная настройка уровня сжатия, улучшение безопасности и удаление неоднозначных конфигураций. ТОП-7 новинок Apache Kafka 3.8 Многоуровневое хранилище (Tiered Storage) для надежного долговременного хранения данных, опубликованных в Kafka, без ущерба высокой...

20 июня 2024 года вышел очередной релиз Greenplum. Разбираемся с ключевыми новинками выпуска 7.2: сканирование индекса в AO-таблицах, изменения в оптимизаторе GPORCA, улучшенная обработка геопространственных данных и новая служба централизованного управления сегментами Postmaster. Новинки Greenplum 7.2 для дата-инженера Начнем с изменений, повышающих производительность Greenplum. Одним из них стало сканирование индекса...
Как Apache Kafka использует страничный кэш операционной системы, какие конфигураций файловой системы надо настраивать для повышения пропускной способности и снижения задержки и каковы недостатки RAID-массивов для надежного хранения опубликованных сообщений. Страничный кэш ОС и быстродействие Kafka В отличие от RabbitMQ, Apache Kafka может обеспечить долговременное хранение сообщений, записывая их на...
Что такое задачи отчетности, зачем они нужны и как с их помощью отслеживать события и системные метрики экземпляра NiFi-приложения, а также JVM. Обзор Reporting Tasks в Apache NiFi 2.0. Задачи отчетности в Apache NiFi Чтобы отслеживать события и метрики работающего экземпляра приложения Apache NiFi, этот фреймворк предоставляет специализированные инструменты, которые...
Почему планировщик Apache AirFlow чувствителен к всплескам рабочих нагрузок, из-за чего тормозит база данных метаданных, как исправить проблемы с файлом DAG, лог-файлами и внешними ресурсами: разбираемся с ошибками пакетного оркестратора и способами их решения. Проблемы с планировщиком Хотя Apache AirFlow позиционируется как довольно простой фреймворк для оркестрации пакетных процессов с...
Как эффективно распределять и использовать ресурсы ClickHouse, зачем ограничивать возможности пользователей с помощью квот и классифицировать рабочие нагрузки. Управление ресурсами в ClickHouse Благодаря своей децентрализованной архитектуре ClickHouse, когда один экземпляр включает несколько серверов, к которым напрямую приходят запросы пользователей, эта колоночная СУБД работает очень быстро. Для репликации данных и выполнения...
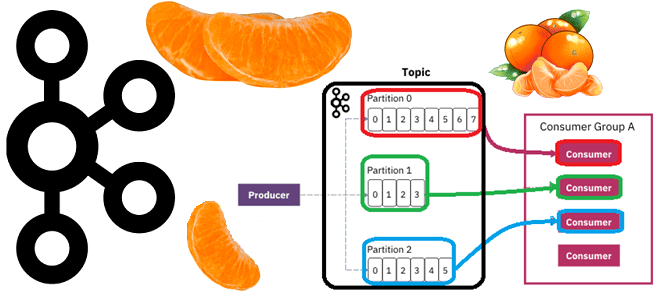
Почему раздел называется единицей параллелизма и как определить оптимальное число разделов в топике Apache Kafka в зависимости от количества потребителей и вариативности их поведения, разницы пропускной способности публикации и потребления сообщений, семантики партиционирования, толерантности к упорядоченности событий и ресурсных возможностей узла кластера. Что учитывать при разделении топика Apache Kafka Хотя...

Что такое graceful shutdown в Apache Kafka, когда используется такое плавное завершение работы, при чем здесь синхронизация реплик и как это влияет на плановые операции обслуживания кластера. Как работает механизм Graceful shutdown в Apache Kafka Благодаря множеству внутренних механизмов обеспечения отказоустойчивости, Apache Kafka имеет высокую надежность и позволяет строить нагруженные...

Как найти зависший процесс в базе данных Greenplum, создать резервную копию каталога, разделить лог-файл по тестам и проверить его на наличие повреждений. Знакомимся с набором утилит gpsupport. 6 инструментов утилиты gpsupport для техподдержки Greenplum Как и любая крупная система Greenplum, помимо компонентов, обеспечивающих ее ключевые функции, также включает дополнительные инструменты,...

Что такое WSL, Docker и как запустить веб-сервер Apache AirFlow в контейнере на локальной машине в Ubuntu поверх Windows вместо любимого Google Colab. Пошаговое руководство для начинающих дата-инженеров. Краткий ликбез по WSL и Docker для любителей Windows Обычно я всегда запускала веб-сервер Apache AirFlow в интерактивной среде Google Colab, которая...
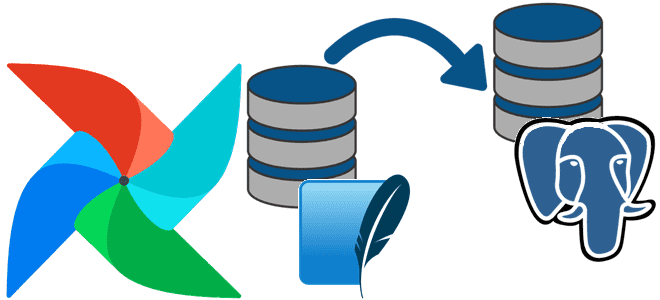
Зачем менять базу данных метаданных в производственном развертывании Apache AirFlow и как это сделать: пошаговое руководство для дата-инженера с примерами и рекомендациями. 5 шагов перехода от SQLLite к PostgreSQL: миграция базы данных метаданных Apache AirFlow Чтобы планировать и запускать конвейеры обработки данных, Apache AirFlow хранит сведения о задачах, DAG, исполнителях,...

Когда журналирование событий может привести к OOM-ошибке, где отслеживать системные метрики приложения Apache Spark, зачем сжимать лог-файлы и как это сделать. Логирование системных метрик в приложении Apache Spark Поскольку фреймворк Apache Spark изначально предназначен для создания высоконагруженных распределенных приложений пакетной и потоковой обработки больших объемов данных, он позволяет отслеживать системные...