
В продолжение темы про новое в экосистеме Apache Hadoop, сегодня мы расскажем о проекте Ozone: как и зачем появилось это масштабируемое распределенное хранилище объектов, чем оно отличается от HDFS, что у него общего с Amazon S3 и как этот фреймворк позволяет совместить преимущества SaaS-подхода с локальными кластерами Big Data. ...

Мы уже писали, что такое Kafka Connect и как этот инструмент обеспечивает потоковую передачу данных между Apache Kafka и другими системами на примере интеграции с Elasticsearch. Сегодня рассмотрим новый коннектор, который позволяет загружать данные из топиков Apache Kafka в платформу удаленного мониторинга работоспособности мобильных и веб-приложений New Relic через гибкий REST API....

Apache NiFi – это простая и мощная система для обработки и распределения больших данных в потоковом режиме, которая отлично справляется с огромными объемами и скоростями, оперируя с сотнями гигабайт и даже терабайтами информации. Однако, на практике при работе с этой Big Data платформой можно столкнуться с проблемой ввода-вывода (IOPS, Input-Output...

Мы уже рассказывали про основные достоинства и недостатки Apache Airflow, с которыми чаще всего можно столкнуться при практическом использовании этого оркестратора конвейеров обработки больших данных (Big Data). Сегодня рассмотрим некоторые специфические ограничения, характерные для этой open-source платформы и способы решения этих проблем на реальных примерах. Все по плану: 5 особенностей...

Сегодня мы продолжим разговор о событийно-процессной архитектуре Big Data систем на примере использования Apache Kafka в The New York Times. Читайте далее, как одно из самых известных американских СМИ с более чем 160-летней историей хранит в Apache Kafka все свои статьи и с помощью API Kafka Streams публикует контент в...

В этой статье мы поговорим про возможность нехарактерного использования Apache Kafka: не как распределенной стримминговой платформы или брокера сообщений, а в виде базы данных. Читайте далее, как Apache Kafka дополняет другие СУБД, не заменяя их полностью, почему такой вариант использования возможен в Big Data и когда он не совсем корректен....
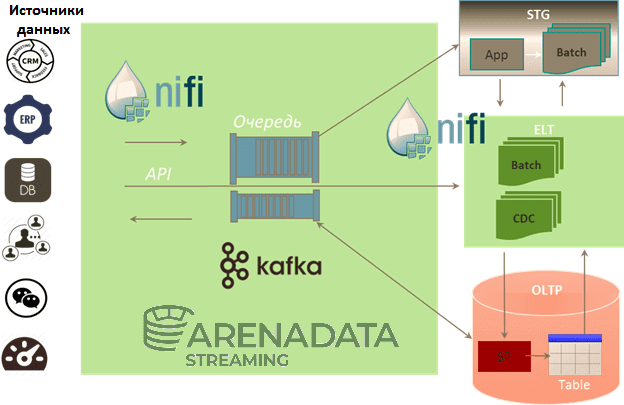
Мы уже рассказывали про преимущества совместного использования Apache Kafka и NiFi. Сегодня рассмотрим, как эти две популярные технологии потоковой обработки больших данных (Big Data) сочетаются в рамках единого решения от отечественного разработчика - Arenadata Streaming. Читайте далее про основные сценарии использования и ключевые достоинства этого современного продукта класса Event Stream...

Вчера мы говорили про наиболее перспективные технологии 2020 с точки зрения исследовательского агентства Gartner и их влияние на цифровую трансформацию. Сегодня продолжим разбирать современные тенденции изменения рабочего пространства с учетом эпидемиологической напряженности и тренда на дистанционное взаимодействие. Читайте далее, что такое Desktop as a Service, как выглядит интеллектуальное рабочее пространство,...

Продолжая разговор про обучение Spark на реальных примерах, сегодня мы рассмотрим, как работает этот Big Data фреймворк на Kubernetes, популярной DevOps-платформе автоматизированного управления контейнеризированными приложениями. Читайте в нашей статье, как запустить приложение Apache Spark в кластере Kubernetes (K8s) с помощью submit-скрипта и оператора, а также при чем здесь Docker-образ. Запуск...

Вчера мы рассказывали об основных сценариях запуска Apache Spark на Kubernetes и преимуществах этого варианта развертывания популярного Big Data фреймворка на DevOps-платформе автоматизированного управления контейнеризированными приложениями. Сегодня поговорим про обратную сторону всех этих преимуществ: читайте в нашей статье, каковы основные ограничения и главные недостатки запуска Apache Spark на Kubernetes (K8s)....
Чтобы сделать курсы по Spark еще более интересными и полезными, сегодня мы расскажем, зачем этот Big Data фреймворк разворачивают на Kubernetes (K8s) – платформе автоматизации развёртывания, масштабирования и управления контейнеризированными приложениями. Читайте в нашей статье про основные варианты использования и достоинства этого подхода к администрированию и эксплуатации Apache Spark. Зачем...
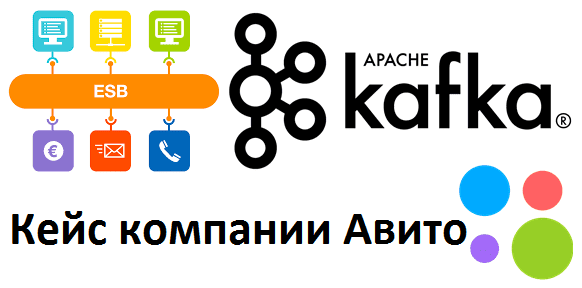
Есть мнение, что использование Apache Kafka в качестве корпоративной сервисной шины (ESB, Enterprise Service Bus) является антипаттерном. Сегодня мы проясним это категоричное утверждение и рассмотрим, как корректно реализовать ESB с помощью Kafka на практическом примере шины данных в компании Avito.ru. Что такое ESB и чем это отличается от брокера сообщений...
Сегодня рассмотрим примеры совместного использования двух популярных технологий потоковой обработки больших данных (Big Data): Apache Kafka и NiFi. Читайте в нашей статье, как они дополняют друг друга, каковы преимущества их объединения и каким образом инженеру Data Flow это реализовать на практике. Еще раз о том, что такое Apache Kafka и...

Администрирование кластера Kafka порой напоминает работу детектива, когда нужно понять мотив преступления причину появления того или иного бага и устранить ее вместе с последствиями наиболее оптимальным способом. В этой статье мы рассмотрим несколько практических примеров конфигурирования Apache Kafka из опыта компании Booking.com, кейс которой был представлен в докладе ее сотрудника...

В продолжении серии статей по докладу Александра Миронова из Booking.com, который был представлен 23 января 2020 года на зимнем Kafka-митапе Avito.Tech, сегодня мы рассмотрим некоторые проблемы администрирования Apache Kafka, с которыми можно столкнуться на практике. Читайте в этом материале, как не допустить разрастание топика, правильно задав параметр CreateTime. Что делать,...

Аутентификация – далеко не единственная возможность обеспечения информационной безопасности в Apache Kafka. Сегодня мы продолжим разговор про Big Data cybersecurity и рассмотрим особенности авторизации в Apache Kafka в формате самообслуживания (self-service), как это было сделано в travel-компании Booking.com. В качестве примера продолжим разбирать доклад Александра Миронова, который был представлен 23...

Продолжая разбирать доклад Александра Миронова из Booking.com, который был представлен 23 января 2020 года на зимнем Kafka-митапе Avito.Tech, сегодня мы рассмотрим, с какими проблемами столкнулись администраторы Big Data при обеспечении информационной безопасности своих Кафка-кластеров. Читайте в нашей статье про возможные методы аутентификации в Apache Kafka и их практическое использование в...

Сегодня мы разберем доклад Александра Миронова из Booking.com, который был представлен 23 января 2020 года на зимнем Kafka-митапе Avito.Tech [1]. Читайте в нашей статье, как одна из ведущих travel-компаний использует Apache Kafka, с какими проблемами столкнулись администраторы ее Big Data инфраструктуры и DevOps-инженеры, а также почему были выбраны именно такие...

Сегодня мы расскажем, почему каждый Big Data специалист должен знать этот язык программирования и как «Школа Больших Данных» поможет вам освоить его на профессиональном уровне. Читайте в нашей статье, кому и зачем нужны корпоративные курсы по Python в области Big Data, Machine Learning и других методов Data Science. Чем хорош...

Вчера мы рассказывали про самые известные утечки Big Data с открытых серверов Elasticsearch (ES). Сегодня рассмотрим, как предупредить подобные инциденты и надежно защитить свои большие данные. Читайте в нашей статье про основные security-функции ELK-стека: какую безопасность они обеспечивают и в чем здесь подвох. Несколько cybersecurity-решений для ES под разными лицензиями...