
Недавно мы рассказывали про новые функции обеспечения информационной безопасности в свежем релизе Apache NiFi 1.14.0. В продолжение темы cybersecurity, сегодня рассмотрим пару внутренних уязвимостей с умеренной степенью серьезности. Читайте далее, чем опасно раскрытие конфиденциальных данных и значений параметров свойств процессора при переходе в режим отладки, а также как была устранена...

Продолжая обучение основам Apache Hadoop для начинающих администраторов, сегодня рассмотрим архитектуру и принципы работы YARN в кластере. Также разберем, какие отказы могут случиться на каждом из его компонентов и как Resource Manager системы YARN обеспечивает высокую доступность кластера Apache Hadoop. Зачем Apache Hadoop нужен YARN и как он работает Поскольку...

Мы уже рассказывали про коннектор Greenplum-Spark, 2-я версия которого вышла в октябре 2020 года. А сегодня рассмотрим российскую альтернативу для отечественной MPP-СУБД Arenadata DB на базе Greenplum, выпущенную компанией Аренадата в июле 2021 года. Краткий обзор ADB-Spark Connector: архитектура, принципы работы, сценарии использования, а также отличия от PXF-фреймворка и варианта...

При том, что Apache Hadoop – высоконадежная экосистема хранения и аналитики больших данных, отказы случаются и в ней. Сегодня в рамках обучения начинающих администраторов и разработчиков Hadoop разберем, какие типы сбоев возможны в распределенной файловой системе HDFS и механизмы их предупреждения, а также рассмотрим процедуру вывода узлов из кластера для...

Сегодня рассмотрим, как упростить работу дата-инженера в Apache AirFlow, автоматизировав процесс создания DAG’ов из одного или нескольких Python-файлов. На практических примерах разберем достоинства и недостатки 5 способов динамической генерации, а также особенности масштабирования Big Data pipeline’ов. Что такое динамическая генерация DAG в Apache Airflow и зачем она нужна В статье...

14 июля 2021 года вышел минорный релиз Apache NiFi – версия 1.14.0. Сегодня рассмотрим его главные фичи, исправленные ошибки и улучшения, уделив особое внимание новым функциям обеспечения информационной безопасности в этой популярной платформе управления потоками Big Data. ТОП-5 новинок Apache NiFi 1.14.0 В новом выпуске Apache NiFi 1.14.0 исправлено 139...

Продолжая обучение дата-инженеров, сегодня рассмотрим, как сделать управление потоками данных в Apache NiFi эффективнее. Читайте далее, какие настройки позволят обойтись без процессора RetryFlowFile для повторных попыток, зачем менять GetFile на ListFile и FetchFile, когда использовать воронки и почему типичные настройки Linux не подходят для NiFi. Неочевидные особенности готовых процессоров Напомним,...

В рамках практического обучения дата-инженеров сегодня мы собрали 10 лучших практик проектирования конвейеров обработки данных в рамках Apache AirFlow, которые касаются не только особенностей этого фреймворка. Также рассмотрим, какие принципы разработки ПО особенно полезны для инженерии больших данных с Apache AirFlow. ТОП-10 рекомендаций дата-инженеру для настройки Apache Airflow и не...

В недавней статье про оптимизацию SQL-запросов в Greenplum мы рассказывали про планы их выполнения и операторы просмотра этих планов. Сегодня разберем подробнее, какие операции с данными могут встретиться в отчете, сгенерированном командой EXPLAIN, а также рассмотрим, чем эта информация полезна дата-инженеру и аналитику данных. 5 операций в плане выполнения SQL-запросов...
Добавляя в наши курсы по Apache AirFlow еще больше полезных практик, сегодня разберем опыт дата-инженеров американской компании Groupon по настройке этого фреймворка. Читайте далее, как добавить собственные KPI исполнения конвейеров обработки данных в эту workflow-платформу, делая его веб-GUI более наглядным и удобным для управления DAG’ами. Типовые возможности веб-GUI Apache Airflow...

Продолжая разбирать особенности разработки потоковых приложений Apache Flink, сегодня рассмотрим проблему падения пропускной способности задания из-за встроенного хранилища состояний RocksDB и ее зависимость от производительности дисков. Вас ждет настоящая детективная история о том, как важно заглядывать под капот облачных кластеров и настраивать конфигурации своих stateful-приложений потоковой аналитики больших данных с...
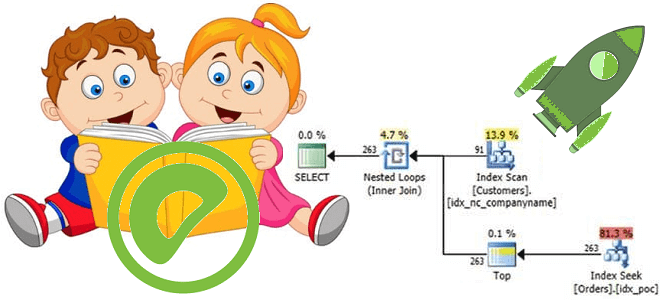
Обучая дата-аналитиков и инженеров данных тонкостям MPP-СУБД Greenplum, сегодня разберем, какой оператор помогает просмотреть план выполнения SQL-запроса, почему добавлять ANALYZE к EXPLAIN нужно с осторожностью и где найти универсальное решение анализа и визуализации PostgreSQL-совместимых продуктов. Я все объясню: команда EXPLAIN в PostgreSQL Разобравшись с оператором анализа и сбора статистики по...

Развивая наши курсы по Apache AirFlow для дата-инженеров и администраторов, сегодня рассмотрим, как автоматизировать обслуживание этого фреймворка, запуская поддерживающие операции как рабочие задачи по расписанию. В этой статье разбираем опыт дата-инженеров американской ИТ-компании Clairvoyant, предложивших сообществу 3 разных DAG по обслуживанию Apache AirFlow в виде open-source проектов, доступных для свободного...

Чтобы сделать наши курсы по Greenplum и аналитике больших данных еще более полезными, сегодня рассмотрим особенности выполнения SQL-запросов в этой MPP-СУБД. Читайте далее, зачем и когда запускать оператор анализа табличной статистики ANALYZE, как он связан с планом выполнения SQL-запроса и какие инструменты помогут дата-инженеру, аналитику или разработчику повысить их производительность....
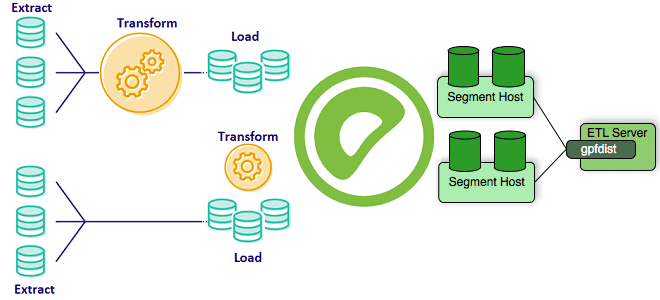
Greenplum часто используется в качестве корпоративного хранилища или аналитического озера данных (Data Lake). Поэтому важно знать особенности реализации ETL-процессов при работе с этой MPP-СУБД, что входит в наш новый курс «Greenplum для инженеров данных». Сегодня рассмотрим способы загрузить большие данные в Greenplum, разберем отличия внешних таблиц от внутренних и отметим,...
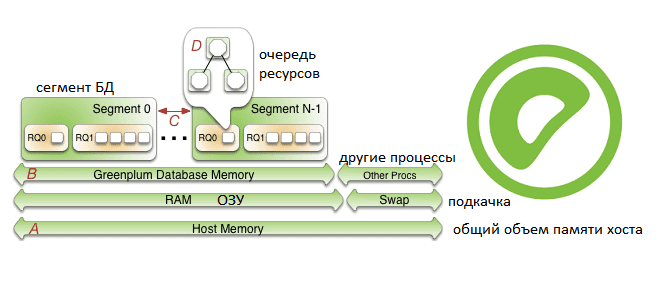
Продолжая рассказывать про наш новый курс «Greenplum для инженеров данных», сегодня поговорим про особенности конфигурирования памяти в этой MPP-СУБД: разберем, как память хоста распределяется между сегментами и рассмотрим, как администратор кластера может ускорить работу этой базы данных. Также читайте далее о связи RAM с настройками ядра операционной системы и схемами...

Cегодня рассмотрим некоторые инструменты защиты данных в Greenplum. Читайте далее про особенности шифрования в этой MPP-СУБД и лучшие практики обеспечения информационной безопасности и защиты в этой системе хранения и аналитики больших данных. Администраторы и суперпользователи Greenplum Для надежной защиты данных, хранящихся в MPP-СУБД Greenplum, и обеспечения информационной безопасности кластера рекомендуется...

Развивая наш новый курс «Greenplum для инженеров данных», сегодня рассмотрим, почему в этой MPP-СУБД возникают проблемы нехватки памяти, каковы типовые способы их решения и чем очереди ресурсов отличаются от ресурсных групп. Читайте далее про схемы управления ресурсами в Greenplum и особенности параметра конфигурации statement_mem. Очереди vs Группы: 2 схемы управления...

Продолжая рассказывать про наш новый курс «Greenplum для инженеров данных», сегодня рассмотрим некоторые особенности хранения данных в этой MPP-СУБД, а также разберем связанные с ними лучшие практики ее администрирования. Читайте далее про важность RAID-массивов, механизмы дублирования кластеров, утилиты резервного копирования и восстановления данных в Greenplum. RAID-массивы и зеркалирование жестких дисков...

Один из факторов повышенной надежности Apache Kafka обеспечивается записью сообщений на жесткий диск. Однако, операции ввода-вывода (IO, input-output) с дисковым пространством считаются медленными и часто являются узким местом во всей системе. Спустившись на уровень операционной системы и ядра, сегодня рассмотрим, как Kafka справляется с этим ограничением, позволяя быстро обрабатывать огромные...