
Как оптимизировать многопоточную обработку в ClickHouse и эффективно распределить ресурсы ЦП между разными пользователями и запросами, спланировав рабочую нагрузку. Настройка многопоточной обработки в Clickhouse Чтобы эффективно утилизировать ресурсы для аналитической обработки огромных объемов данных, в ClickHouse можно спланировать рабочую нагрузку, определив приоритеты использования памяти, диска и ЦП для разных видов...
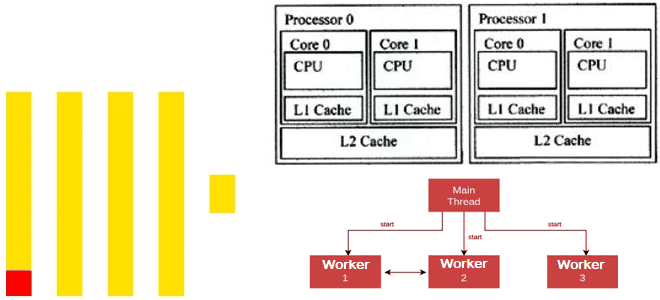
Как ClickHouse распараллеливает обработку данных для максимального использования всех ядер ЦП: особенности многопоточных вычислений в колоночной СУБД. Особенности многопоточной обработки в Clickhouse Современные центральные процессоры (ЦП) содержат несколько ядер и могут работать с несколькими задачами одновременно. Это называется многопоточной обработкой, где каждый поток, последовательность выполняемых инструкций, представляется как отдельная задача....

Почему провайдерам Kafka как сервиса недостаточно многоуровневого хранилища (KIP-405) и зачем они предложили новое улучшение KIP-1150, меняющее архитектуру хранения и репликации данных напрямую в объектные системы. Кому и зачем понадобилась бездисковая Kafka: что не так с KIP-405 Одной из наиболее интересных тем вокруг Apache Kafka в апреле 2025 года стало...
Зачем в ClickHouse 25.4 добавлена отложенная материализация и как ленивые вычисления позволяют ускорить работу аналитической СУБД благодаря сокращению объемов читаемых данных и снижению количества операций дискового ввода-вывода. Еще раз о пользе ленивых вычислений Отложенные или ленивые вычисления (lazy evaluation), которые выполняются не сразу, а откладываются до момента, когда их результат...
Зачем нужен каталог метаданных и как он работает: построение платформы данных и управление метаданными по DAMA DMBOK. Unity Catalog и другие решения для учета источников данных и непрерывного обеспечения их актуальности. Управление метаданными по DMBOK Методологически создание и внедрение платформ данных основано на положениях DAMA DMBOK – своде знаний по...
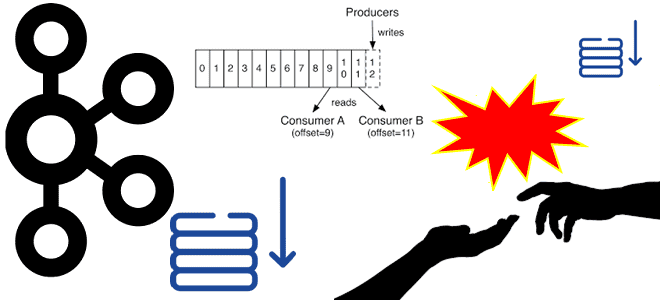
Когда и зачем фиксировать смещение потребителей Kafka вручную, с какими проблемами можно при этом столкнуться и как улучшение KIP-1094 обеспечивает целостность потоков данных в распределенных средах. Когда и зачем фиксировать смещения потребителей в Kafka вручную Недавно мы разбирали, как выполняется автоматическая фиксация смещений потребителей в Apache Kafka. Она выполняется периодически....
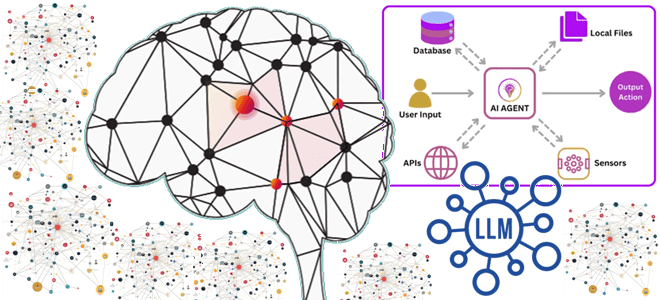
Что не так с векторным RAG: обогащение LLM данными из графовых баз с помощью MCP-протокола, вычислительных движков и коннекторов для построения ML-системы агентского ИИ. Что такое графовый RAG для LLM и ИИ-агентов Большие языковые модели (LLM, Large Language Model) и основанные на них системы агентского ИИ активно используют векторные базы...

Что общего у ClickHouse и StarRocks, чем они отличаются, и что выбирать для аналитики больших данных в реальном времени: сравнение колоночных OLAP-СУБД с векторным движком. Чем похожи ClickHouse и StarRocks: 7 главных сходств Хотя ClickHouse сегодня считается одной из наиболее популярных СУБД для аналитики больших данных в реальном времени с...

Что общего у StarRocks с Trino, чем они отличаются, когда и что выбирать для практического использования: сравниваем движки для быстрой аналитики больших данных из Data Lake. Чем похожи StarRocks и Trino Вчера мы разбирали, что такое StarRocks, как устроена и где пригодится эта высокопроизводительная аналитическая база данных с открытым исходным...

Вместо Trino и ClickHouse: что такое StarRocks и как оно устроено, архитектура и принципы работы, сценарии использования и место в корпоративной архитектуре данных. Архитектура и принципы работы StarRocks Хотя ClickHouse сегодня считается одним из наиболее популярных колоночных хранилищ для аналитики больших объемов данных в реальном времени, это не единственный представитель...

22 апреля 2025 вышел долгожданный крупный релиз Apache Airflow. Знакомимся с главными новинками версии 3.0: изменения архитектуры и пользовательского интерфейса для повышения устойчивости и безопасности фреймворка. Еще раз про версионирование DAG в Apache AirFlow 3.0 Недавно мы писали про бета-релиз Apache AirFlow 3.0. Теперь мажорная версия вышла официально и доступна...
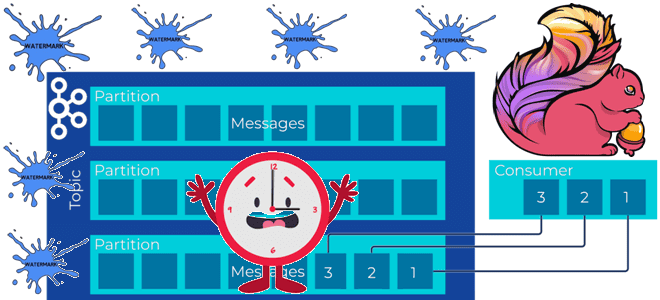
Почему задание Flink не обрабатывает потоковые данные из топика Kafka и при чем здесь водяные знаки: причины потери данных или растущей задержки вычислений и способы их решения. Почему задание Flink не обрабатывает потоковые данные и при чем здесь водяные знаки? Рассмотрим простой потоковый конвейер на Apache Flink и Kafka: задание...
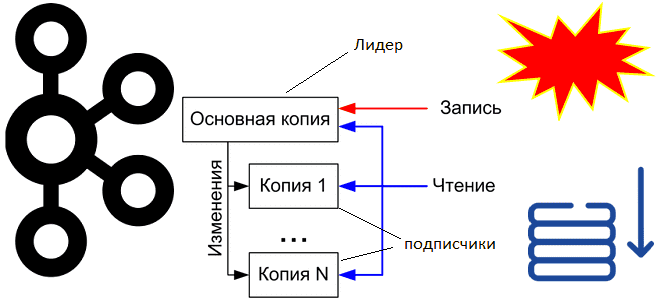
Как Apache Kafka обеспечивает упорядоченность сообщений в рамках раздела, где хранятся смещения потребителей и зачем их фиксировать вместе со эпохой брокера-лидера. Что такое смещения потребителей Apache Kafka и где они хранятся Асинхронная интеграция между информационными системами через Apache Kafka основана на смещениях потребителей – позиции сообщения в разделе топика. Раздел...
Как сократить затраты на хранение исторических данных в ClickHouse для ИИ-сценариев, сохранив высокую скорость аналитики по широким таблицам и озеру данных: эволюция колоночной СУБД в новом проекте с исходным кодом Antalya от Altinity. Проблемы совмещения ClickHouse с озерами данных и способы их решения Благодаря колоночной структуре хранения данных ClickHouse не...
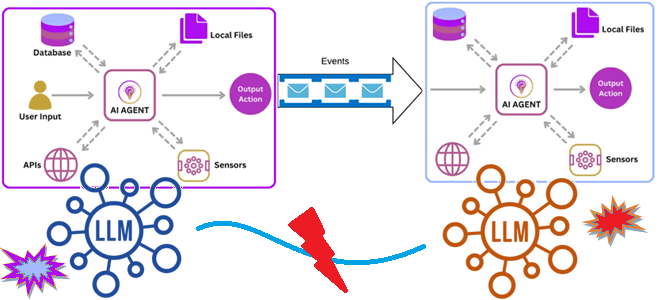
Как связать ИИ-агентов: событийно-ориентированная архитектура и потоковая передача событий для интеграции доменных LLM в мультиагентную систему. Зачем нужна интеграция ИИ-агентов О проблеме изоляции и рассинхронизации данных в корпоративных хранилищах мы уже писали здесь. Похожая ситуация наблюдается и при внедрении систем агентского ИИ, где большие языковые модели (LLM, Large Language Model)...
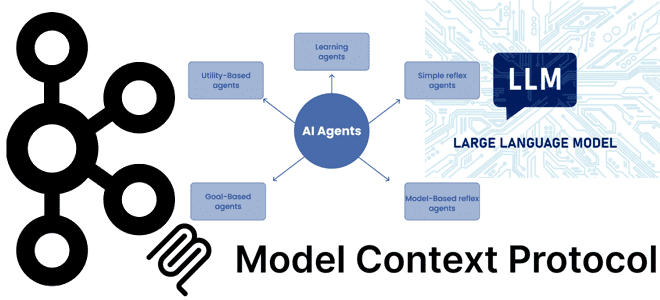
Почему MCP-серверы с технологиями потоковой передачи событий в LLM стали трендом: примеры обогащения ИИ-агентов контекстом из Kafka. Внедрение MCP в Confluent Cloud для взаимодействия с Apache Kafka Хотя MCP-протокол, позволяющий ML-модели новыми контекстными данными, что необходимо для больших языковых моделей (LLM, Large Language Model), довольно прост с технической точки зрения,...
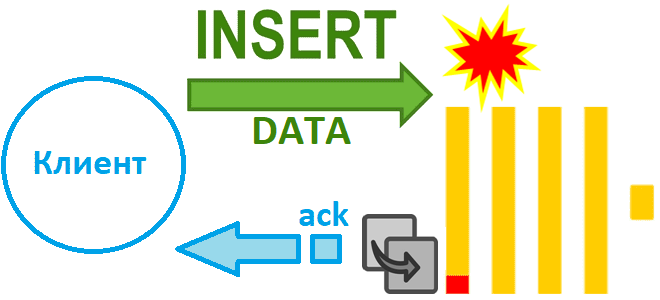
Как избежать потери данных при асинхронной вставке в Clickhouse при сбое сервера и зачем в версию 24.2 добавлен адаптивный тайм-аут очистки буфера: тонкости ETL с колоночной СУБД. Асинхронная вставка с возвратом подтверждения Недавно мы рассказали, чем хороши асинхронные вставки в ClickHouse и отметили, что при их использовании можно настроить параметр...
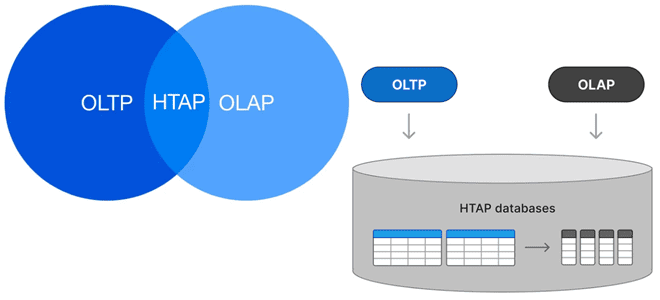
Можно ли сочетать OLAP и OLTP-нагрузки в едином хранилище и как это сделать: гибридная транзакционно-аналитическая обработка в базах данных, возможности и проблемы этой архитектуры. Что такое HTAP Исторически хранилища данных принято делить на OLAP и OLTP с учетом их оптимизации для аналитических и транзакционных нагрузок. OLTP-системы (Online Transaction Processing) оптимизированы...
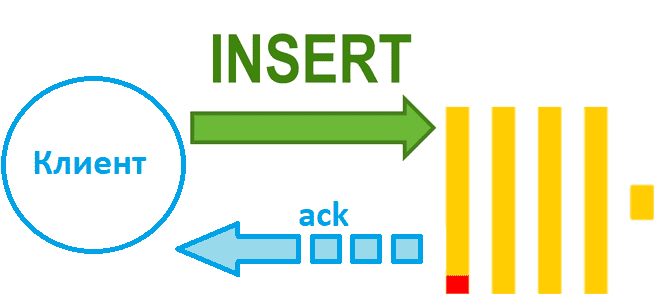
Чем синхронная вставка в ClickHouse отличается от асинхронной и как это настроить: лучшие практики и риски загрузки данных в колоночное хранилище. Синхронная вставка данных в ClickHouse Хотя скорость вставки данных в ClickHouse зависит от множества факторов, ее можно ускорить за счет асинхронных вставок, если предварительное пакетирование на стороне клиента невозможно....
Как именно формат, сортировка, сжатие и интерфейс передачи данных в ClickHouse влияют на скорость операций загрузки: бенчмаркинговое сравнение от разработчиков колоночной СУБД. В каком формате данные быстрее всего вставляются в ClickHouse Продолжая недавний разговор про вставку данных в ClickHouse, сегодня рассмотрим, ключевые факторы, которые особенно сильно влияют на скорость загрузки...