 1105
1105 
Содержание
Проблема своевременного пополнения товарных запасов актуальна для любого ритейлера. Разбираемся, как торговый гигант США Walmart построил свою платформу планирования и пополнения продукции в реальном времени на базе Apache Kafka: ключевые требования к системе, архитектура и принципы работы, настройка конфигураций продюсеров и потребителей.
Постановка задачи: пополнение товарного запаса в реальном времени
Американский ритейлер Walmart управляет крупнейшей в мире сетью оптовых и розничных магазинов. Более 5 тысяч торговых точек, тысячи поставщиков, около 150 распределительных центров, миллионы транзакций в день от миллионов покупателей. Чтобы удовлетворить своих клиентов, Walmart должен обеспечить планирование и пополнение запасов в режиме реального времени на каждом физическом узле в сети цепочки поставок. Как только запасы опускаются ниже определенного порога, необходимо автоматически пополнять этот товар так, чтобы оптимизировать ресурсы и повысить удовлетворенность клиентов, с учетом прогноза продаж, ограничений на количество товаров, его текущей доступности и множества других факторов. К таким факторам относятся бизнес-цели, характерные для ритейла, которые определяют требования к ИТ-решению:
- сокращение времени цикла – периода между выполнением заказа и поступлением товаров в магазин. ИТ-платформа автоматизированного планирования товарных заказов должна учитывать правильные входные параметры для календарей поставщиков и комплектации распределительных центров при выполнении плана для большого количества товаров за короткий период времени.
- увеличение точности в отношении качества и количества запасов – нет смысла доставлять товары, которые не пользуются спросом у покупателей, т.к. они занимают место, не принося прибыли;
- повышение скорости – нужно оптимизировать цепочку поставок, чтобы эффективно использовать все преимуществ каждой доставки из каждого распределительного центра согласно ограничению на плановое время обработки заказов в соответствии с планом. Встает задача точного планирования заказов для большого количества артикулов за очень короткий промежуток времени. Поэтому каждый компонент ИТ-платформы должен работать очень быстро.
- снижение сложности – нужно обеспечить высокую производительность платформы и простоту ее архитектуры, чтобы быстро добавлять функции для реагирования на новые потребности цепочки поставок, быстро отлаживать и анализировать любые системные и функциональные проблемы.
- обеспечение эластичности, масштабируемости и отказоустойчивости с учетом постоянно растущего объема данных и набора функциональных потребностей.
Как все эти требования были реализованы в рамках системы на базе Apache Kafka, мы рассмотрим далее.
Архитектура системы
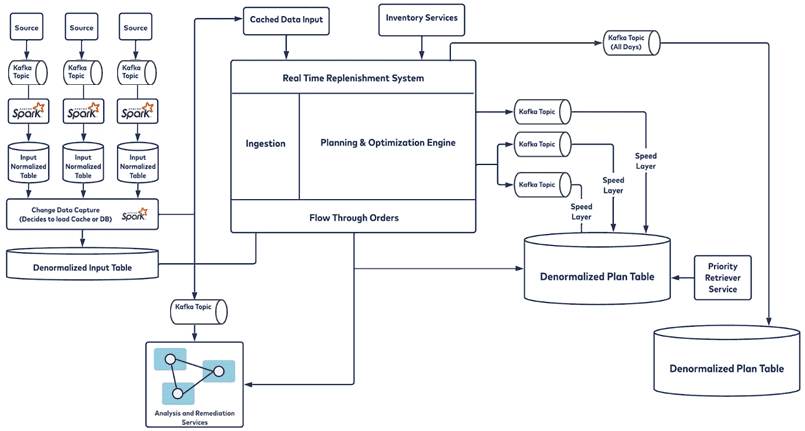
Ежедневно система пополнения запасов Walmart в режиме реального времени обрабатывает более десятков миллиардов сообщений от почти 100 миллионов артикулов товарных позиций менее чем за три часа с высокой точностью и пропускной способностью 85 ГБ сообщений в минуту.
Среда обработки событий использует микропакетную архитектуру, при этом большая часть входных данных поступает через Kafka. Из Kafka данные передаются через систему сбора измененных данных (CDC) и переводятся в денормализованное представление, чтобы к ним можно было быстро получить доступ. Затем данные обрабатываются в движке планирования, который содержит все позиции запасов, прогнозы, страховые запасы, время выполнения заказов и календари, учитывая все логистические и прочие ограничения центров распределения, магазинов и методов доставки. Затем весь этот план публикуется в разных топиках Kafka для разных уровней, у каждого топика есть свои потребители, которые выполняют разные действия. Walmart использует 18 брокеров Kafka с более чем 20 топиками, в каждом из которых 500+ разделов.
В дополнение к вышеупомянутой отказоустойчивости и горизонтальной масштабируемости для будущих потребностей, аналитики Walmart выделили еще ряд важных архитектурных задач и целей, связанных с настройкой системы пополнения складских запасов в реальном времени:
- замена товара в реальном времени, чтобы пополнение происходило в режиме онлайн. Для этого входные данные должны приниматься и обрабатываться с помощью потоковых технологий;
- мультиарендность для эффективной работы более чем в 24 странах, нужна единая платформа, где арендаторы используют нужные им функции с сохранением работоспособности системы при добавлении новых функций;
- быстрое принятие решений различными нижестоящими потребителями конвейера обработки данных в реальном времени по заказам и планам пополнения;
- тесная связь между входными данными и движком пополнения запасов, чтобы обеспечить высокую точность плана. Важно знать о любом изменении, чтобы соблюсти жесткий контракт между вводом и механизмом пополнения.
Walmart использует активно-пассивную репликацию данных, переключаясь на дополнительный ЦОД в случае проблем в основном центре обработки данных. При этом нужно знать, с какого смещения основной контроллер домена остановил обработку, чтобы начать с этого момента или убедиться, что потребитель или клиент не обрабатывают повторяющиеся сообщения. В Walmart разработаны автоматические механизмы, которые быстро восстановят отказавшие узлы или виртуальные машины в случае сбоя. Разрешив повторные попытки отправки сообщений в Kafka, инженеры Walmart реализовали внутренний механизм аудита и воспроизведения, который поможет восстановиться после сбоя. Сообщение отправляется в топик Kafka и сохраняется в базе данных. Также настроен резервный механизм на случай невозможности отправки сообщения в сам топик Kafka в виде REST-сервиса, который напрямую обращается и записывает данные в базу. Внутренний механизм оповещения на основе подписки держит администраторов системы в курсе всех критических событий, как на уровне приложения, так и на уровне инфраструктуры.
Ключевые настройки конфигураций Apache Kafka
Чтобы система на базе Kafka хорошо работала, нужно оптимально настроить параметры конфигурации всех ее компонентов, включая продюсеров, потребителей и сам кластер. Любая задержка на уровне продюсера или потребителя может снизить скорость работы всей системы и риск несоблюдения SLA.
В части продюсеров была определена специальная стратегия разделения, чтобы вместо циклического перебора сообщение сразу отправлялось в нужный раздел топика. Это особенно важно в масштабе Walmart: стратегия циклического перебора, используемая по умолчанию, привела бы к тому, что все сообщения из 150 распределительных центров, которые читаются в течении 3-4 часов, обрабатывались бы слишком долго. Альтернативная стратегия разделения позволила получить скорость, обеспечив необходимую изоляцию и точность данных.
Также были настроены конфигурации linger.ms и batch.size, которые работают в сочетании друг с другом, обеспечивая высокую производительность приложения-продюсера, о чем мы писали здесь. Наконец, была настроена конфигурация acks — число подтверждений об успешной записи сообщения в топик от брокеров Kafka. Для Walmart согласованность данных была критичной, поэтому acks установлен в значение -1 или all, когда продюсер ждет полной репликации сообщения по всем серверам кластера, что обеспечивает надежную защиту от потери данных, но увеличивает задержку и снижает пропускную способность. Подробнее об этом читайте здесь.
Для потребителя были настроены следующие конфигурации:
- mpoll.records — количество сообщений, полученных в одном полном опросе;
- poll.interval.ms — время, в течение которого потребитель должен обработать эти сообщения;
- auto.commit – автоматическая фиксация смещений после обработки получаемых сообщений в рамках одного запроса. Чтобы предотвратить потерю данных и убедиться в полной обработке всех полученных сообщений перед фиксацией смещения, этот параметр был выключен.
- timeout.ms — время ожидания сеанса, необходимое потребителю для восстановления после любого сбоя. По умолчанию для клиентов C/C++ и Java установлено значение 10 секунд, но его можно увеличить, чтобы избежать чрезмерной перебалансировки, например из-за плохого сетевого подключения или длительных пауз сборщика мусора. Большой тайм-аут сеанса приведет к тому, что координатору потребуется больше времени, чтобы обнаружить сбой экземпляра-потребителя и другому потребителю в группе также потребуется больше времени, чтобы взять на себя его разделы. Однако для обычных отключений потребитель отправляет координатору явный запрос на выход из группы, что вызывает немедленную перебалансировку.
- interval.ms – время частоты отправки сигнала от потребителя координатору. По нему потребитель определяет, когда необходима перебалансировка, более низкий интервал обычно означает более быструю перебалансировку. По умолчанию этот параметр равен 3 секунды. Для больших групп потребителей целесообразно его увеличить.
Результаты внедрения
Благодаря Kafka платформа пополнения товарных запасов Walmart в реальном времени позволила добиться следующих результатов:
- различные команды теперь имеют контролируемый обзор планов заказов на пополнение для различных уровней всей многоуровневой сети цепочки поставок;
- разработчики могут полагаться на данные непосредственно из производственной среды, используя потребителя для проведения тщательного тестирования, уменьшения количества ошибок и тестовых сценариев;
- команды разработчиков имеют доступ к богатой экосистеме для работы над инновационными технологиями и новыми вариантами использования;
- простота архитектуры достигается на потребительском уровне платформы, поскольку одни и те же данные используются различными потребителями и обрабатываются по-разному в зависимости от их потребностей;
- точность и скорость пополнения товарных запасов остаются высокими за счет того, что циклы планирования приближены ко времени отбора на раздаче, а входные данные поступают в режиме реального времени.
На основании своего опыта инженеры Walmart сформировали пул рекомендаций для розничных продавцов, которые хотят создать сценарии планирования и пополнения запасов в реальном времени:
- убедитесь в наличии конвейеров, которые могут оперативно предоставить доступ к данным;
- если текущая архитектура не может удовлетворить эти потребности, следует преобразовать ее с фокусом на простоту дизайна;
- определитесь с представлением конечного результата, который поможет измерить ценность самой ИТ-платформы;
- разделите сервисы в архитектуре, используя продюсеров и потребителей Kafka.
Больше полезных примеров про администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
[elementor-template id=»13619″]
Источники
- https://www.confluent.io/blog/how-walmart-uses-kafka-for-real-time-omnichannel-replenishment/
- https://docs.confluent.io/platform/current/clients/consumer.htm

