906
906 
Содержание
Практический пример аналитики больших данных в реальном времени с Apache Spark, Kafka, ClickHouse и AWS S3: возможности, архитектура, также специально для дата-инженеров и разработчиков распределенных приложений рассмотрим, сколько времени нужно для разрешения каждого вызова API в определенном временном диапазоне.
Анализ событий пользовательского поведения в реальном времени
Основным продуктом международной ИТ-компании Whatfix является корпоративная SaaS-платформа для создания интерактивных пошаговых руководств для веб-приложений. Apache Spark используется в качестве фреймворка для обработки данных, ClickHouse выступает в роли аналитической платформы, а Kafka является сервисом потоковой передачи событий.
Потоковая архитектура аналитики больших данных обрабатывает их в реальном времени, т.е. по мере их генерации. Например, события пользовательского поведения в веб-приложении: клики, просмотры, наведения курсора на элементы UI/UX и пр. Анализируя эти события, можно сформировать индивидуальную траекторию пользования продуктом для каждого пользователя. Чтобы реализовать это, следует обрабатывать собранные события сразу после их генерации, с минимальной задержкой. Для этого можно построить аналитическую систему с использованием следующих компонентов:
- распределенные задания Apache Spark, который позволяет разделить набор данных по узлам кластера и распараллелить их обработку, гарантируя согласованность и отказоустойчивость;
- топики Apache Kafka для потоковой агрегации сообщений с высокой пропускной способностью и малой задержкой;
- ClickHouse — колоночная СУБД с открытым исходным кодом, которая позволяет создавать аналитические отчеты с помощью SQL-запросов и за счет соответствующего движка поддерживает интеграцию с Apache Kafka, позволяя читать и записывать данные из топиков этой распределенной платформы передачи событий.
- Amazon S3 – облачное объектное хранилище AWS c высокой доступностью и отличной масштабируемостью.
В архитектуре обработки в реальном времени нагрузка на задания Spark постоянна. Установив смещение в 1 КБ в коннекторе Spark-Kafka, задание Spark будет считывать 1 КБ записи за раз из топика Kafka и в любой момент обрабатывать только запись такого размера.
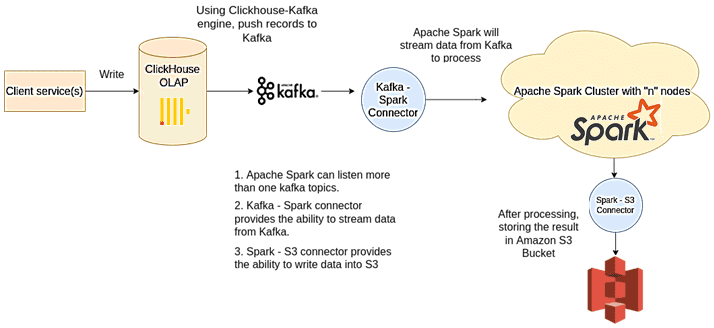
Чтобы проанализировать, какое влияние оказывают API на серверы, необходимо определить, сколько времени в процентах занимает каждый вызов API. Для этого используем следующие данные, которые собираются в ClickHouse из различных сервисов:
- API_ID — уникально идентифицирует конечную точку API, предоставляемую службой.
- Time_taken — сколько времени серверу потребовалось для разрешения API.
В этой архитектуре ClickHouse рассматривается как единственный источник истины, где другие сервисы и компоненты хранят данные. Сам процесс анализа можно представить следующими шагами:
- каждый раз, когда приложения вставляют запись в таблицу ClickHouse, вставленная запись будет помещена в Kafka с помощью движка ClickHouse-Kafka;
- записанные приложениями <api_id, time_taken> в ClickHouse будут отправлены в Kafka для потоковой передачи;
- Apache Spark обрабатывает данные в реальном времени, считывая их из топиков Kafka с помощью коннектора Kafka-Spark;
- по завершении обработки результат сохраняется в корзине AWS
Возвращаясь к цели исследования, напомним, Spark-задание будет вычислять процент времени, затраченный каждым API за определенный период времени. Рассчитанный процент сохраняется как параметр percentage_time в наборе данных. т.е. <api_id, time_taken, percentage_time>
Реализация этой идеи включает не только настройку коннекторов Kafka-Spark и Apache Spark-Amazon S3, а также движка ClickHouse-Kafka. Еще необходимо прослушивать топик Kafka из Apache Spark и сохранить результат в Amazon S3. Рассмотрим некоторые из этих шагов более подробно.
Реализация потоковой архитектуры с Apache Kafka, Spark, ClickHouse и S3
С помощью движка ClickHouse-Kafka мы можем отправлять записи из таблицы ClickHouse в Kafka или наоборот. Например, каждый раз при вставке новой записи в таблицу API с SERVICE_ID = 1, эта вставленная запись должна быть отправлена в распределенную платформу потоковой передачи событий. Для этого нам понадобятся четыре вещи:
- Исходная таблица ClickHouse. Создать API исходной таблицы поможет следующий код:
CREATE TABLE API ( api_id Int32 Codec(DoubleDelta, LZ4), time DateTime Codec(DoubleDelta, LZ4), time_taken DateTime Codec(DoubleDelta, LZ4), Service_id Int32 ) Engine = MergeTree PARTITION BY toYYYYMM(time) ORDER BY (api_id, time);
- Целевой топик Kafka (kafka_topic_1), в которую движок Kafka-ClickHouse отправит записи, удовлетворяющие условию SERVICE_ID = 1:
kafka-topics \ --bootstrap-server kafka:9092 \ --topic kafka_topic_1 \ --create --partitions 6 \ --replication-factor 2
- таблица ClickHouse (kafka_queue), соответствующая созданному топику и созданная следующей командой:
CREATE TABLE kafka_queue ( api_id Int32, time_taken Int32 ) ENGINE = Kafka SETTINGS kafka_broker_list = 'kafka:9092', kafka_topic_list = 'kafka_topic_1', kafka_format = 'CSV', kafka_max_block_size = 1048576;
- материализованное представление (kafka_queue_mv), которое передает строки с service_id = 1 из таблицы API в таблицу kafka_queue:
CREATE MATERIALIZED VIEW kafka_queue_mv TO kafka_queue_mv AS SELECT api_id, time_taken FROM API WHERE service_id = 1
Теперь каждый раз при вставке записи в Clickhouse-таблицу API с service_id = 1, эта запись будет помещена в топик kafka_topic_1. Далее следует прослушивать этот топик из Apache Spark. Чтобы прочитать поток Kafka из задания Apache Spark, потребуется следующая информация:
- домен/IP-адрес сервера Kafka;
- порт, на котором работает сервер Kafka;
- топики Kafka для прослушивания.
Apache Spark может прослушивать несколько топиков из нескольких экземпляров Kafka. Например, приведенный ниже фрагмент кода прослушивает топик «kafka-topic-1» из экземпляра «kafka:9092»:
dataframe = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "kafka:9092")
.option("subscribe", "kafka-topic-1")
.load()
После загрузки следующим шагом будет вычисление процента времени, затрачиваемого API. Это можно сделать, написав несколько строчек на PySpark:
dataframe .withColumn(“percentage_time”, percent_rank().over(windowSpec))
Наконец, нужно записать поток в корзину Amazon S3, т.е. сохранить данные из Apache Spark в корзину Amazon S3. Для этого необходим идентификатор доступа к корзине S3 и секретный ключ, чтобы выполнить аутентификацию в AWS. Возможны два варианта установки идентификатора доступа и секретного ключа:
- сохранить идентификатор доступа и секретный ключ в качестве переменной среды. Этот вариант не считается предпочтительным, поскольку любое отправляемое задание Spark, будет иметь доступ к access_id и secret_key, заданным как переменные среды.
export AWS_SECRET_ACCESS_KEY=XXXXX export AWS_ACCESS_KEY_ID=XXXXX
- установить идентификатор доступа и секретный ключ в объекте SparkContext:
spark.sparkContext._jsc.hadoopConfiguration() .set(“fs.s3a.access.key”, xxxxxxx)spark.sparkContext._jsc.hadoopConfiguration() .set(“fs.s3a.secret.key”, xxxxxxxxxxxxxxxxxxx)
Для схемы S3:// рекомендуется использовать параметры fs.s3.access.key и fs.s3.secret.key.
После установки идентификатора доступа и секретного ключа следует написать код, который фактически сохраняет данные в корзину S3. Запись датафрейма Spark в виде Parquet-файла в корзину S3 аналогична записи в HDFS или в локальную файловую систему:
dataframe
.write
.mode("overwrite")
.parquet("s3a://test.bucket/spark_output)
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
6 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Читайте в нашей следующей статье про опыт сервиса Strava с Apache Spark и AWS S3. А освоить администрирование и эксплуатацию Apache Kafka и Spark для задач дата-инженерии, разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для разработчиков
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
Источники