 765
765 
Мы уже рассказывали про задачи-зомби в Apache AirFlow и способы их устранения. Продолжая тему управления распределенными процессами, сегодня поговорим про задачи, зависшие в очереди и универсальное решение для борьбы с ними, которое будет реализовано в выпуске Apache AirFlow 2.6.0, о других новинках которого читайте здесь.
Жизненный цикл задачи в Apache AirFlow
Задача является элементарной единицей конвейера обработки данных (DAG, Directed Acyclic Graph) в Apache AirFlow. Она имеет свой жизненный цикл, согласно которому ставится в очередь для выполнения на основе их зависимостей и ограничений планирования. В течение своего жизненного цикла состояние задачи меняется от запланированной к поставленной в очередь выполнения. Граф состояний задачи в AirFlow выглядит так:
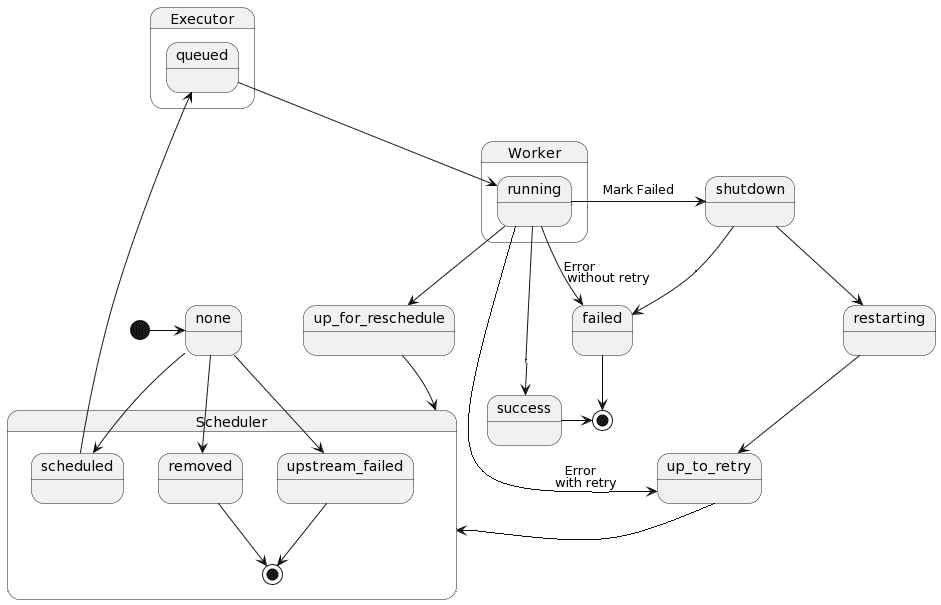
Эта диаграмма создана в PlantUML следующим скриптом:
@startuml
[*] -> none
state Scheduler {
none --> scheduled
none --> removed
removed --> [*]
upstream_failed --> [*]
none --> upstream_failed
}
state Executor {
scheduled -> queued
}
state Worker {
queued --> running
}
running --> up_for_reschedule
up_for_reschedule --> Scheduler
running ---> success
running --> shutdown : Mark Failed
shutdown --> failed
failed --> [*]
running -> failed : Error without retry
running -> up_to_retry : Error with retry
up_to_retry -> Scheduler
shutdown --> restarting
restarting --> up_to_retry
success -> [*]
@enduml
Состояния задачи в Apache AirFlow могут быть следующими:
- none – задача еще не поставлена в очередь на выполнение, ее зависимости еще не выполнены;
- scheduled — планировщик определил, что зависимости задачи выполнены, и она должна быть запущена;
- queued — задача назначена исполнителю и ожидает worker’а;
- running — задача выполняется на worker’е или на локальном/синхронном исполнителе;
- success — задача завершена без ошибок
- shutdown — задача была запрошена извне на завершение работы во время ее выполнения;
- restarting — задача была запрошена извне для перезапуска во время ее выполнения;
- failed — во время выполнения задачи произошла ошибка, и ее не удалось запустить;
- skipped — задача была пропущена из-за ветвления, LatestOnly или аналогичного;
- upstream_failed – не удалось выполнить восходящую задачу, которая нужна согласно правилу триггера;
- up_for_retry – задача не удалась, но остались попытки повторной попытки, и она будет перепланирована;
- up_for_reschedule – задача представляет собой сенсор (особый тип оператора), находящийся в режиме перепланирования;
- deferred – задача была отложена до триггера;
- removed — задача удалена из DAG с момента запуска.
Очереди задач
Согласно жизненному циклу задачи в Apache AirFlow сперва планировщик определяет, что пришло время запуска задачи и других зависимостей, включая завершение вышестоящих задач. В это время задача переходит в состояние «запланирована» (scheduled). Когда задача назначается исполнителю, она переходит в состояние очереди (queued). Когда исполнитель, наконец, берет задачу и worker начинает выполнять ее, задача переходит в состояние выполнения (running). Иногда задачи зависают в очереди. Это может быть преднамеренным, например, достигнут параллелизм, или непреднамеренным, когда что-то выходит из строя между исполнителем и планировщиком.
Самый простой способ увидеть это — использовать диаграмму Ганта в GUI AirFlow.
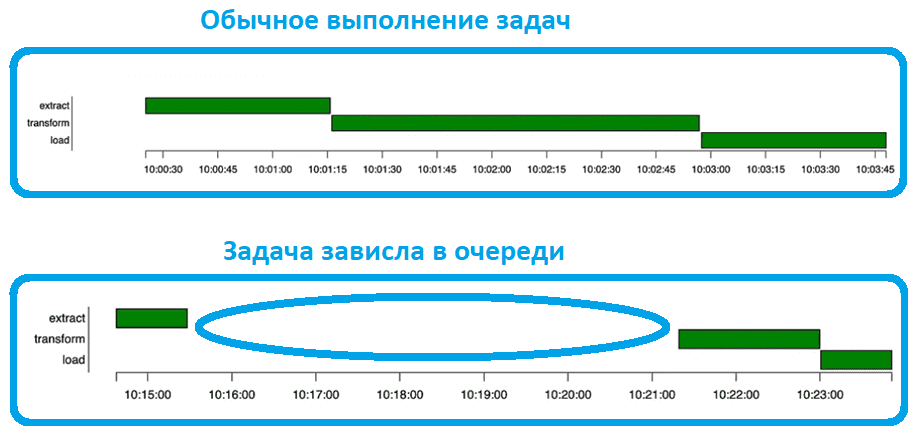
При использовании исполнителя Celery (CeleryExecutor), о котором мы писали здесь, задачи зависали в очереди довольно часто, несмотря на параметр конфигурации AIRFLOW__CELERY__STALLED_TASK_TIMEOUT. Этот параметр означает время в секундах, по истечении которого задачи, поставленные в очередь Celery, считаются остановленными и автоматически перепланируются. Вместо этого с версии AirFlow 2.3.1 принятые задачи используют параметр task_adoption_timeout, если он указан. При нулевом значении этого параметра автоматическая очистка зависших задач отключена.
Хотя конфигурации stalled_task_timeout и task_adoption_timeout устраняли большинство проблем с задачами, застрявшими в очереди, некоторые из них все равно оставались в состоянии очереди в течение нескольких часов, до завершения работы текущего планировщика задачи, и другой планировщик не мог принять такие зависшие задачи.
Чтобы устранить эту ситуацию, дата-инженеры компании Astronomer, коммерциализирующей Apache AirFlow, написали запрос в базу данных для получения задач, зависших в очереди:
SELECT dag_id, run_id, task_id, queued_dttm FROM task_instance WHERE queued_dttm < current_timestamp - interval '30 minutes' AND state = 'queued'
Оказалось, что это простой и логичный способ обнаружения застрявших задач в очереди, поскольку запрашивать базу данных AirFlow из планировщика гораздо удобнее, чем пытаться реализовать индивидуальную логику для каждого исполнителя. Поэтому в будущих релизах AirFlow ожидается следующее решение задач, застрявшие в очереди:
- запросить в базе данных задачи, которые находились в очереди дольше, чем время, заданное параметром конфигурации task_queued_timeout;
- отправить любые такие задачи исполнителю для обработки;
Это решение поддерживается только для удаленных исполнителей CeleryExecutor и KubernetesExecutor, т.к. лишь они поддерживают данный параметр конфигурации (scheduler.task_queued_timeout). Для унификации этого решения в Apache AirFlow 2.6.0 реализован единый механизм обнаружения и обработки зависших задач в очереди независимо от используемого исполнителя, а параметры kubernetes.worker_pods_pending_timeout, celery.stalled_task_timeout и celery.task_adoption_timeout будут объединены в единую конфигурацию scheduler.task_queued_timeout. Читайте в нашей новой статье, как настроить приоритет задач в очереди исполнителя.
Освойте все возможности Apache AirFlow для дата-инженерии и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

