 1090
1090 
Продолжаем говорить о NLP в PySpark. После того как тексты обработаны: удалены стоп-слова и проведена лемматизация — их следует векторизовать для последующей передачи алгоритмам Machine Learning. Сегодня мы расскажем о 3-x методах векторизации текстов в PySpark. Читайте в этой статье: применение CountVectorizer для подсчета встречаемости слов, уточнение важности слов с помощью TF-IDF, а также обучение Word2Vec для создания векторных представлений слов.
CountVectorizer: считаем количество слов
CountVectorizer считает встречаемость слов в документе. Под документом может подразумеваться предложение, абзац, пост или комментарий. Результатом применения CountVectorizer являются разреженные вектора (sparse vectors), причём значения сортированы согласно частоте встречаемости слова. У него есть аргумент vocabSize, значение которого устанавливает максимальный размер словаря, по умолчанию он равен 262144. Ниже пример данной векторизации в PySpark, где во 2-м документе некоторые слов повторяются по несколько раз. В результате, в созданном столбце (features) каждая запись имеет:
-
Размер словаря,
-
Номера присутствующих слов в документе,
-
Вектор встречаемости слов.
from pyspark.ml.feature import CountVectorizer
df = spark.createDataFrame([
(0, ['Py', 'Do', 'Fa']),
(1, ["Py", "Do", "Do", "Fa", "Py"])
], ["id", "words"])
# fit a CountVectorizerModel from the corpus.
cv = CountVectorizer(inputCol="words", outputCol="features")
model = cv.fit(df)
result = model.transform(df)
result.show(truncate=False)
#
+---+--------------------+-------------------------+
|id |words |features |
+---+--------------------+-------------------------+
|0 |[Py, Do, Fa] |(5,[0,1,2],[1.0,1.0,1.0])|
|1 |[Py, Do, Do, Fa, Py]|(5,[0,1,2],[2.0,2.0,1.0])|
|3 |[Bl, Ch, Bl] |(5,[3,4],[2.0,1.0]) |
+---+--------------------+-------------------------+
Взглянем на размер словаря и содержимое векторизованного признака:
>>> model.getVocabSize()
262144
>>> result.select('features').collect()
[Row(features=SparseVector(5, {0: 1.0, 1: 1.0, 2: 1.0})),
Row(features=SparseVector(5, {0: 2.0, 1: 2.0, 2: 1.0})),
Row(features=SparseVector(5, {3: 2.0, 4: 1.0}))]
TF-IDF: учитываем важность слова
TF-IDF — это метод векторизации признаков, широко используемый при анализе текстов. TF-IDF помогает отразить важность слова как в документе, так и во всём корпусе. Корпус — совокупность всех документов. TF-IDF состоит из двух компонент: Term Frequency (TF, частота слова) и Inverse Document Frequency (IDF, обратная частота документа). TF считается как отношение встречаемости слов к общему числу слов в документе. Часть IDF считается для каждого слова в словаре, а не в документе:
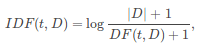
D — количество документов в корпусе, а DF(t, D) — количество документов, в которых встречается слово. Так, если слово встречается во всех документах, то IDF = 0. В итоге,
TF-IDF = IDF * TF
В отличие от Python-библиотеки Scikit-learn, в PySpark TF и IDF считаются по отдельности.
TF может быть посчитана через CountVectorizer или HashingTF. Последний — это тот же самый CountVectorizer, только индексы значений хранятся в хэш-кодах, которые вычисляются через алгоритм MurmurHash3 [1]. Фактически HashingTF быстрее, чем CountVectorizer.
Для IDF есть собственный класс (он так и называется IDF). Применение метода fit над датасетом возвращает объект IDFModel, в который нужно передать результат TF (HashingTF или CountVectorizer).
Ниже пример векторизации в PySpark с использованием TF-IDF. Сначала документы передаются в HashingTF, а затем над результатом применяется IDF.
from pyspark.ml.feature import HashingTF, IDF, Tokenizer
df = spark.createDataFrame([
(0.0, ["привет", "я", "слышал", "о", "векторизации", "pyspark"]),
(0.0, ["привет", "как", "дела"]),
(1.0, ["привет", "я", "слышал", "о", "pyspark"])
], ["label", "words"])
hashingTF = HashingTF(inputCol="words", outputCol="rawFeatures", numFeatures=20)
featurizedData = hashingTF.transform(df)
idf = IDF(inputCol="rawFeatures", outputCol="features")
idfModel = idf.fit(featurizedData)
rescaledData = idfModel.transform(featurizedData)
rescaledData.select("label", "features").show(truncate=False)
+-----+-----------------------------------------------+
|label|features |
+-----+-----------------------------------------------+
|0.0 |(20,[1,5,9,14,15],[0.287,0.0,0.0,0.2876,0.287])|
|0.0 |(20,[5,9,14],[0.0,0.0,0.287]) |
|1.0 |(20,[1,5,9,15],[0.287,0.0,0.0,0.287]) |
+-----+-----------------------------------------------+
Word2Vec: обучаем векторные представления
Word2Vec вычисляет распределенное векторное представление слов. Основное преимущество распределенных представлений заключается в том, что похожие слова имеют схожие векторные представления. В отличие от предыдущих методов векторизации, Word2Vec является алгоритмом машинного обучения. Векторное представление — один из самых эффективных методов векторизации в NLP, и используется для таких задач, как распознавание именованных сущностей, устранение неоднозначности, синтаксический анализ и машинный перевод.
Векторизация Word2Vec в PySpark очень проста и требует нескольких строчек кода. Ниже приведён пример создания модели в Python. В аргументах мы также указали
-
vectorSize — длина векторного представления (по умолчанию 100);
-
minCount— минимальное число встречаемости слова, чтобы включить его в словарь модели Word2Vec (по умолчанию 5). Это поможет избавиться от редких слов, которые встречаются в корпусе меньше, чемminCount.
from pyspark.ml.feature import Word2Vec
df = spark.createDataFrame([
(0.0, ["привет", "я", "слышал", "о", "векторизации", "pyspark"]),
(0.0, ["привет", "как", "дела"]),
(1.0, ["привет", "я", "слышал", "о", "pyspark"])
], ["label", "words"])
word2Vec = Word2Vec(vectorSize=3, minCount=0, inputCol="words", outputCol="result")
model = word2Vec.fit(df)
result = model.transform(df)
for row in result.collect():
id, text, vector = row
print("Text: [%s] => \nVector: %s\n" % (", ".join(text), str(vector)))
Результат вывода на экран:
Text: [привет, я, слышал, о, векторизации, pyspark] => Vector: [0.016005517294009525,-0.02526436559855938,-0.04664420709013939] Text: [привет, как, дела] => Vector: [0.005714414796481529,-0.07555764478941758,0.0034225229173898697] Text: [привет, я, слышал, о, pyspark] => Vector: [0.004389378428459168,-0.031204423680901528,-0.08815652877092361]
На основе обученной модели мы можем посмотреть синонимы к слову. Здесь можно использовать метод findSynonyms, который вернёт DataFrame, или метод findSynonymsArray, который вернёт список (list):
>>> model.findSynonyms('привет', 2).show()
+------------+-------------------+
| word| similarity|
+------------+-------------------+
|векторизации| 0.7366906404495239|
| слышал|0.43934717774391174|
+------------+-------------------+
>>> model.findSynonymsArray('привет', 3)
[('векторизации', 0.7366906404495239),
('слышал', 0.43934717774391174),
('как', 0.07174655050039291)]
Поскольку модель обучена на 3 предложениях, то ожидать чуда не придётся. Другое дело, если бы мы обучили Word2Vec на реальных примерах, например, обработанных новостях на русском языке, о которых говорили в прошлой статье, то получили бы совсем другие результаты.
О методах векторизации текстов в в PySpark для решения реальных задач NLP вы узнаете на специализированном курсе «PNLP: NLP – обработка естественного языка с Python» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.
Источники

