
Чем метод applyInPandas() в Spark отличается от apply() в pandas и насколько он быстрее обрабатывает данные: сравнительный тест на датафрейме из 5 миллионов строк. Методы применения пользовательских функций к датафреймам в Spark и pandas Мы уже отмечали здесь и здесь, что Apache Spark позволяет работать с популярной Python-библиотекой pandas, поддерживая...
Как добавить пользовательский код в Apache AirFlow и где его хранить: лучшие практики и рекомендации для дата-инженера с примером создания и импорта своего пакета. Как хранить общий код в AirFlow Недавно мы писали про сложности управления DAG в многопользовательской среде Apache AirFlow. Однако, даже когда речь идет про однопользовательскую работу...
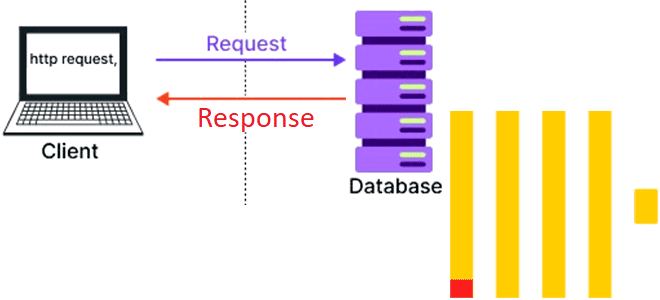
Как реализовать систему с двухзвенной архитектурой на ClickHouse и браузере. Возможности колоночной СУБД для создания одностраничных веб-приложений. Возможности ClickHouse для одностраничных веб-приложений Хотя трехзвенная архитектура (клиент -> бэк-> база данных) уже давно стала стандартом де-факто в разработке веб-приложений, двухзвенная архитектура, когда бизнес-логика переносится в базу данных, до сих пор встречается....
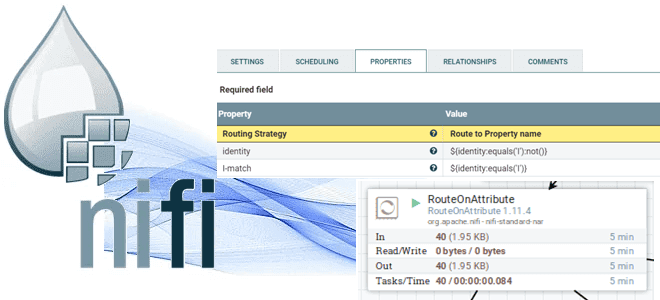
Что такое атрибуты FlowFile, какие процессоры есть в Apache NiFi для работы с ними и как маршрутизировать поток данных на основе пользовательских свойств. Атрибуты FlowFile и процессоры для работы с ними Основной единицей данных, которая перемещается через систему в Apache NiFi является FlowFile. Он представляет собой контейнер для данных и...
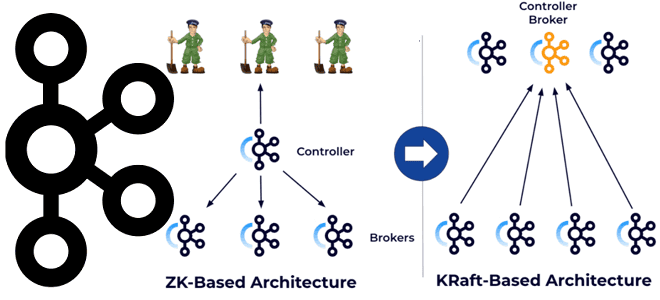
Как перевести кластер Kafka с ZooKeeper на KRaft, чтобы обеспечить управление метаданными с помощью этого протокола консенсуса: последовательность действий и настройки конфигураций. Зачем и как переводить Apache Kafka с Zookeeper на KRaft Напомним, протокол KRaft, который заменяет ZooKeeper для управления метаданными и консенсуса кластера Kafka, был введен еще в версии...

Зачем в Apache Flink 1.20 добавлена новая функция восстановления пакетных заданий после сбоя JobMaster, как она работает и какие параметры надо настроить для повышения ее эффективности. Восстановление пакетных заданий Flink после сбоя JobMaster Как и любой фреймворк стека Big Data, Apache Flink включает множество компонентов, каждый из которых выполняет конкретную...
Что такое Chdb, зачем нужна эта библиотека и как ее использовать в коде Python-приложения для анализа больших данных в ClickHouse без разворачивания полноценного сервера этой колоночной СУБД. Как и зачем работать с ClickHouse без сервера СУБД ClickHouse является мощным инструментом аналитики больших данных, который требует соответствующей инфраструктуры. Однако, иногда нужно...
Что такое волатильные функции, зачем они нужны и чем опасны: разбираем на примере Greenplum и PostgreSQL. К чему приведет некорректное использование атрибутов изменчивости в SQL-запросе или UDF-функции распределенной MPP-СУБД. Что такое волатильность функции и почему это важно для Greenplum Волатильной или изменчивой считается функция, значение которой может изменяться даже в...

Зачем включать ротацию лог-файлов потоковых приложений Apache Spark, какие конфигурации помогут ее настроить и для чего сжимать файлы журналов в длительных заданиях. Чем полезна ротация лог-файлов Spark-приложений и как ее настроить Об общих принципах логирования системных событий в приложениях Apache Spark мы уже рассказывали здесь. В этой статье подробнее разберем...

Что не так с работой Apache AirFlow в многопользовательской среде, зачем предоставлять каждой команде свое развертывание ETL-фреймворка, каковы недостатки этого решения и как организовать мультитенантный кластер. Почему Apache Airflow не предназначен для многопользовательского использования В современной дата-инженерии Apache AirFlow стал наиболее популярным инструментом для пакетных ETL-процессов. Чтобы использовать его наиболее...

Чем объектное хранилище данных отличается от классической файловой системы POSIX, как это влияет на разработку Spark-приложений, почему операция переименования снижает производительность облачных вычислений и что поможет ее избежать. Еще раз об отличиях объектных и файловых хранилищ и как это влияет на приложения Spark Будучи компонентом экосистемы Apache Hadoop, фреймворк Spark...
Что такое хранилище признаков, зачем это нужно в машинном обучении, каковы его главные компоненты и как использовать ClickHouse в качестве Feature Store для ML-задач. Хранилище признаков для машинного обучения: архитектура и принципы работы Feature Store Будучи колоночной базой данных, ClickHouse отлично подходит на роль хранилища фичей (Feature Store) для задач...
Что такое дополнительный выходной поток DataStream в Apache Flink, зачем это нужно, чем механизм SideOutput лучше операторов filter и split, а также как его использовать: примеры на Python. Что такое дополнительный выходной поток DataStream в Apache Flink и зачем это нужно Хотя выходные результаты большинства операторов API DataStream в Apache...
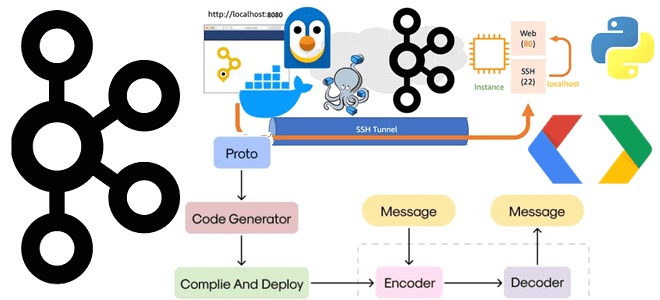
Как публиковать в топик Kafka сообщения в формате Protobuf, используя реестр схем и библиотеку confluent-kafka. Пример Python-продюсера, конфигурационного YAML-файла для Docker-развертывания Kafka Confluent и тунелирование портов локального компьютера. Подготовка инфраструктуры и определение схемы данных Чтобы публиковать в свое Docker-развертывание Kafka Confluent данные, используя реестр схем, нужно сперва внести изменения в...
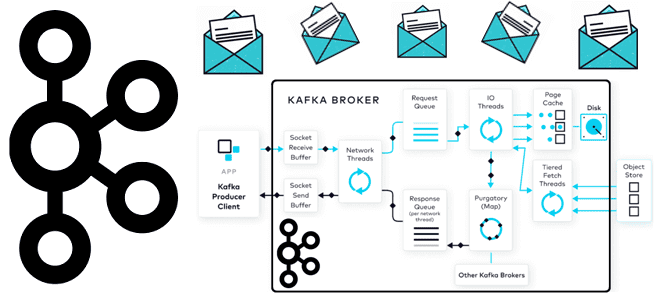
Как данные попадают в топик Kafka: полный путь пакета сообщений от буфера сокета приема до страничного кэша и отправки ответного подтверждения клиенту- продюсеру. Все шаги публикации данных в Apache Kafka Когда разработчик пишет код приложения-продюсера, публикующего данные в Apache Kafka, он использует существующие методы для отправки сообщений, которые есть в...

24 сентября вышел очередной релиз Apache Spark. Он не содержит новых фичей, но зато в нем есть несколько полезных оптимизаций и исправлений безопасности. Читайте далее о самом главном из них, связанном с утечкой токена делегирования Hadoop. Зачем нужны токены делегирования Hadoop в Spark и как они работают В выпуске Apache...

Как устроен планировщик заданий Apache AirFlow, от чего зависит его производительность и какие конфигурации помогут ее улучшить: настройки, приемы, рекомендуемые значения и лучшие практики. Как работает планировщик Apache AirFlow Apache AirFlow как фреймворк оркестрации пакетных процессов включает несколько компонентов. Одним из них является планировщик (scheduler), который отслеживает все задачи и...
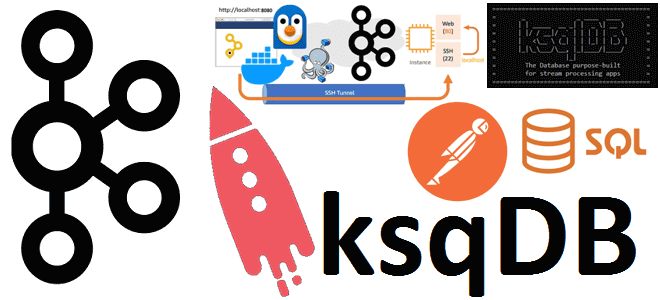
Аналитика данных из топиков Kafka с помощью SQL-запросов: обращение к ksqlDB в Docker через CLI-интерфейс и REST API в Postman с SSH-тунелированием сервера потоковой базы данных. Практическое руководство с примерами и иллюстрациями. CLI-интерфейс ksqldb Docker-образ Confluent Kafka включает дополнительные компоненты этой платформы: ksqlDB, Kafka Connect, REST Proxy, Schema Registry). Сегодня...
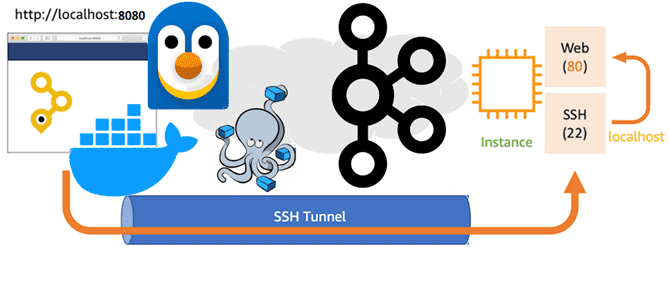
Как туннелировать порты Docker-контейнеров для доступа к Kafka на WSL в Windows с внешнего клиента: переадресация HTTP- и TCP-соединений с помощью SSH-сервера serveo. Поиск средства тунелирования и настройка портов Собственное развертывание платформы Kafka от Confluent в виде набора связанных Docker-контейнеров в WSL на Windows с GUI-интерфейсом AKHQ, о чем я...
Как настроить YAML-файл Docker Compose для доступа к Kafka на WSL в Windows: открытие портов в конфигурации развертывания с примерами (продолжение). Настройка конфигурационного YAML-файла для запуска Docker-контейнеров с компонентами Kafka на Windows в WSL Как я рассказывала вчера, для работы с компонентами платформы Kafka от Confluent, развернутой как набор связанных...