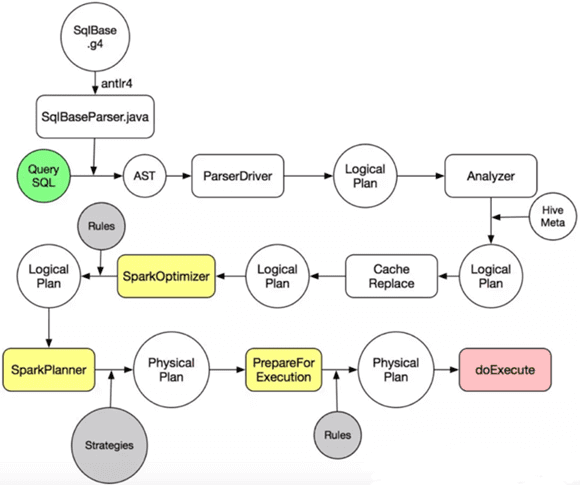
Продолжая разговор про SQL-оптимизацию в Apache Spark, сегодня мы рассмотрим, что такое дерево запросов и как оптимизатор Catalyst преобразует его в исполняемый байт-код при аналитической обработке Big Data в рамках Спарк. Деревья структурированных запросов и правила управления ими в Apache Spark Отметим, что деревья запросов отличаются от алгебраических деревьев операций тем, что...
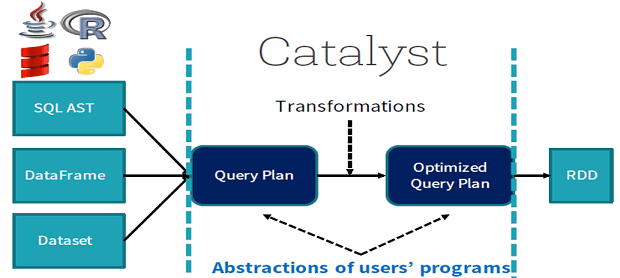
Мы уже немного рассказывали об SQL-оптимизации в Apache Spark. Продолжая эту тему, сегодня рассмотрим подробнее, что такое Catalyst – встроенный оптимизатор структурированных запросов в Spark SQL, а также поговорим про базовые понятия SQL-оптимизации. Читайте в нашей статье о логической и физической оптимизации, плане выполнения запросов и зачем эти концепции нужны...
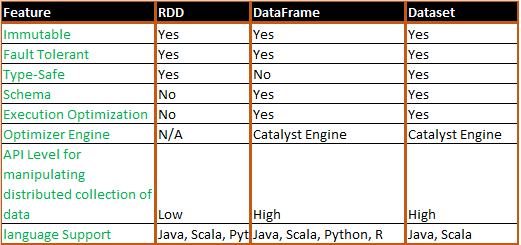
Завершая сравнение структур данных Apache Spark, сегодня мы рассмотрим, в каких случаях разработчику Big Data стоит выбирать датафрейм (DataFrame), датасет (DataSet) или RDD и почему. Также мы приведем практический примеры и сценарии использования (use cases) этих программных абстракций, важных при разработке систем и сервисов по интерактивной аналитике больших данных с...
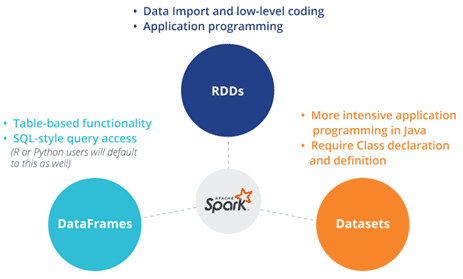
Продолжая говорить о сходствах и отличиях структур данных Apache Spark, сегодня мы рассмотрим, чем похожи датафрейм (DataFrame), датасет (DataSet) и RDD с позиции разработчика Big Data. Читайте в нашей статье, как обеспечивается оптимизация кода, безопасность типов при компиляции и прочие аспекты, важные при разработке распределенных программ и интерактивной аналитике больших...
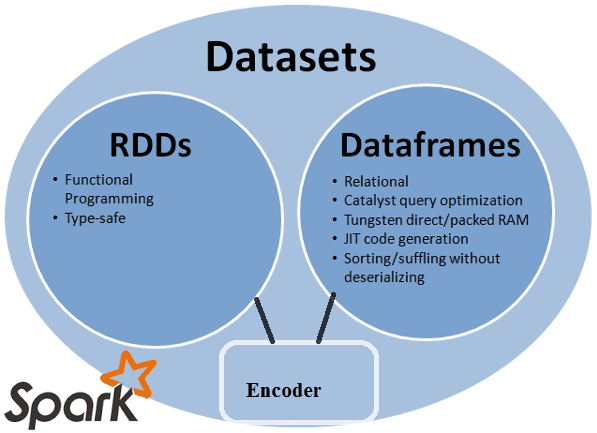
В прошлый раз мы рассмотрели понятия датафрейм (DataFrame), датасет (DataSet) и RDD в контексте интерактивной аналитики больших данных (Big Data) с помощью Spark SQL. Сегодня поговорим подробнее, чем отличаются эти структуры данных, сравнив их по разным характеристикам: от времени возникновения до специфики вычислений. Критерии сравнения структур данных Apache Spark Прежде...
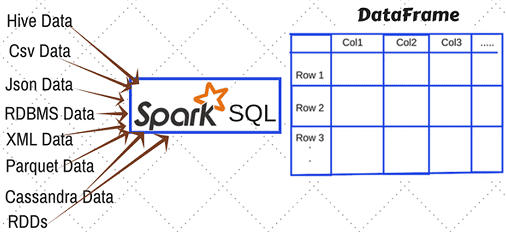
Этой статьей мы открываем цикл публикаций по аналитике больших данных (Big Data) с помощью SQL-инструментов: Apache Impala, Spark SQL, KSQL, Drill, Phoenix и других средств работы с реляционными базами данных и нереляционными хранилищами информации. Начнем со Spark SQL: сегодня мы рассмотрим, какие структуры данных можно анализировать с его помощью и...

Завершая разговор про ETL-инструменты Big Data и цикл статей об Apache NiFi (ANF), сегодня мы сравним его со StreamSets Data Collector (SDC): чем похожи и чем отличаются эти системы маршрутизации данных. Также рассмотрим, в каких случаях следует выбирать ту или иную платформу и почему. Что общего между Apache NiFi и...
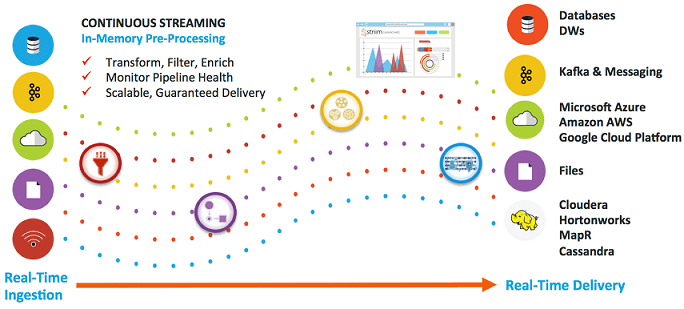
Рассмотрев пакетные ETL-инструменты больших данных, сегодня мы поговорим про потоковые средства загрузки и маршрутизации информации из различных источников: Apache NiFi, Fluentd и StreamSets Data Collector. Читайте в нашей статье про их сходства, различия, достоинства и недостатки. Также мы собрали для вас реальные примеры их практического использования в Big Data системах...
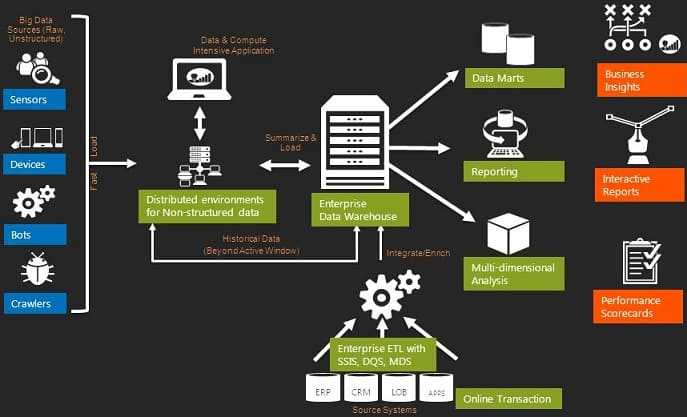
Продолжая разговор про Apache NiFi и другие ETL-инструменты больших данных, сегодня мы подробнее расскажем про пакетные средства загрузки и маршрутизации информации из различных источников: Sqoop, Chuckwa и Falcon. Читайте в нашей статье, чем они похожи и чем отличаются, а также как применяются в Big Data системах и интернете вещей (Internet...
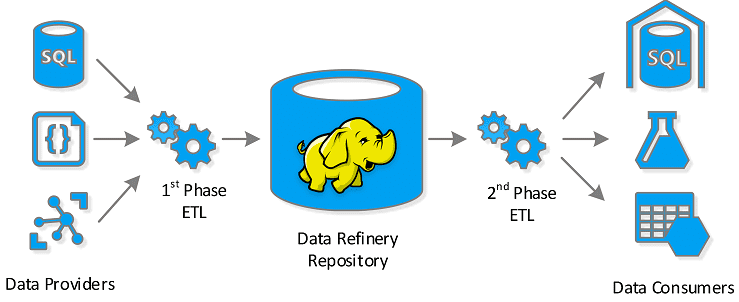
Несмотря на очевидные достоинства Apache NiFi, этой Big Data платформе быстрой загрузке и маршрутизации данных, активно применяемой в интернете вещей (Internet of Things, IoT), в т.ч. индустриальном (Industrial Iot, IIoT), также свойственны и некоторые недостатки. Сегодня мы поговорим об альтернативах Apache NiFi: Flume, Sqoop, Chuckwa, Gobblin, Falcon, а также Fluentd...
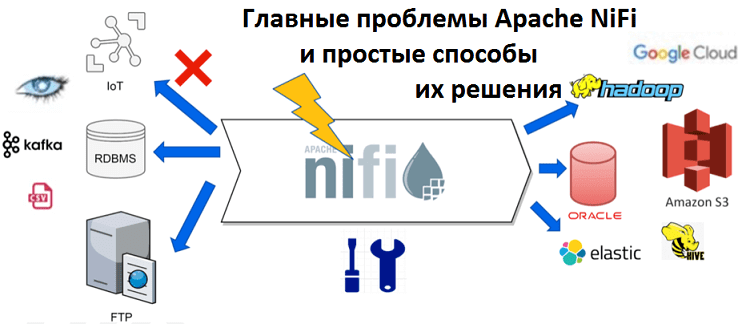
Популярность Apache NiFi в Big Data системах и интернете вещей (Internet of Things, IoT), в т.ч. индустриальном (Industrial Iot, IIoT), обусловлена широкими функциональными возможностями этой платформы по быстрой загрузке и маршрутизации данных любого формата между множеством источников и приемников информации. Также среди ключевых преимуществ NiFi отмечается распределенная архитектура, масштабируемость, наличие...
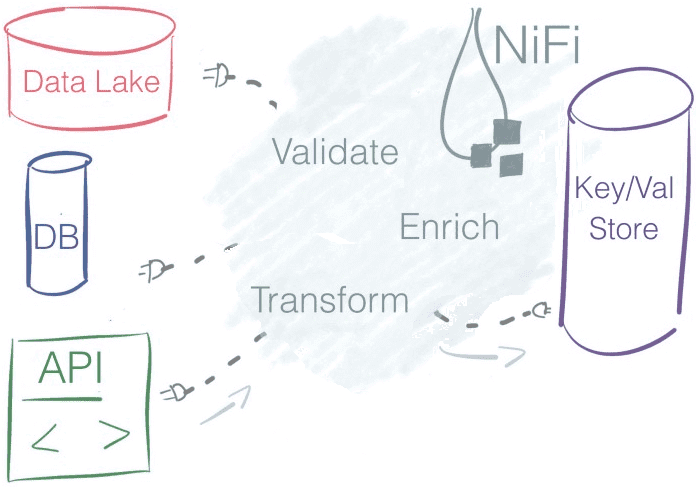
Продолжая разговор про практическое использование Apache NiFi в системах больших данных (Big Data) и интернета вещей (Internet of Things), сегодня мы рассмотрим, чем обусловлена популярность этой кластерной платформы маршрутизации, преобразования и доставки распределенной информации. Читайте в нашей статье про ключевые преимущества Apache NiFi в контексте прикладного использования этого инструмента. 10...

В прошлый раз мы рассмотрели пример прототипа IIoT-системы на основе одноплатного мини-компьютера Raspberry Pi, брокере обмена сообщениями Mosquitto и платформе маршрутизации данных Apache NiFi. Сегодня мы покажем, что этот инструмент преобразования и доставки данных из множества сторонних систем может применяться не только в IoT-решениях. Читайте в нашей статье про 5...

Мы уже рассказывали о многоуровневой системе промышленного интернета вещей и ее smart-компонентах, обеспечивающих первичную обработку и оперативную передачу технологических данных с конечных устройств в интеллектуальные сервисы IoT-платформы. Сегодня рассмотрим прототип такой IIoT-системы, построенной с использованием Big Data средств ETL-обработки информационных потоков – Apache NiFi и MiniFi, а также поговорим о...

Детализируя глобальные проблемы развития отечественного Industrial Internet of Things (IIoT), сегодня мы поговорим о технических аспектах построения комплексной Big Data и IIoT-системы, а также рассмотрим сложности интеграции реального производства с аналитикой больших данных и искусственным интеллектом на примере практических кейсов. Зачем нужна интеграция АСУТП и Big Data и при чем...
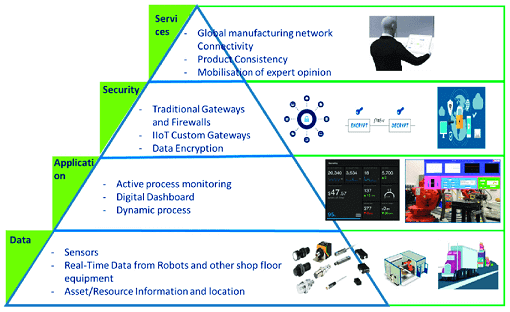
Мы уже рассматривали типовую архитектуру систем Internet of Things (IoT). Сегодня поговорим подробнее про уровневую модель передачи и обработки данных от конечных устройств до облачных IoT-платформ, а также приведем примеры наиболее популярных средств обеспечения каждого из уровней этой сложной архитектуры Industrial Internet of Things, включая инструменты Big Data. Многоуровневый IIoT:...
Рассмотрев основные причины задержки активного развития отечественного рынка промышленного интернета вещей (Industrial Internet of Things, IIoT), сегодня мы отметим наиболее значимые факторы роста IIoT-внедрений в России, а также поговорим про тренды этой технологии Industry 4.0, характерные для нашей страны. 7 главных факторов роста отечественного IIoT-рынка Несмотря на то, что доля...

В предыдущей статье мы анализировали текущее состояние промышленного интернета вещей (Industrial Internet of Things, IIoT) на отечественном рынке и рассматривали наиболее перспективные направления развития этого технологического стека. Сегодня мы поговорим про специфические для нашей страны проблемы, которые сдерживают наступление 4-ой промышленной революции (Industry 4.0, I4.0) в России. Основные причины задержки...
Продолжая разговор про мировые тренды развития промышленного интернета вещей (Industrial Internet of Things, IIoT), сегодня мы рассмотрим перспективы отечественного IIoT, а также проанализируем текущее развитие Big Data, Machine Learning и других ключевых технологий 4-ой промышленной революции (Industry 4.0, I4.0) в России. Промышленный интернет вещей в России: 3 главные перспективы Прежде...

В этой статье мы расскажем о 4-ой промышленной революции и прорывных технологиях, показанных на крупнейшей промышленной выставке Hannover Messe-2019: что такое коботы, цифровые близнецы и CMMS-системы, а также как все это связано с Big Data и Industrial Internet of Things. 4-я промышленная революция: что это такое и как она связана...