
Озеро данных (Data Lake) на Apache Hadoop HDFS в мире Big Data стало фактически стандартом де-факто для хранения полуструктурированной и неструктурированной информации с целью последующего использования в задачах Data Science. Однако, недостатком этой архитектуры является низкая скорость вычислительных операций в HDFS: классический Hadoop MapReduce работает медленнее, чем аналоги на Apache...

В прошлый раз мы говорили о том, как установить PySpark в Google Colab, а также скачали датасет с помощью Kaggle API. Сегодня на примере этого датасета покажем, как применять операции SQL в PySpark в рамках анализа Big Data. Читайте далее про вывод статистической информации, фильтрацию, группировку и агрегирование больших данных...
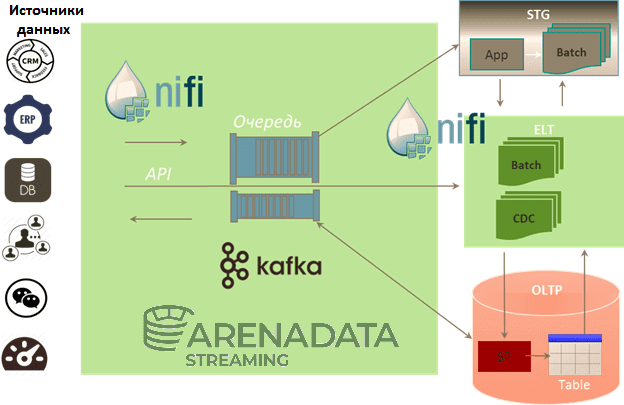
Мы уже рассказывали про преимущества совместного использования Apache Kafka и NiFi. Сегодня рассмотрим, как эти две популярные технологии потоковой обработки больших данных (Big Data) сочетаются в рамках единого решения от отечественного разработчика - Arenadata Streaming. Читайте далее про основные сценарии использования и ключевые достоинства этого современного продукта класса Event Stream...
Завершая цикл статей про MLOps, сегодня мы расскажем про 5 шаблонов практического внедрения моделей Machine Learning в промышленную эксплуатацию (production). Читайте далее, что такое Model-as-Service, чем это отличается от гибридного обслуживания и еще 3-х вариантов интеграции машинного обучения в production-системы аналитики больших данных (Big Data), а также при чем тут...
Рассказав, как оценить уровень зрелости Machine Learning Operations по модели Google или методике GigaOm, сегодня мы поговорим про этапы и особенности практического внедрения MLOps в корпоративные процессы. Читайте далее, какие организационные мероприятия и технические средства необходимы для непрерывного управления жизненным циклом машинного обучения в промышленной эксплуатации (production). 2 направления для...
Недавно мы рассказывали про модель зрелости MLOps от Google. Сегодня рассмотрим альтернативную методику оценки зрелости операций разработки и эксплуатации машинного обучения, которая больше похоже на наиболее популярную в области управленческого консалтинга модель CMMI, часто используемую в проектах цифровизации. Читайте далее, по каким критериям измеряется Machine Learning Operations Maturity Model и...
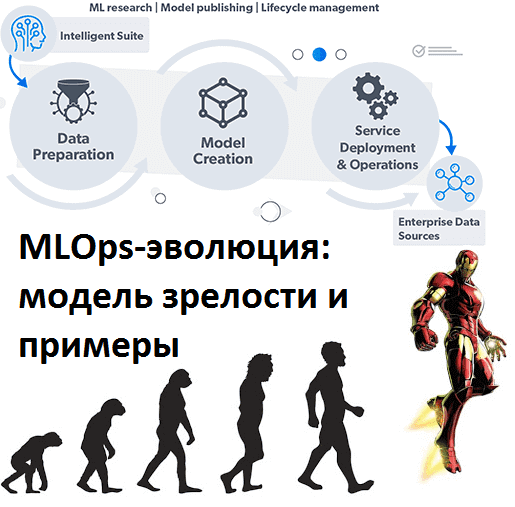
Цифровизация и запуск проектов Big Data предполагают некоторый уровень управленческой зрелости бизнеса, который обычно оценивается по модели CMMI. MLOps также требует предварительной готовности предприятия к базовым ценностям этой концепции. Читайте в нашей статье, что такое Machine Learning Operations Maturity Model – модель зрелости операций разработки и эксплуатации машинного обучения, из...
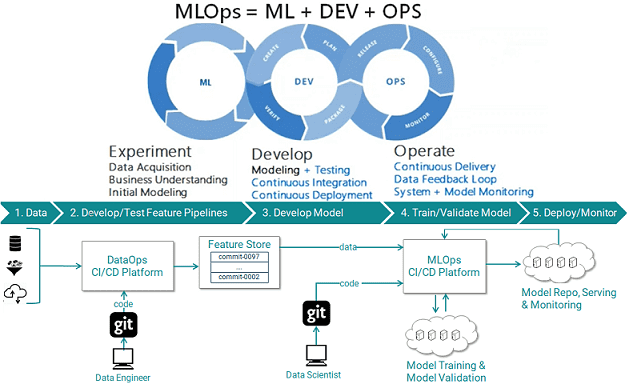
Пока цифровизация воплощает в жизнь концепцию DataOps, мир Big Data вводит новую парадигму – MLOps. Читайте в нашей статье, что такое MLOps, зачем это нужно бизнесу и какие специалисты потребуются при внедрении практик и инструментов сопровождения всех операций жизненного цикла моделей машинного обучения (Machine Learning Operations). Что такое MLOps, почему...
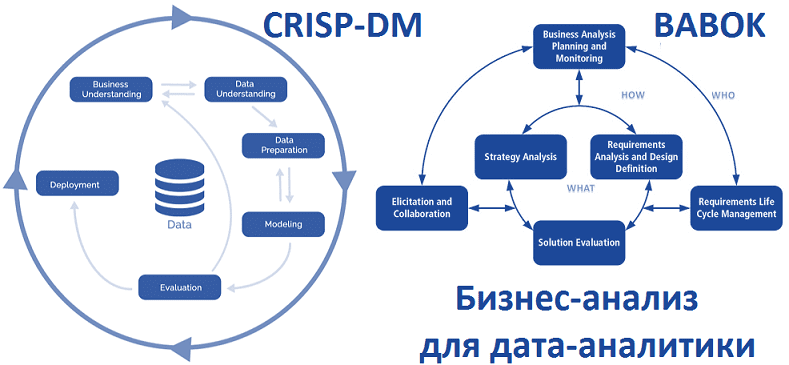
Мы уже рассказывали, что цифровизация и другие масштабные проекты внедрения технологий Big Data должны обязательно сопровождаться процедурами бизнес-анализа, начиная от выявления требований на старте до оценки эффективности уже эксплуатируемого решения. Сегодня рассмотрим, как задачи бизнес-анализа из руководства BABOK®Guide коррелируют с этапами методологии исследования данных CRISP-DM, которая считается стандартом де-факто в...

Самообслуживаемая аналитика больших данных – один из главных трендов в современном мире Big Data, который дополнительно стимулирует цифровизация. В продолжение темы про self-service Data Science и BI-системы, сегодня мы рассмотрим, что такое Cloudera Data Science Workbench и чем это зарубежный продукт отличается от отечественного Arenadata Analytic Workspace на базе Apache...

Продолжая разговор про Apache Zeppelin, сегодня рассмотрим, как на его основе ведущий разработчик отечественных Big Data решений, компания «Аренадата Софтвер», построила самообслуживаемый сервис (self-service) Data Science и BI-аналитики – Arenadata Analytic Workspace. Читайте далее, как развернуть «с нуля» рабочее место дата-аналитика, где место этого программного решения в конвейере DataOps и при...
Недавно мы рассказывали, что такое PySpark. Сегодня рассмотрим, как подключить PySpark в Google Colab, а также как скачать датасет из Kaggle прямо в Google Colab, без непосредственной загрузки программ и датасетов на локальный компьютер. Google Colab Google Colab — выполняемый документ, который позволяет писать, запускать и делиться своим Python-кодом через...

В этой статье мы рассмотрим, что такое Apache Zeppelin, как он полезен для интерактивной аналитики и визуализации больших данных (Big Data), а также чем этот инструмент отличается от популярного среди Data Scientist’ов и Python-разработчиков Jupyter Notebook. Что такое Apache Zeppelin и чем он полезен Data Scientist’у Начнем с определения: Apache...
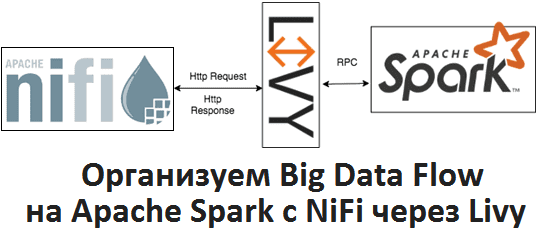
Apache Livy полезен не только при организации конвейеров обработки больших данных (Big Data pipelines) на Spark и Airflow, о чем мы рассказывали здесь. Сегодня рассмотрим, как организовать запланированный запуск пакетных Spark-заданий из Apache NiFi через REST-API Livy, с какими проблемами можно при этом столкнуться и что поможет их решить. Что...

Продолжая разговор про Apache Livy, сегодня мы сравним этот REST API для Spark c другой популярной Big Data системой планирования рабочих процессов для управления заданиями Hadoop – Oozie. Читайте в нашей статье, что такое Apache Oozie, чем он похож на Livy и в чем между ними разница, а также когда...
Вчера мы рассказывали про особенности совместного использования Apache Spark с Airflow и достоинства подключения Apache Livy к этой комбинации популярных Big Data фреймворков. Сегодня рассмотрим подробнее, как работает Apache Livy, а также за счет чего этот гибкий API обеспечивает удобство работы с Python-кодом и общие Spark Context’ы для разных операторов...

Сегодня поговорим про построение конвейеров обработки данных (data pipeline) на примере совместного использования Apache Spark с Airflow и рассмотрим типовые проблемы этой комбинации. Читайте в нашей статье, как автоматизировать задачи пакетной и потоковой обработки больших данных (Big Data) с помощью гибкого REST-API Apache Livy, включая работу с Python-кодом, отказоустойчивость и...

Python считается из основных языков программирования в областях Data Science и Big Data, поэтому не удивительно, что Apache Spark предлагает интерфейс и для него. Data Scientist’ы, которые знают Python, могут запросто производить параллельные вычисления с PySpark. Читайте в нашей статье об инициализации Spark-приложения в Python, различии между Pandas и PySpark,...

Вчера мы говорили про наиболее перспективные технологии 2020 с точки зрения исследовательского агентства Gartner и их влияние на цифровую трансформацию. Сегодня продолжим разбирать современные тенденции изменения рабочего пространства с учетом эпидемиологической напряженности и тренда на дистанционное взаимодействие. Читайте далее, что такое Desktop as a Service, как выглядит интеллектуальное рабочее пространство,...

Постоянно обновляя наши курсы «Аналитика больших данных для руководителей» в соответствии с развитием области Big Data и вызовов современного бизнеса, сегодня мы расскажем про наиболее перспективные технологии с точки зрения исследовательского агентства Gartner, а также рассмотрим их влияние на цифровую трансформацию. Читайте в нашей статье, почему цифровой двойник нужен не...