
Продолжая рассказывать про наш новый курс «Greenplum для инженеров данных», сегодня рассмотрим некоторые особенности хранения данных в этой MPP-СУБД, а также разберем связанные с ними лучшие практики ее администрирования. Читайте далее про важность RAID-массивов, механизмы дублирования кластеров, утилиты резервного копирования и восстановления данных в Greenplum. RAID-массивы и зеркалирование жестких дисков...

Один из факторов повышенной надежности Apache Kafka обеспечивается записью сообщений на жесткий диск. Однако, операции ввода-вывода (IO, input-output) с дисковым пространством считаются медленными и часто являются узким местом во всей системе. Спустившись на уровень операционной системы и ядра, сегодня рассмотрим, как Kafka справляется с этим ограничением, позволяя быстро обрабатывать огромные...
Совмещение Airflow с Kubernetes уже становится стандартом де-факто для дата-инженеров. Недавно мы рассказывали про 3 популярные среды развертывания и сопровождения этого ETL-фреймворка в Kubernetes. Продолжая эту тему, сегодня рассмотрим, какие операторы использовать для контейнерного запуска batch-задач, а также поговорим о том, как Docker-образы помогут решить проблему изменения версий Python и...
В этой статье рассмотрим особенности подключения Apache Spark к внешним СУБД как к источникам данных для аналитики Big Data средствами SQL-модуля этого фреймворка. Читайте далее о том, что такое JDBC-драйвер, чем источник данных JDBC отличается от сервера Spark SQL JDBC, при чем здесь RPC-фреймворк и язык описания интерфейсов Thrift, а...

Сегодня разберем еще одну интересную тему из нашего нового курса «Greenplum для инженеров данных» по построению конвейеров приема данных для этой MPP-СУБД в рамках веб-интерфейса платформы автоматизированного управления потоками работ Apache NiFi. Читайте далее, как устроен коннектор VMware Tanzu Greenplum для Apache NiFi и какие возможности он предоставляет дата-инженеру. Что...

Партиционирование таблиц – надежный способ повышения производительности Greenplum, который тесно связан с особенностями распределения данных по сегментам кластера. Читайте далее, чем опасно неравномерное распределение данных и вычислений по узлам, а также как найти дата-инженеру и устранить эти перекосы в MPP-СУБД, чтобы повысить скорость выполнения SQL-запросов и решить проблемы с нехваткой...
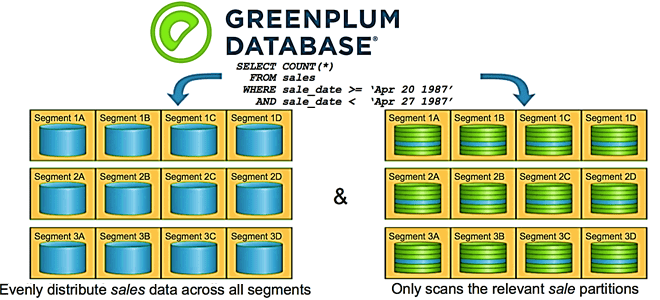
Мы уже рассказывали про основы хранения и аналитики больших данных в Greenplum, а также рассматривали особенности индексации и сжатия данных в этой MPP-СУБД. Продолжая разговор о нашем новом курсе «Greenplum для инженеров данных», сегодня разберем лучшие практики разбиения данных на разделы и пример их распределения по сегментам кластера. Кратко о...

В продолжение вчерашней статьи по нашему новому курсу «Greenplum для инженеров данных», сегодня рассмотрим особенности индексации и сжатия данных в этой MPP-СУБД. Читайте далее, почему в Greenplum можно обойтись без индексов, когда выбирать RLE-сжатие вместо zlib, зачем сжимать рабочие файлы при выполнении SQL-запросов и что такое селективность индекса. ТОП-10 советов по...

Продвигая наш новый курс «Greenplum для инженеров данных», сегодня мы рассмотрим особенности организации таблиц в этой MPP-СУБД, типы данных и оптимальное расположение столбцов. Читайте далее, чем heap storage отличается от append-optimized, когда выбирать колоночную, а когда – строковую модель хранения данных для таблицы, почему BIGINT с TIMESTAMP следует размещать перед...

В этой статье разберем одну из тем практического обучения администраторов Apache Kafka и рассмотрим разницу между сохранением сообщений и фиксированных смещений в этой Big Data платформе потоковой обработке событий. Читайте далее про конфигурации потребителя и брокера, отвечающие за время хранения сообщений и политику очистки журналов. Еще раз про offset или...

Сегодня рассмотрим Apache Spark с точки зрения Data Science специалиста: поговорим про сходства и отличия библиотек машинного обучения в этом фреймворке. Также ответим на вопрос «Spark ML vs MLLib», разберем, зачем Data Scientist’у и аналитику больших данных нужны курсы по Apache Spark, а в заключение отметим наиболее важные улучшения библиотеки...

Продолжая разбирать особенности бакетирования таблиц в Apache Spark, сегодня мы рассмотрим несколько примеров, как дата-инженер и аналитик данных могут работать с этим методом оптимизации SQL-запросов. Также читайте далее, какие конфигурации Apache Spark SQL связаны с бакетированием таблиц и что нового появилось в 3-ей версии этого Big Data фреймворка, чтобы такой...
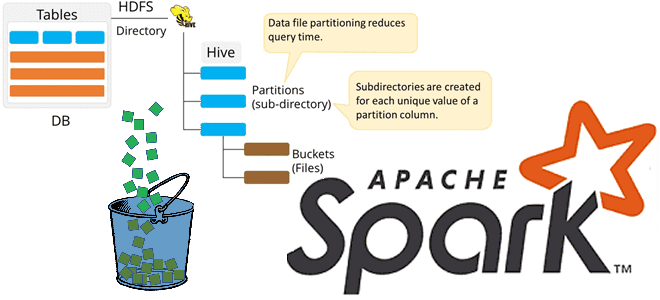
Бакетирование таблиц в Apache Spark – один из самых популярных методов оптимизации производительности задач последовательного чтения данных. Сегодня поговорим про сложности бакетирования с точки зрения дата-инженера, а также рассмотрим факторы, от которых зависит оптимальное количество бакетов. Большая проблема маленьких файлов и бакетирование таблиц в Apache Spark Напомним, бакетирование ускоряет выполнение...

В рамках обучения аналитиков Big Data и разработчиков Apache Spark и Kafka, сегодня рассмотрим кейс ИТ-компании Southworks по онлайн-обработке потокового видео как наглядный пример эффективного сочетания этих потоковых фреймворков с пакетными задачами. Читайте далее, как реализовать лямбда-архитектуру масштабируемой Big Data системы на базе Apache Kafka, Spark Structured Streaming и NoSQL-СУБД...

Для практического использования Apache Airflow в production дата-инженеру необходимо не только обучение основам работы с этим фреймворком, но и знания о базовой инфраструктуре его развертывания. Поэтому сегодня поговорим о 3-х популярных средах для развертывания и сопровождения этого ETL-фреймворка: Astronomer, Google Cloud Composer и Amazon Managed Workflows, разобрав их основные возможности...

Вчера мы говорили про важные обновления Apache Kafka 2.8.0, помимо долгожданного KIP-500, который позволяет избавиться от Zookeeper для синхронизации метаданных в распределенном кластере с помощью встроенного Quorum Controller. Сегодня рассмотрим, какие KIP’ы нового релиза коснулись одного из основных инструментов разработчика Apache Kafka – библиотеки Streams для создания распределенных приложений потоковой...

KIP-500, который позволяет наконец-то избавиться от Zookeeper в кластере Apache Kafka, заменив его Quorum Controller – далеко не единственное важное обновление в релизе 2.8.0. Сегодня рассмотрим, какие еще улучшения реализованы в новой версии главной Big Data платформы потоковой обработки событий, выпущенной в апреле 2021 года. Apache Kafka 2.8.0: новинки главных...
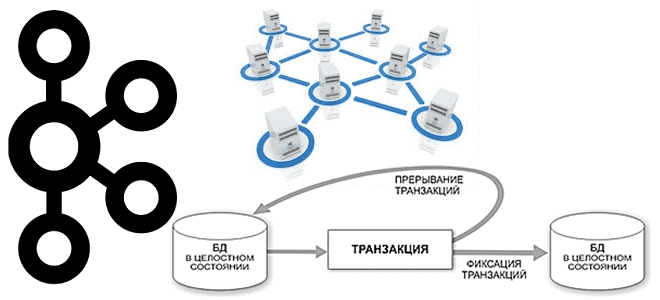
Продолжая говорить про обучение разработчиков и администраторов Apache Kafka, сегодня разберем сложности семантики строго однократной доставки сообщений (exactly once) в случае нескольких экземплярах, находящихся в разных кластерах. Читайте далее, что не так с межкластерными транзакциями, какие KIP’ы связаны с этой проблемой и при чем здесь MirrorMaker. Что не так с...

Развивая наши курсы по Apache Spark, сегодня мы рассмотрим несколько особенностей, с разработчик которыми может столкнуться при выполнении обычных операции, от чтения архивированного файла до обращения к сервисам Amazon. Читайте далее, что не так с методом getDefaultExtension(), зачем к AWS S3 так много коннекторов и почему PySpark нужно дополнительно конфигурировать...
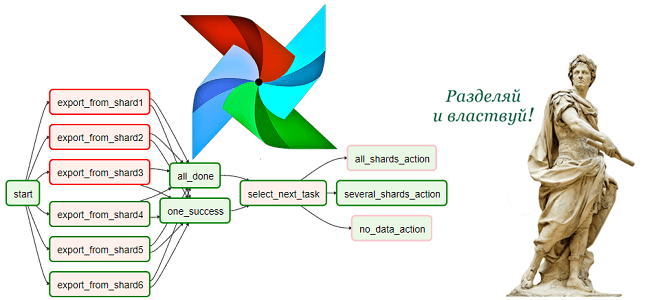
Чтобы сделать обучение дата-инженеров еще более полезным, сегодня мы рассмотрим проблему управления взаимозависимыми цепочками задач в Apache AirFlow. Читайте далее, как бразильская ИТ-компания QuintoAndar разработала промежуточный компонент Mediator на базе одноименного шаблона архитектурного проектирования ПО, чтобы облегчить взаимодействие между разными DAG’ами в конвейерах обработки больших данных. Проблема взаимозависимых DAG’ов в...