
Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...
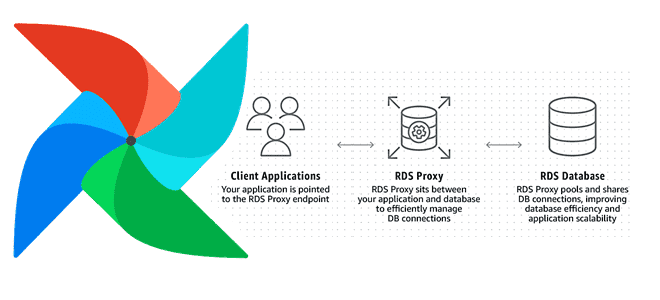
Увеличение пропускной способности и повышение скорости обработки данных на любой Big Data платформе при приемлемых затратах – одна из главных задач дата-инженера. Сегодня мы рассмотрим, как улучшить производительность множества экземпляров Apache AirFlow с помощью прокси-сервера Amazon RDS и сколько это стоит в денежном выражении: кейс компании Datafy. Больше не значит...

Apache Spark + AirFlow – известная каждому дата-инженеру комбинация технологий Big Data для запуска сложных конвейеров обработки данных. Но совместное использование этих фреймворков ограничено недостатками AirFlow, часть из которых можно обойти с помощью Apache Livy. Однако эксплуатация AirFlow менее удобна, чем Dagster. Поэтому сегодня рассмотрим, как этот альтернативный оркестратор данных...
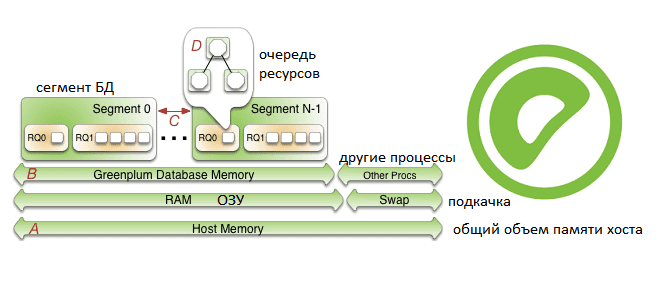
Продолжая рассказывать про наш новый курс «Greenplum для инженеров данных», сегодня поговорим про особенности конфигурирования памяти в этой MPP-СУБД: разберем, как память хоста распределяется между сегментами и рассмотрим, как администратор кластера может ускорить работу этой базы данных. Также читайте далее о связи RAM с настройками ядра операционной системы и схемами...

Apache AirFlow – это не только инструмент планирования batch-процессов, но и средство мониторинга ETL-задач и конвейеров обработки данных. Однако, наблюдать за выполнением data pipeline’а в веб-интерфейсе этого фреймворка не всегда удобно. Читайте далее, с какими проблемами AirFlow сталкиваются дата-инженеры и как альтернативный оркестратор Dagster позволяет решить их. Проблемы мониторинга data...
Чтобы сделать обучение разработчиков Apache Spark, дата-аналитиков и инженеров Big Data еще более наглядным, сегодня рассмотрим проблему JOIN-соединений при неравномерном распределении данных по узлам кластера и способы ее решения. Читайте далее, как избавиться от перекосов и ускорить выполнение SQL-запросов в Spark-приложениях. Перекосы данных в Apache Spark: что это и чем...

Вчера мы рассказывали, почему некоторые OOM-ошибки stateful-приложений Kafka Streams могут быть вызваны некорректной работой RocksDB – встроенного key-value NoSQL-хранилище состояний. Сегодня рассмотрим, какие проблемы с дисковыми операциями характерны для этой СУБД, как они отражаются на Kafka-приложениях потоковой аналитики больших данных и каким образом можно это исправить. Быстрые диски, RocksDB и...

Сегодня заглянем под капот stateful-приложений Kafka Streams и рассмотрим, что такое RocksDB, как устроено это key-value NoSQL-хранилище и почему его необходимо настраивать для быстрой и безотказной работы приложений потоковой аналитики больших данных. Читайте далее, какие проблемы приложений Kafka Streams связаны с RocksDB и как ограничить повышенное потребление оперативной памяти. Что...

Cегодня рассмотрим некоторые инструменты защиты данных в Greenplum. Читайте далее про особенности шифрования в этой MPP-СУБД и лучшие практики обеспечения информационной безопасности и защиты в этой системе хранения и аналитики больших данных. Администраторы и суперпользователи Greenplum Для надежной защиты данных, хранящихся в MPP-СУБД Greenplum, и обеспечения информационной безопасности кластера рекомендуется...

Продолжая сравнивать Apache AirFlow с Dagster, сегодня рассмотрим особенности развертывания и эксплуатации этих оркестраторов ETL-процессов и конвейеров обработки данных. Читайте далее о плюсах изоляции процессов, отделения системных служб от пользовательского кода, сложностях планирования и запуска задач, а также способах их решения с помощью современных инструментов дата-инженера. В изолятор: как развернуть...

Продолжая добавлять в наши практические курсы по Apache Kafka и Spark еще больше интересных примеров, сегодня рассмотрим, как с помощью этих технологий Big Data анализировать метаданные сетевых потоков в реальном времени. В этой статье мы приготовили для вас кейс по потоковой аналитики больших данных о сетевом трафике с помощью Apache...

Apache AirFlow – один из самых популярных инструментов современного дата-инженера для планирования и оркестрации batch-процессов. Повторить успех этого фреймворка стремятся многие компании и Big Data энтузиасты: недавно мы рассказывали про ViewFlow от DataCamp, а также писали про Luigi, Argo, MLFlow и KubeFlow. Сегодня рассмотрим Dagster – еще одну альтернативу Apache...
Сегодня поговорим про обработку геопространственных данных с Apache Spark и рассмотрим, что такое Apache Sedona, как этот фреймворк связан с GeoSpark, какие форматы и структуры данных он поддерживает. Читайте далее про пространственные RDD, Spatial SQL-запросы и построение конвейеров обработки геоданных в облачных сервисах Amazon. Как обработать геопространственные данные в...
28 мая 2021 года Арбитражный суд г. Москвы удовлетворил затяжной иск ООО "Учебный центр "Коммерсант", в составе которого находится наша Школа Больших Данных, к АНО ДПО "Учебный центр "Микроинформ" о нарушении исключительных прав на тексты программ учебных курсов: BDAM: Аналитика больших данных для руководителей; SPARK: Анализ данных с Apache Spark;...

В прошлый раз мы говорили про особенности работы с пользовательскими функциями (UDF) в Hive. Сегодня поговорим про основные SQL-операции в распределенной Big Data платформе Apache Hive. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД. Читайте далее про CRUD-операции в Hive и их особенности. CRUD-операции в СУБД Apache...

Развивая наш новый курс «Greenplum для инженеров данных», сегодня рассмотрим, почему в этой MPP-СУБД возникают проблемы нехватки памяти, каковы типовые способы их решения и чем очереди ресурсов отличаются от ресурсных групп. Читайте далее про схемы управления ресурсами в Greenplum и особенности параметра конфигурации statement_mem. Очереди vs Группы: 2 схемы управления...

Чтобы добавить в наши практические курсы по Apache Kafka еще больше интересных примеров, сегодня рассмотрим кейс немецкой ИТ-компании Mobimeo, которая несколько раз перекраивала свою систему аналитики больших данных, чтобы быстро узнавать о событиях клиентских приложений. Читайте далее, зачем дата-инженеры Mobimeo предпочли AVRO формату JSON, почему вместо брокера сообщений ActiveMQ решили...
В этой статье поговорим про Viewflow: что такое, как устроено, чем полезно аналитикам данных и Data Scientist’ам. Встречайте новый фреймворк на базе Apache AirFlow от DataCamp – американского edu-стартапа в области ИИ, который упрощает создание и управление материализованными представлениями на SQL, R и Python в концепции low code, т.е. практически...

Сегодня рассмотрим инструмент, который облегчает практическое использование Apache Spark, позволяя дата-аналитику и разработчику распределенных приложений быстро писать и выполнять SQL-запросы в рамках удобного веб-редактора. Читайте далее, что такое Hue, как он связан со Spark SQL и Hive, а также причем здесь Livy. Что Hue и при чем здесь Apache Livy...

Чтобы самостоятельное обучение по Impala стало еще интереснее, сегодня мы предлагаем вам простой тест по основам работы с механизмом представлений, включая их структуру и особенности. Тест по основам работы с представлениями Impala для новичков Для начинающих самостоятельное обучение по Apache Impala мы предлагаем простой интерактивный тест по этой Big Data...