
Анализ данных в рамках пользовательский сеансов (сессий) – довольно востребованный кейс в Apache Spark, который не так просто реализовать из-за особенностей потоковой и пакетной обработки, а также эксплуатационных расходов. Сегодня рассмотрим, как работают сеансовые окна Spark Structured Streaming и каковы ограничения этого фреймворка. Что такое сеансовые окна: краткий ликбез по...

В этой статье для разработчиков Apache Kafka рассмотрим пример масштабирования потоковой обработки событий с Akka Streams. Читайте далее, что не так с параллелизмом при одновременном выполнении событий на запись, как Akka Streams решает эту проблему и при чем здесь Apache Kafka. Проблемы масштабирования потоковой обработки в Kafka Streams Масштабная потоковая...

На протяжении всей истории человечества пандемии являлись причинами глобальных макроэкономических изменений. Например, эпидемия чумы привела к окончательному падению монгольской империи, изменив баланс сил между мусульманским и европейским миром в пользу последнего. А эпидемия испанки, разразившаяся в конце первой мировой войны, привела к окончательной капитуляции Германии. Последняя пандемия COVID-19 изменила мир...
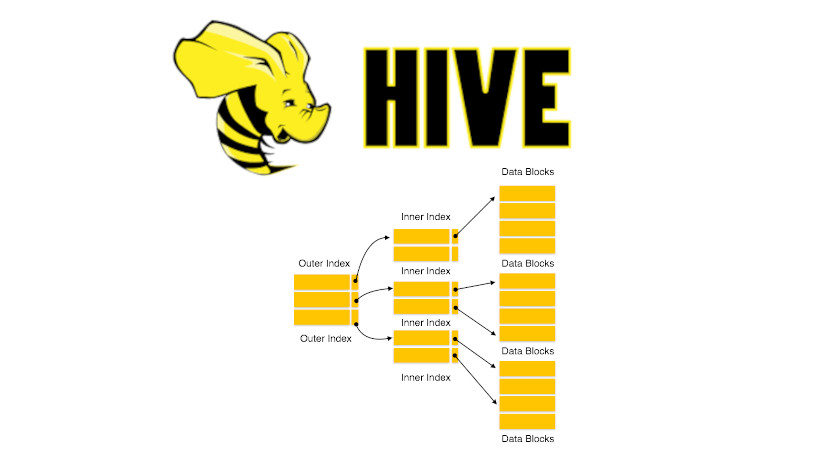
В прошлый раз мы говорили про драйвер JDBC и его использование в Hive. Сегодня поговорим про особенности создания и работы индекса в распределенной Big Data платформе Apache Hive. Читайте далее про особенности работы с индексами в распределенной среде Big Data СУБД Hive. Какую роль играет использование индекса при обработке Big...

Чтобы добавить в наши курсы для дата-инженеров по технологиям Apache Kafka, Spark, AirFlow, NiFi, Flink и Greenplum, еще больше практических примеров, сегодня разберем кейс ритейлера Леруа Мерлен. Читайте далее, как сотрудники российского отделения этой международной компании интегрировали в единую платформу более 350 реляционных СУБД и NoSQL-источников с помощью CDC-подхода на...
В рамках продвижения нашего нового курса по графовым алгоритмам на больших данных, сегодня разберем, что такое Pregel, и как API этой платформы реализован в Apache Spark GraphX. Читайте далее, как из RDD вершин и ребер образуется триплет, а также какие механизмы отвечают за отказоустойчивость графовой аналитики больших данных. Что такое...
Сегодня рассмотрим пример построения интеллектуальными конвейера потоковой обработки видео с Apache Kafka и алгоритмами машинного обучения. Читайте далее, зачем для этого нужен протокол RTSP, что такое библиотека Sarama и как интегрировать алгоритмы машинного/глубокого обучения в систему видеоаналитики реального времени. Потоковая видеоаналитика: прием мультимедиа в реальном времени Видеоаналитика – одно из...
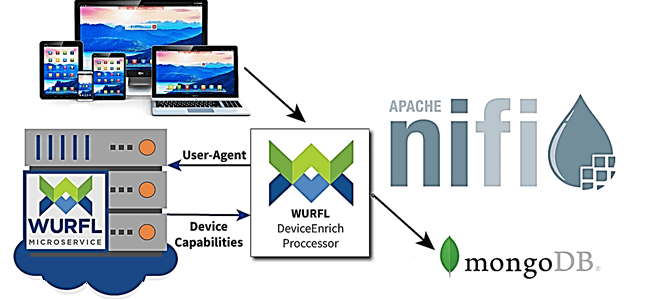
Развивая наши курсы по Apache NiFi для дата-инженеров и администраторов, сегодня рассмотрим, как как обогатить поток данных, сделав информацию об устройстве доступной для систем, которые хранят или потребляют данные в следующих этапах конвейера. Также разберем, зачем нужна технология детектирования устройств, что такое WURFL и как это реализовать в Apache NiFi....

В этой статье для дата-инженеров рассмотрим кейс компании PayPal, которая переводит свои аналитические рабочие нагрузки из локального кластера Apache Spark в Google Cloud Processing. Читайте далее, чем это решение оказалось лучше выполнения Spark-заданий в кластере DataProc с использованием данных BigQuery и облачного хранилища Google (GCS, Google Cloud Storage) для потоковой...

Сегодня рассмотрим пару кейсов по использованию Apache Flink в качестве основного фреймворка пакетной и потоковой аналитики больших данных. Читайте далее, как фото-хостинг Pinterest построил вокруг Flink собственную инфраструктуру работы с изображениями в реальном времени, а китайский ритейл-гигант Alibaba Group успешно обрабатывал 7 ТБ в секунду во время глобального дня шопинга....

Продвигая наш новый курс по графовым алгоритмам на больших данных, сегодня рассмотрим, почему концепция графов сегодня так востребована в Big Data и Machine Learning. Вас ждет краткий ликбез по модулю GraphX в Apache Spark и его отличия от API GraphFrames, а также особенности кластерной обработки и сохранения данных графа свойств....
Появившись более 10 лет назад, Apache Hive до сих пор является самым популярным инструментом стека SQL-on-Hadoop и активно используется для аналитики больших данных. Однако, технологии Big Data постоянно развиваются: Spark все чаще заменяет Hadoop MapReduce, а вместо HDFS все чаще используются объектные облачные хранилища: AWS S3, Delta Lake, Apache Ozone...

Продвигая наши курсы по Greenplum и Arenadata DB, сегодня рассмотрим пару полезных лайфхаков, как избежать избыточного потребления памяти, настроив конфигурационные параметры операционной системы хоста. Читайте далее, почему не стоит задавать слишком большой размер страниц виртуальной памяти, зачем администратору контролировать количество spill-файлов и как в этом помогает утилита gp_toolkit. Операционная система...

Недавно мы рассказывали про KafkaJS – клиент Apache Kafka для Node.js, который отличается небольшим размером и простым развертыванием с удобным API. Сегодня рассмотрим еще пару полезных инструментов визуализации данных о Kafka-кластере на базе KafkaJS и Prometheus. Читайте далее, что такое FlowKat и Monokl, а также зачем они нужны дата-инженеру, разработчику...
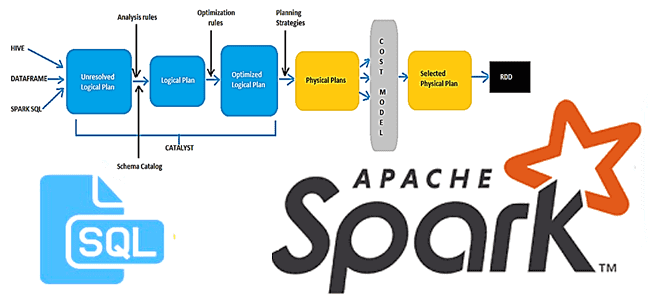
В этой статье для разработчиков Spark-приложений и дата-аналитиков рассмотрим новый оптимизатор этого фреймворка, Radiant. Он основан на SQL-оптимизаторе Catalyst и представляет собой open-source проект от энтузиастов сообщества Apache Spark. Читайте далее, чем хорош Spark-Radiant и как использовать его для оптимизации SQL-запросов при аналитике больших данных. Что такое SQL-оптимизатор Spark-Radiant и...
В рамках обучения дата-инженеров сегодня заглянем под капот системы Cloudera Flow Management, которая является частью платформы Cloudera DataFlow и основана на Apache NiFi. Вас ждет разбор основных концепций жизненного цикла потоковой разработки и их реализация в Apache NiFi с практическими примерами и рекомендациями по применению. Что такое Cloudera Flow Management...

Когда имеются графы (dags), зависимые от других, то лучше всего объединить их в один или использовать TaskGroup, о котором говорили в прошлой статье. Но если по каким-то причинам сделать это не удается, то Apache Airflow предоставляет различные способы запуска графа внутри другого. Одним из таких является TriggerDagRunOperator. В этой статье...
Сегодня рассмотрим, что такое KafkaJS, как это связано с Apache Kafka и JavaScript, в чем преимущества этой технологии и как разработчику распределенных приложений потоковой аналитики больших данных использовать ее на практике. Также вас ждет краткий ликбез по Node.js и примеры разработки KafkaJS-приложения. Краткий ликбез по Node.js Важными достоинствами архитектуры потоковой передачи...

При том, что Apache Airflow сегодня считается главным инструментом дата-инженерии, он далеко не единственное средство оркестрации пакетных заданий и построения конвейеров обработки больших данных. В рамках продвижения наших курсов для инженеров Big Data, сегодня рассмотрим, что такое Apache Hop, чем это отличается от AirFlow и где использовать эту платформу, а...

Хотя наши практические курсы по Greenplum и Arenadata DB больше ориентированы на аналитиков и дата-инженеров, чем на администраторов, в программы обучения также включены важные сведения по настройке этих MPP-СУБД. В этой статье мы собрали лучшие практики системного конфигурирования кластера Greenplum, которые помогут повысить эффективность аналитики больших данных в этой Big...